

Logging in databases refers to the process of keeping every minor update of database activity in terms of messages. These log messages or log files are essential when the system fails to recover. Debezium is an open-sourced distributed system used to keep track of real-time changes on databases.
It has a separate connector for separate databases like PostgreSQL, MySQL, SQL, Oracle, etc. Thus, the logging process is initiated when one such connector is connected to databases. The connector produces valuable information when it is connected to the database, and this information is then stored in terms of messages called log messages.
Debezium allows users to change the configuration of the logging system and loggers to generate many log messages, enabling the diagnosis of connector failures.
Table of Contents
Prerequisites
- Basics of Debezium connectors.
What is Debezium?

Debezium is an open-sourced event streaming platform that keeps track of every real-time change in databases. It uses different connectors of databases like MySQL, SQL, Oracle, PostgreSQL, etc. When the Debezium connectors are connected to databases, you can track all changes on databases and send them to Kafka topic. These changes are then accessed by different applications for further processing-dependent tasks.
Debezium follows the Change Data Capture approach used to replicate data between databases in real-time. Other ways to approach CDC are Postgre Audit Triggers, Postgre Logical Decoding, and Timestamp column. In the Postgre Audit Trigger-based method, the databases create the triggers to capture events related to insert, update and delete methods.
But the disadvantage of this method is that it affects the performance of the database. However, the Postgre Logical Decoding method uses the write-ahead log to maintain the log of activities occurring in databases.
Write ahead log is the internal log that describes the database changes on storage level. This method, in contrast, increases the complexity of the databases by writing logs. And the Timestamp column needs to query the table and monitor the changes accordingly.
This method would require the user’s time and effort to create the query and track the changes. Therefore, Debezium is used as an alternative to all the above approaches, which is a distributed platform and is fast so that applications can respond to data changes quickly.
What is Debezium Logging?
All the databases consist of logs that record the database changes. In case of system failures, logs are needed to restore and recover the system. Logging refers to the process of keeping logs. Similarly, Debezium consists of extensive logging into its connectors.
Users can change the logging configuration in Debezium to control access to the log statements. Usually, connectors produce few logs when they are connected to the source databases. These logs are adequate when the connector operates but might not be sufficient when connectors stop. In such scenarios, you can change the logging levels to produce more logs.
Hevo Data, a No-code Data Pipeline helps to load data from any data source such as Databases, SaaS applications, Cloud Storage, SDK,s, and Streaming Services and simplifies the ETL process. It supports 150+ data sources (including 60+ free data sources) and is a 3-step process by just selecting the data source, providing valid credentials, and choosing the destination.
Why Hevo + Debezium?
- Reliability at Scale: Hevo ensures end-to-end data integrity, even with high throughput and complex transformations.
- No-Code Interface: Set up CDC pipelines without writing code.
- Unified Logging: Get insights into real-time changes directly from database logs, supported by Hevo’s intuitive monitoring.
- Broad Compatibility: Work with multiple databases like MySQL, PostgreSQL, and MongoDB seamlessly.
Understanding Debezium Logging Concepts
Here are the key Debezium Logging Concepts to keep in mind:
Debezium Logging Concepts: Loggers
Applications produce log messages arranged in hierarchies and send them to specific loggers. The root logger resides at the top of the hierarchy, defining the default logger configuration. For eg. io.debezium is the root logger whose child is io.debezium.connector.
Log Levels
Every produced log message has specific log levels as follows.
- ERROR: It specifies errors, exceptions, or other issues.
- WARN: It specifies potential problems.
- INFO: It specifies the status and low volume information.
- DEBUG: It specifies detailed activity, which helps detect unexpected behavior or failure.
- TRACE: It specifies very detailed and high-volume activity.
Appenders
Appender is a destination where all the log messages are written and is used to control the format of the log messages. For the configuration of logging, you need to specify the desired level of each logger and the appender. Since the loggers are hierarchical, the configuration of the root logger serves as a default for all the loggers below it.
Methods to Modify Debezium Logging Configuration
Kafka Connect uses the log4j configuration file to run Debezium connectors in a Kafka Connect process for default logger configuration. By default, the log4j consists of the following configuration.

From above, there is a root logger that decides the default configuration. It has ERROR, WARN, INFO messages and is written to the stdout appender.
The stdout appender writes the log messages to the console and uses the pattern matching algorithm to format the log messages.
You can change the configuration of the Debezium connectors in the following ways:
Debezium Logging Configuration Modification: Change the Logging Level
The default logging level provides sufficient information to detect whether the connector is healthy or not. If the connector is not healthy, you can change the logging level to detect the issue.
Debezium connectors send their log messages to the loggers with names that match the fully qualified name of the java class generating the log message. In Debezium, codes or functions are organized by using packages. Therefore, you can control all the log messages of one class or all the classes under the same package.
The steps for changing the logging levels are as follows.
- Step 1: Open the log4j.properties file.
- Step 2: Configure the logger for the connectors. In this tutorial, you use a MySQL database connector.
The log4j.properties file consists of the following configuration.
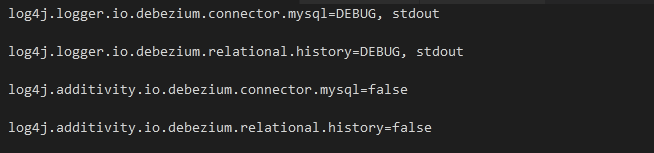
From above, the logger named io.debezium.connector.mysql is configured and sends the DEBUG, INFO, WARN and ERROR messages to the stdout appender.
The second logger named io.debezium.relational.history consists of database history and sends the DEBUG, INFO, WARN and ERROR messages to the stdout appender.
From above, the 3rd and the 4th line consists of turn-off additivity, meaning you cannot send the log messages to the appenders of the parent loggers.
- Step 3: You can change the logging level of the specific subset of classes if necessary.
If you increase the log level in the connector, it increases the number of words in the messages, which can lead to confusion. You can change the logging level for the particular subset of classes where such confusion needs to be detected.
You can use the below steps to change the level of logging.
- Step 1: You can set the logging level to DEBUG or TRACE.
- Step 2: Review the log messages.
- Step 3: You can find the log messages related to the associated issue. The name of the Java class that produced the message is shown at the end of every log message.
- Step 4: Set the connector’s logging level to INFO.
- Step 5: For each Java class identified, you need to configure the logger.
For example, consider a MySQL connector is skipping some events when processing the binlog. Instead of setting the logging level to DEBUG or TRACE, you can set it to INFO and then configure DEBUG or TRACE just for the class, which reads the binlog as follows.

Debezium Logging Configuration Modification: Mapped Diagnostic Contexts
To perform different activities, Kafka Workers and Debezium use multiple threads. Due to threads, it becomes difficult to search for a particular log message of a specific file. Debezium has several mapped diagnostic contexts that provide additional information about the threads to find the log messages easily.
Debezium provides the following mapped diagnostic contexts properties.
- dbz.connectorType: It is a short name given to connectors like MySql, Mongo, Postgre, and more to find log messages produced by them. You can check the thread associated with the same type of connector.
- dbz.connectorName: In the connector configuration, the name of the connector or the database server is defined. To find the log messages produced by a specific connector instance, you can check all the threads associated with a particular connector instance with the same values.
- dbz.connectorContext: It is a short name for the activities running as a separate thread in the connector’s task. When a connector assigns some threads to the resource, the name of that resource is used instead of the thread. Each thread uses a distinct value when connected to the connector. Therefore, you can find all the log messages with these activities.
To enable Mapped diagnostic context for the connector, you should configure the appender in log4j.properties file.
Steps to enable Mapped diagnostic context.
- Step 1: Open the log4j.properties file.
- Step 2: Use any appender supported by the Debezium to enable Mapped diagnostic context properties.
In the below example, stdout appender is used.

It produces the below log messages.

Every message from adobe includes the connector type, the connector’s name, and the thread’s activity.
Conclusion
In this tutorial, you have learned about key concepts and configurations needed for Debezium logging. Debezium logging is necessary when the connector goes down or stops to increase the logging level, generating more log messages. You can also use Kafka Connect loggers to configure Debezium loggers and logging levels.
Companies need to analyze their business data stored in multiple data sources. The data needs to be loaded to the Data Warehouse to get a holistic view of the data. Hevo Data is a No-code Data Pipeline solution that helps to transfer data from 150+ sources to desired Data Warehouse.
It fully automates the process of transforming and transferring data to a destination without writing a single line of code. Hevo helps simplify ETL and Data Streaming for your business requirements.
Want to take Hevo for a spin? Sign Up or a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also checkout our unbeatable pricing to choose the best plan for your organization.
Share your experience of learning about Debezium SQL Server Integration in the comments section below!
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



