




As businesses increasingly rely on data to drive critical decisions and operations, ensuring data consistency and reliability across different systems has become paramount. In the world of modern data architectures, where data flows through multiple sources and targets, managing and replicating data changes can be a complex and challenging task. This is where Debezium comes into play, offering a powerful and elegant solution for capturing data changes from various databases and streaming them to diverse targets.
Debezium is an open-source distributed platform for change data capture (CDC). It revolutionizes the way organizations handle data replication, enabling them to capture and stream data changes from databases such as MySQL, PostgreSQL, MongoDB, and others, in real-time. With its innovative approach, Debezium streamlines the process of propagating data changes to downstream systems, facilitating seamless data integration, synchronization, and analysis.
In this comprehensive guide, we’ll delve into the world of Debezium, exploring what is Debezium, its core concepts, architecture, and powerful features. Let’s dive in!
Table of Contents
What is Debezium?

Debezium is a distributed platform for CDC that streams database changes as events, enabling applications to detect and respond to data changes in real-time. Built on Apache Kafka, Debezium provides Kafka Connect connectors that capture row-level changes from various databases and publish them as event streams to Kafka topics.
Consuming applications can then consume these events, ensuring no data loss even during outages or disconnections. Debezium leverages Kafka’s reliable streaming capabilities, allowing applications to process database changes accurately and consistently.
Hevo ensures data consistency across your systems by providing a reliable and automated platform for data integration and transformation. It provides integrations from 150+ sources to destination databse/warehouse of your choice. Consistent data is crucial for accurate reporting, analysis, and decision-making.
Here’s how Hevo can be of help:
- Real-Time Data Synchronization: Updates data in real-time to reflect changes across all systems.
- Error Detection and Handling: Monitors pipelines for errors, providing alerts and automated corrections.
- Automated Data Transformation: Applies consistent rules for data cleaning, normalization, and enrichment.
Join our 2000+ happy customers like Thoughspot, and Hornblower and empower your data management with us.
Get Started with Hevo for FreeFeatures of Debezium
Debezium leverages Apache Kafka Connect source connectors for capturing changes from various databases using Change Data Capture (CDC) methods. The specific method employed depends on the capabilities of the source database. Debezium can utilize log-based CDC for databases with accessible transaction logs, offering high efficiency and minimal performance impact. However, it can also adapt to other methods like snapshotting or change data tables when necessary.
While frequent polling approaches like timestamp-based CDC or query-based CDC can potentially miss changes if data modifications occur between queries, Debezium’s focus on efficient methods like log-based CDC minimizes this risk. This allows organizations to react to data changes in near-real-time with minimal performance impact.
How Debezium Works?
Debezium monitors databases for row-level changes and streams these changes into Apache Kafka, which can then be consumed by applications in near real-time. Debezium connectors tap into the database’s transaction logs (binlog in MySQL, WAL in PostgreSQL, etc.) to capture the changes without impacting the database’s performance. It supports a variety of databases and allows for a wide range of use cases, such as updating search indexes, invalidating caches, or synchronizing data between microservices.
An ordinary Debezium pipeline would look like this:

Read: How to Set Up Kafka CDC for Efficient Data Replication?
What is the need for Debezium?
Debezium addresses the need of data consistency by providing a robust and efficient change data capture (CDC) solution. It enables organizations to capture and stream data changes from databases like MySQL, MongoDB (replica sets/sharded clusters), PostgreSQL, Oracle (LogMiner/XStream), Db2, Cassandra (3.x/4.x), and SQL Server, in real-time. This real-time data propagation allows for seamless data integration, synchronization, and analysis across various downstream systems, such as data lakes, streaming platforms, and caching layers.
Moreover, Debezium simplifies data replication processes, facilitating database migration, offloading read workloads, and maintaining high availability setups. It also supports event-driven architectures by providing a reliable source of data change events, enabling real-time processing and analysis.
Architecture of Debezium
Debezium is a robust change data capture (CDC) platform that harnesses the power of Kafka and Kafka Connect to deliver features such as durability, reliability, and fault tolerance. It operates by deploying connectors to Kafka Connect’s service, which is designed to be distributed, scalable, and fault-tolerant. These connectors are tasked with monitoring a designated upstream database server, capturing all changes and documenting them in Kafka topics, generally one per database table.
Part 1: Debezium Server
The Debezium standalone server is designed to capture changes in the source database. To accomplish this, it uses one of the Debezium source connectors as part of its configuration.
Part 2: Embedded Debezium
When deploying Debezium, Kafka Connect provides both scalability and fault tolerance. Nevertheless, there are instances where our applications do not require that degree of dependability, and we aim to reduce our infrastructure expenses.
Getting Started with Debezium
In this section, we will find an answer to the question “How To Use Debezium?”.
To start with Debezium, you need to install the latest version of Docker, an open-source platform that uses client-server technology to manage and deploy containerized applications. Let’s get started with the Debezium tutorial.
Debezium Services
To start the Debezium services, you need to start three unique services: ZooKeeper, Kafka, and Debezium connector services.
- ZooKeeper connector service
Apache ZooKeeper aims to build an open-source server that enables highly reliable distributed coordination. It is used for clusters in distributed systems to share group services like configuration information, naming, etc. Apache ZooKeeper is considered a centralized service and follows Master-Slave architecture.
- Kafka connector service
Kafka connectors are ready-to-use components and aim for scalable and reliable data streaming between Apache and other data systems. Kafka connector is a JDBC source connector that enables users to import data from the external systems to Kafka topics and export data from Kafka topics to external systems. Kafka topics are categories that are used to organize messages.
- Debezium connector service
Debezium is a collection of source connectors for Apache Kafka. Every connector in Debezium indicates the changes from different databases. It monitors specific database management systems that record the Kafka log’s data changes, a collection of data segments on the disk.
In this tutorial, you will use the Debezium and the Docker container images to set up the instance of each service.
1. Start ZooKeeper
To start the ZooKeeper with a container, use the following command.

Note: This command makes use of version 1.8 of the ZooKeeper.
Here:
- -it: It stands for interactive, which is used to attach to the container with the terminal’s input and output.
- -rm: It is used to remove the container when it gets stopped.
- –name: It is used to set the name of the container.
- -p 2181:2181 -p 2888:2888 -p 3888:3888: It ensures the containers and the application out of the container communicate with the ZooKeeper. It maps three container ports to the same port of Docker’s host.
To ensure that ZooKeeper started through port number 2181, you should get a similar output.
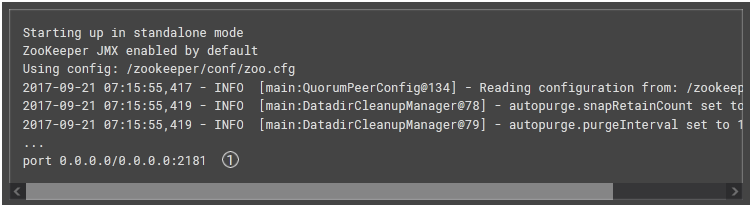
2. Start Kafka in the new container
To check the compatibility between Kafka and Debezium versions, you can go through the Debezium Test Matrix website. In this tutorial, Debezium 1.8.0 has been used along with Kafka Connect.
To start the Kafka in a container, open the terminal and run the following command.

This command makes use of the Debezium Kafka image of version 1.8 in a new container.
- –name Kafka: It is used to name the container.
- -p 9092:9092: It is used to communicate the applications outside the container to Kafka, port 9092 in the container is mapped to the same port on Docker’s host.
- –link zookeeper: It is used to tell the container to find ZooKeeper in the ZooKeeper container that is running in the same Docker host.
The above containers can connect with Kafka by linking them to Kafka. To connect Kafka from outside the Docker container, you use the -e option that specifies the Kafka address through Docker’s host. i.e. -e ADVERTISED_HOST_NAME=.
If you see the following output, your Kafka has started successfully.

3. Start a MySQL Database
Open a new terminal and use it to start a new container using the below command, which runs a MySQL database server with an inventory database.

The above command runs a new version 1.8 and is based on the MySQL 8.0 image. It has a sample inventory database. The sample inventory database is a centralized collection of data that stores all kinds of changes in databases.
- –name mysql: It is used to set the container’s name.
- -p 3306:3306: It communicates among applications outside the container to the database server. This command maps the port in the container to the same port of the Docker host.
- -e MYSQL_ROOT_PASSWORD=debezium -e MYSQL_USER=mysqluser -e MYSQL_PASSWORD=mysqlpw: It is used to create a new username and password for the Debezium MySQL connector.
If you see the following output, your MySQL server has started successfully.

4. Start MySQL command-line client
After starting the MySQL server, you need to start the MySQL command-line client to access the inventory database.
Open the new terminal and start a MySQL command-line client in the container.

- –name mysqlterm: it is the name of the container.
- –link mysql: it is used to link the container to MySQL container.
If you get the following output, the MySQL command-line client started successfully.
When you are into the MySQL command prompt, you need to access the inventory database.
Use the following command.
mysql> use inventory;
Look at the tables in the database.
mysql> show tables;
It shows:

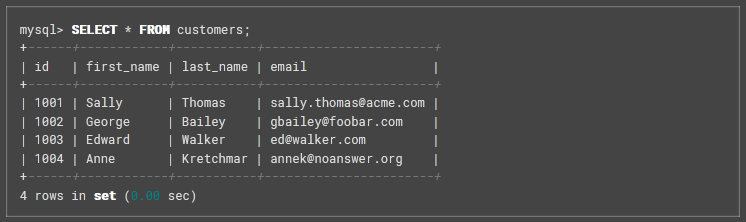
Use MySQL command to view the data in the database, i.e.:
Select * from customers;
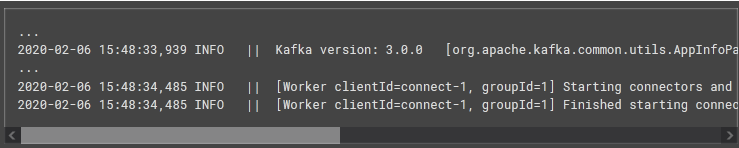
5. Kafka Connect
Start the Kafka Connect service after connecting MySQL to the inventory database through the
command-line client. The Kafka service consists of an API used to manage the Debezium connector.
Steps to Kafka connect:
- Open the terminal.
- Connect the Kafka Connect server in the container through the following command.

- –name connect: It is the name of the container.
- -p 8083:8083: It is used to ensure communication among the containers and the applications outside the containers by using Kafka Connect API. It maps the 8083 port in the container to the port of the Docker host.
- -e CONFIG_STORAGE_TOPIC=my_connect_configs -e OFFSET_STORAGE_TOPIC=my_connect_offsets -e STATUS_STORAGE_TOPIC=my_connect_statuse:It sets the environment variables needed by the Debezium image.
- –link zookeeper: zookeeper –link kafka:kafka –link mysql:mysql: It links this container to the already running containers: MySQL, ZooKeeper, and Kafka.
If you get the following output, your Kafka is running successfully.
Open a new terminal to check the status of Kafka connect.

To check the list of connectors registered with Kafka connect, you can use the below commands.

6. Deploy the MySQL connector
After starting the Debezium and MySQL services, you have to deploy the MySQL connector to monitor the inventory database. However, you have to register the MySQL connector to watch the inventory database.
After that, it will monitor MySQL’s server binlog, a binary log in a database that keeps track of all the operations in which they are committed to the database.
Steps:
- Open the terminal.
- Use the curl command below to register the Debezium MySQL connector.
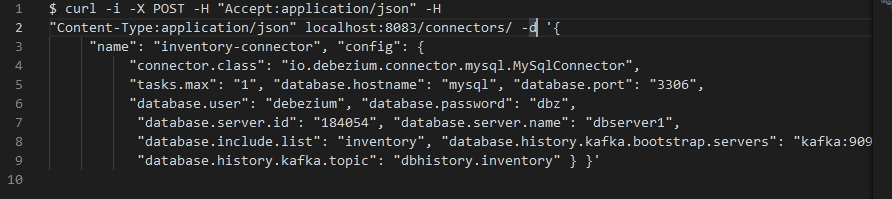
The above command uses the Kafka Connect service API’s to submit a post request. This post request is sent against the connector resource with a JSON comment that specifies the new connector called the inventory connector.
The above command uses the localhost to connect to the Docker host.
To check whether the inventory connectors are present in the list of connectors, you must use the following command.

Review the connector’s task using the below command.

To verify, check the following output.

By following the below output, you can understand the number of processes the connector goes through when it is created and starts reading the MySQL server binlog.
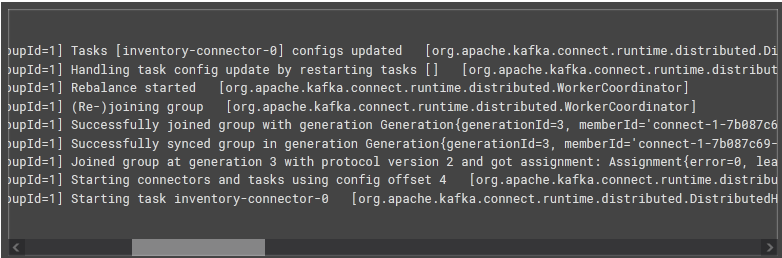
The above output shows everything about the inventory connector being created and started.
The below output shows different processes of the inventory connector after the connector has started.

The above is the Debezium connector output log. It provides thread-specific information in the log. Debezium makes it easier to understand the multithreaded Kafka Connect service. It also includes messages of MySQL connectors, the logical name of the connector, and the connector’s activity like task, snapshot, and binlog.
The above output consists of the few lines of the task activity and includes the connector’s snapshot activity. It further reports that a snapshot is being started using Debezium and MySQL databases.
After deploying the MySQL connector, monitoring the inventory database for changes in data events is finished. The connector monitors the events like deleting or inserting records in the database, updating records in the database, etc.
If you want to stop the services, use the following command.
$ docker stop mysqlterm watcher connect mysql kafka zookeeper
To verify that all the processes are stopped and removed, use the below command.
$ docker ps -a
You can also use the below command to stop any process or container.
docker stop <process-name> or docker stop <containerId>.
Implementing Debezium
To witness Debezium in action, let us take a dummy table, “customer” and make some changes in it.
Step 1: Adding a Record
For inserting a new record into the ‘customer’ table, execute:
INSERT INTO customer_table (id, fullname, email) VALUES (1, 'John Doe', 'jd@example.com')
After running this query, observe the corresponding application output.
Now, check that the new record is present in our target database:
id fullname email 1 John Doe jd@example.com
Step 2: Updating a Record
To update the last inserted customer’s information, run:
UPDATE customer_table t SET t.email = 'john.doe@example.com' WHERE t.id = 1
Observe the output, noting the change in operation type to ‘UPDATE’.
Verify the updated data in our target database:
id fullname email 1 John Doe john.doe@example.com
Step 3: Deleting a Record
Delete an entry in the ‘customer’ table with:
DELETE FROM customer_table WHERE id = 1
Observe the change in operation type and the corresponding query.
Confirm the deletion from our target database:
SELECT * FROM customer_table WHERE id = 1 -- 0 rows retrieved
Debezium Use Cases
- Cache Invalidation: Debezium’s CDC capabilities shine in scenarios where cache coherence is critical. It detects changes in database records, such as updates or deletions, and triggers automatic invalidation of the corresponding cache entries. This is particularly beneficial for systems using external caches like Redis, as it simplifies the application logic by offloading cache management to a dedicated service.
- Monolithic Application Decomposition: Debezium addresses the challenges of “dual-writes” in monolithic applications, where additional operations follow database updates. By capturing changes at the database level, it allows these operations to be processed asynchronously, enhancing the application’s resilience to failures and simplifying maintenance.
- Database Sharing: In environments where applications share a database, Debezium provides a seamless way to keep each application informed about others’ data changes. This eliminates the complexities associated with traditional inter-application communication methods, ensuring that all applications have access to the latest data without the risks associated with “dual writes.”
- Data Synchronization: Keeping data synchronized across different storage systems is a common challenge, and Debezium offers a streamlined solution. By capturing data changes and processing them through simple logic, it enables consistent data integration across platforms, simplifying the development of synchronization mechanisms.
For an alternative approach to data integration, explore how Debezium integrates with MySQL for real-time change data capture.
You can also learn about Distributed Tracing in microservice applications using Debezium.

Conclusion
This tutorial gives you an idea about Debezium, its needs, features, and services. Other similar tools include Kebola, Oracle Goldeneck, Talend, HVR, etc. This tutorial explains only the MySQL Debezium connector, but there are different connectors for Oracle, SQL, and PostgreSQL databases that can be used instead of MySQL.
The Automated data pipeline helps in solving this issue of creating easy ETL and this is where Hevo comes into the picture. Hevo Data is a No-code Data Pipeline and has awesome 150+ pre-built Integrations that you can choose from. Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
FAQs
1. Who owns Debezium?
Debezium is an open-source project of the Debezium Community and is supported by Confluent, the organization behind Apache Kafka. This one delivers CDC tools to stream database changes.
2. Is Debezium real-time?
Yes, the data streaming technology, Debezium, captures changes in databases in real-time. It lets applications react in real-time to data updates with the help of CDC.
3. What is Debezium to CDC?
Debezium is a tool for Change Data Capture or the tracking of changes in records of databases and streams them. The tool permits the capture of insert, update, and delete events to enable real-time data synchronization between different systems.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



