

The term “Data Lake” was first introduced by James Dixon in 2010 as a form of storage to cope with evolving data needs due to advancements in IT and IoT. The close of the 19th century and beginning of the 20th century saw an influx of new digital tools like the mobile phone and smart gadgets being introduced into the market.
As the appetite of the market grew, so did the data lake challenges and the quest for innovation by organizations who needed data to achieve their innovation goals. As of 2010, the data generated globally was 2 zettabytes (Statista). At the end of 2011, the data generated was 5 zettabytes, a whopping 150% from the previous year which is the highest data surge to date. Since then, data generated yearly has seen a steady rise. From 2 zettabytes in 2010 to 147 zettabytes in 2024 supports the fact that there are now more ways of generating data than were available in 2010.
With the data surge came the need for a storage that could cost-effectively handle the data, which is the reason we have the data lake today. The ability of the data lake to accept data in its original and varied format and store it in one location directly impacts the growing demand for it. Hence, the purpose of the data lake is to help organizations manage their data and cope with the data surge. The yearly growth in data generation and the increasing global demand for data lakes is shown in the diagram below.
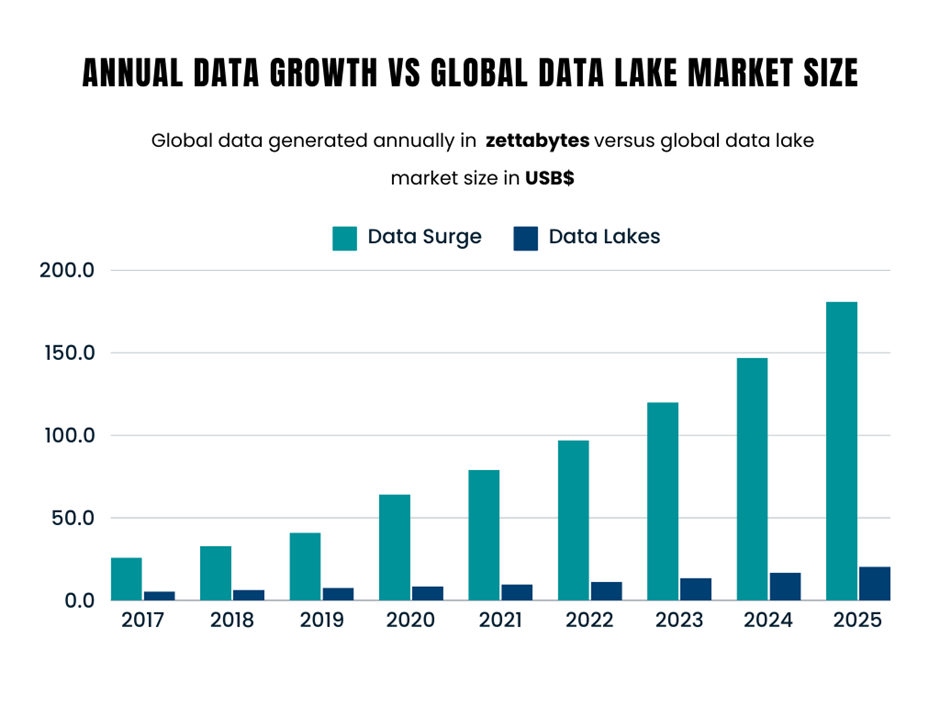
The global data volume trend clearly shows the corresponding increase in the demand for data lakes. With the evolution of the data lake comes the challenges that pose a threat to its productivity and efficiency.
Hevo’s no-code data integration platform eliminates your data hurdles, making it easier to efficiently manage and scale your data stack.
Here’s how Hevo helps:
- Seamless Data Integration: Hevo automates the process of integrating data from multiple sources into your destination, ensuring consistency and reducing manual efforts.
- Real-Time Data Ingestion: Avoid stale data with Hevo’s real-time data pipelines. Ensure your data lake is always up-to-date, ready for analytics and decision-making.
- Effortless Scalability: Hevo’s platform is designed to scale with your growing data needs, handling large volumes of data seamlessly while maintaining high performance.
Find out why industry leaders like Whatfix and Postman prefer Hevo Data for seamless data integration over Fivetran and Stitch.
Get Started with Hevo for FreeTable of Contents
Overview of Data Lake Challenges
What is a Data Lake and Why is it Important?
A data lake is a centralized repository designed to store large volumes of raw data in its native format, which can include structured, semi-structured, and unstructured data formats.
Simply put, it stores all kinds of data regardless of the structure or source in one location. This attribute differentiates the data lake from traditional data warehouses that require data to be pre-processed and structured before storage. Data in a data lake is not stored in tables like relational databases and lacks a predefined schema. Instead, data in a data lake is stored in files.
Why is the Data Lake Significant in Modern-day Architecture?
A couple of services and tools are integrated with the data lake which makes it possible for big data analytics, machine learning, and real-time processing to be performed on the data situated in the lake. Rather than working with separate tools and services; data engineers, data analysts and data scientists can collaborate on data in the lake in a cost-effective manner. Data lakes are highly beneficial as they enable organizations foster innovation.These attributes are what make the data lake significant in modern-day architecture.
Although the data lake has a lot of benefits and challenges. Its major challenges are governance, security, and automation.
Let’s discuss these in detail.
Common Data Lake Challenges & How to Solve Them
Challenge 1: Governance in Data Lakes
The practice of making data accurate, secure and available is known as data governance. Governance challenges in the data lake are largely due to the size and varied format of data in the lake. Here are some of the challenges that affect governance in data lakes:
1. Data Quality: Data coming into the data lake may be from different sources and as a result, have different formats. Hence, maintaining the accuracy, completeness, and reliability of data can become a significant challenge. This leads to poor data quality resulting in the generation of inaccurate analytics and ultimately, wrong business decisions.
2. Issues with Consistency: Achieving consistency across data stored in your data lake is essential, but the variation in formats and standards makes it hard to achieve data consistency. The nature of the data lake would require stringent methods to avoid discrepancies and manage data versions. This is core to attaining data integrity and consistency.
3. Efficiency of Metadata Management: Poor metadata management can turn your data lake into a “data swamp,” where data becomes difficult to locate, retrieve, and use. Effective metadata management in its simplest form requires that you understand and classify your data according to origin, transformation, and usage.
4. Regulatory Compliance: Data processing and storage is subject to regulatory standards such as GDPR and HIPAA. You may have a problem if regulatory standards are not factored into your data lake design.
You can imagine what happens when data governance is handled poorly, you may end up with data swamps. This highlights the need for you to have robust frameworks and technical tools to effectively manage data governance in your lake.
How to Solve Data Governance in Data Lakes?
1. AI and Machine Learning for Data Quality: Here, an automated model is created from data that has been well-governed. It is then used to detect and correct data anomalies, inconsistencies, and errors. The goal of this approach is to improve data accuracy and reliability continuously. Microsoft uses Microsoft Azure Machine Learning which allows you to create ML models that detect and correct anomalies.
2. Data Catalogs: A data catalog is a detailed and organized inventory of data assets within an organization that allows for easy tracking of the data assets. The catalog stores information which facilitates data discovery and ensures data governance and compliance. Google Cloud Data Catalog offers a fully managed and scalable metadata management service that you can use to manage all your data assets within Google Cloud.
3. Policy Management Tools: A Policy management tool is a software that automates the monitoring and enforcement of data governance policies throughout the data lifecycle. They enable you to define, implement, and manage policies for data access, usage, retention, and privacy. In essence, a policy management tool is for ensuring compliance and minimizing risks. An example is the Microsoft Azure Policy.
Data governance technologies empower you to optimize data management processes, enhance data quality, and effectively align with regulatory requirements.
Challenge 2: Security in Data Lakes
Some of the significant security challenges faced by data lakes include data breaches, access control difficulties, and data encryption complexities.
1. Data Breaches: A data breach is an incident where sensitive, protected, or confidential data is accessed, or stolen by an unauthorized party which can be caused by cyber-attacks, human error etc. Sometimes, data lakes contain sensitive data and it becomes necessary to protect against data breaches
2. Access Control: Considering the nature of data in the lake, this can be quite complex to implement. This is challenging because you must strike a balance between maintaining ease of use for legitimate users and preventing access from unauthorized persons.
3. Data Encryption: To protect sensitive information, data must be encrypted at rest and in transit. However, it gets complex when you have to manage encryption keys, and ensure data accessibility and maintenance.
Part of the complexities of the data lake is the fact that it does not contain tables that allow for row and column-level security measures to be implemented. Hence, it becomes necessary to employ emerging technologies is to make data security more manageable.
How to Solve Data Security in Data Lakes?
1. AI-Driven Security: The AI-driven security solution is a game changer, it uses a predictive approach to protect your data. These tools leverage machine learning algorithms to detect and respond to threats in real time. They do this by identifying patterns and anomalies that traditional methods might miss. For instance, Microsoft’s Azure Sentinel uses AI to provide intelligent security analytics and threat intelligence across your enterprise.
2. Access Control Technologies: Access control technologies work by enforcing access policies and reducing the risk of unauthorized access. Access can be granted or revoked at user or group level. Access control technologies like AWS Identity and Access Management (IAM) enable you to set permissions or create and manage AWS users and groups.
3. Encryption Technologies: These helps to protect your data both at rest and in transit. It works by converting data into a code that can only be decrypted using the correct key. The data remains unreadable to anyone without the correct decryption key. The encryption technology by Google protects your data by default with automatic server-side encryption for all data stored in Google Cloud.
Challenge 3: Automation in Data Lakes
Imagine a world where everything had to done manually with no automation whatsoever. With this, we can agree that automation is important to achieve operational efficiency, save time and perhaps cost. Although automation has its benefits, you may experience some challenges with automating your data lake. We’ve highlighted some of the issues below:
1. Data Ingestion and Processing: The nature of data ingested into the lake may cause issues with schema evolution (which involves modifying the structure of existing tables to accommodate changes in data over time) which can become a complex process over time. In addition to this, processing the data may involve a complex method like normalization. Without automation, we will have challenges with schema evolution and data processing resulting in human error and bottlenecks in operational efficiency.
2. Scalability: The data lake is a scalable structure and failing to automate its scalability feature to handle the growth of data can lead to the infrastructure performing poorly.
3. Performance: Data lake processes involving large datasets with complex data structures can result in bottlenecks and delays. If maintaining high performance is the goal, then optimizing your automation tools to handle large-scale data operations is key to avoiding performance issues.
4. Integration with Existing Systems: Integrating your data lake with workflows and existing data systems, such as data warehouses and business intelligence tools can be complex. Hence, you must plan carefully and identify areas where automation will be necessary to facilitate a seamless workflow.
5. Security and Privacy: Your data lake may contain sensitive data. Not automating your security and privacy controls may expose your data to breaches and all sorts of cyber-attacks.
How to Solve Automation in Data Lakes?
Since the goal of automation is to improve operational efficiency. Addressing these challenges requires the right automation strategies. As such, leveraging emerging technologies can greatly enhance the efficiency and productivity of your data enterprise. Here are some key advancements you should consider adding to your automation strategy:
1. Automated Data Ingestion Pipelines: Automation helps to simplify the process of ingesting data into the data lake. This is particularly important when managing large volumes of data from disparate sources. By leveraging the automated data ingestion pipelines, you can automatically collect, process, and analyze both batch and stream datasets. This streamlines the flow of data into your systems, ensuring timely and consistent data availability for analysis.
Hevo Data supports serverless data integration, allowing you to process data without worrying about infrastructure. You can set up automated workflows that scale as your data grows.

2. AI-Powered ETL: AI-powered ETL tools are made up of a set of automated processes that aid the processing of data from source (raw format) to target(processed format). These solutions come as dataflows that enable you to leverage AI to automate and optimize the ETL process of your data. This enhances data quality by detecting and correcting errors in real time.
3. Serverless Data Processing: The benefit of serverless data processing is its ability to scale automatically. It dynamically adjusts its resources to your data processing needs which helps your data operations to run seamlessly. In addition, you won’t have to worry about managing the underlying infrastructure and dealing with service disruptions that occur with traditional servers.
4. DataOps: DataOps or data operations is an emerging practice that focuses on improving the communication, integration, and automation of data flows between data managers and consumers. By implementing DataOps principles, you can enhance collaboration, streamline data workflows, and speed up the delivery of data-driven insights. This approach helps you maintain data quality and compliance in your data operations. Azure DevOps has a set of development tools that aids the implementation of DataOps principles.
By incorporating these cutting-edge technologies into your data automation strategy, you can streamline data ingestion, enhance data processing, and improve overall efficiency, ensuring you stay ahead in the data-driven world.
Conclusion
In conclusion, the efficiency and productivity of your data lake depend largely on your governance, security, and automation strategy.
Which of these technologies are you currently using and which of them do you hope to adopt?
At Hevo, we specialise in helping data teams to streamline their workflows, automate data processes and achieve operational efficiency in a timely manner. Our approach saves you hours per week and enables you make decisions business decisions quicker and more accurately.
Need to migrate your data to a data lake but don’t want to go through the pain of coding and implementing tens of steps? Hevo efficiently syncs data from over 150+ sources to your desired destinations like databases, data warehouses, and data lakes within minutes. Try Hevo and enhance your data migration with ease.
So, are you ready to take your data governance strategy to the next level with Hevo Data?
Frequently Asked Questions
1. What is the major risk of a data lake?
The biggest risk of data dumping in a data lake is its conversion to a data swamp. Additionally, combining the data sources makes it prone to errors.
2. What are the security issues with data lake?
One of the main challenges of data lake security is managing who can access what data and for what purpose
3. Which of the following is a common problem with data lakes?
Data lakes are hard to properly secure and govern due to the lack of visibility and ability to delete or update data.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




