

The term “Data Lakehouse” is quite common nowadays. The new concept promises to address the failures of data warehouses and data lakes and help support the workloads of both business intelligence and machine learning.
But what exactly is a data lakehouse, and how is it different from a data warehouse or a data lake?
Table of Contents
Data Lake vs. Data Warehouse
To talk about data lakehouses, we should start with the history of data warehouses and data lakes. Data warehouses have been treated as the standard in data storage and analysis since the 1960s. They are optimized for querying data and provide an excellent level of data governance. Things like schema enforcement, applying relationships between tables, and having indexes come right out of the box with minimal configuration required.
But with the increase in the size of data, data warehouses faced challenges they couldn’t solve. Semi-structured and unstructured data were on the rise and could not be stored natively in data warehouses.
The velocity at which the data was generated was also a challenge to data warehouses as data warehouses are normally loaded overnight in batch operations. This means data warehouses don’t support streaming natively. Also, data warehouses are not designed for reading and writing large amounts of data in parallel.
One approach to solving those challenges was data lakes. Data lakes depend on storing data as files in either block storage like the Hadoop distributed filesystem or object storage like S3. These systems are optimized for large amounts of data and accept any type of data, whether structured, semi-structured, unstructured, or even binary files.
However, data lakes suffer from weak data management. As data is stored as files, data lakes only support schema-on-read. There are neither constraints nor relationships between entities, resulting generally in data silos – partitioned data that is not managed like the rest of the organization’s data – and duplicated data.
| Aspect | Data Warehouse | Data Lake |
| Data | Structured | Structured, semi-structured and unstructured |
| Schema | On Read | On Write |
| Cost | High | Low |
| Agility | Low | High |
| Support | Business Intelligence | Machine Learning |
Many organizations choose to use both in a two-level architecture to overcome the limitations resulting from only using a data warehouse or a data lake.
Data is loaded from source systems into a data lake with minimal transformations, and then some data from the data lake is transformed and consolidated into a data warehouse. The major drawback of this architecture is that we now have to build and manage two environments. Also, there is a noticeable amount of data redundancy between the data lake and the data warehouse.

Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. With integration with 150+ Data Sources (60+ free sources), we help you not only export data from sources & load data to the destinations but also transform & enrich your data, & make it analysis-ready.
Here’s why you should explore Hevo:
- Seamlessly integrates with multiple BI tools for consistent, reliable insights.
- Automatically enriches and transforms data into an analysis-ready format without manual effort.
- Fully automated pipelines for real-time, secure, and reliable data transfer.
- Ensures zero data loss with fault-tolerant, scalable architecture.
What is a Data Lakehouse?
The data lakehouse architecture was introduced to merge data warehouses and data lakes into one structure, offering the data management and governance that the classic data warehouses are famous for on top of data lakes to enjoy the low cost and support for different data types. This will enable users to rely solely on data lakehouses and not need to duplicate data onto data warehouses or data lakes to serve a specific workload.
How Does a Data Lakehouse Work?
A data lakehouse is built on top of a data lake. A metadata layer on top of the data lake defines tables and columns from the files written into the data lake. There is also a SQL engine or another API for reading those files.
The SQL engine or the API is run on compute nodes. These are different from the storage nodes that store the data. It first connects to the metadata layer to read table definitions and associate files before connecting to the storage nodes to read the data.
Key Features of Data Lakehouse
Some key features of a data lakehouse are:
- Storage and computation are decoupled: This enables us to scale our infrastructure depending on our needs and usage. For example, if multiple teams access our data lakehouse, we can use the same storage for multiple compute instances. We can have multiple storage instances with only one compute instance if we need more storage than computation.
- Support for different workloads: A data warehouse focused more on supporting BI and analysis tools, while a data lake focused more on machine learning applications. A data lakehouse can easily support both workloads, as it can read and write huge amounts of data at the same time. It also has a data catalog to allow schema-on-read.
- Support for different data types: A data lakehouse can store structured, semi-structured, and unstructured data at the same place and read it using the same API.
- ACID transactions and versioning: Like data warehouses, data lakes have strong data management and governance. They can also keep multiple versions of the same table, enabling us to query a table as it was at an earlier time. Additionally, a data lakehouse can support streaming data into and from it.
- Open data formats: A data lakehouse stores data in open-source formats such as parquet or Optimized Row Columnar (ORC). This can help boost the performance of reading from or writing to it, as data will not need to be re-serialized from a proprietary format for our application and tools to understand it.
- Schema enforcement and data lineage: A data lakehouse provides schema enforcement for data written into tables and data lineage for every file written.
Benefits of a Data Lakehouse
A data lakehouse can have the benefits of a data lake and a data warehouse without actually using both, as in the two-layer architecture. Some of the benefits of using a data lakehouse are:
- Lower cost: Since a data lakehouse normally relies on object storage, it is usually much cheaper than a data warehouse.
- Better data governance: The presence of the metadata layer provides strong data governance.
- Easier scaling: Having storage and computation decoupled in data lakehouses makes scaling much more effortless. You can only scale what you genuinely need.
- Reduced data redundancy: The two-level architecture allows for data redundancy since data is copied to the data lake first and then to the data warehouse. However, when using a data lakehouse, you only need to store your data in one place to analyze and query it.
- Better performance: The metadata layer collects statistics about the tables that can enhance performance. The data lakehouse also creates indexes and partitions for the data to improve performance.
- No vendor Lock: Because the data lakehouse uses open-source data formats, you can easily change vendors without needing to migrate your data lakehouse into another storage engine with another format.
Challenges Of Using a Data Lakehouse
While these benefits can tempt you to implement a data lakehouse for your needs, you also need to know about the challenges you will face if you implement one. Some of these challenges are:
- Complexity: A data lakehouse is more complicated than a data lake or a data warehouse. With multiple components and layers to manage, you can struggle to build and operate one.
- Maturity: A data lakehouse is a relatively new architecture, which means concepts and tools for it are still being designed and developed to match our needs.
- High initial cost: While a data lakehouse will prove much cheaper in the long run than combining a data lake and a data warehouse, the initial cost can still be high.
Layers of Data Lakehouse Architecture
Data lakehouse architecture consists of multiple layers, each with a specific purpose. You can use whatever tools and protocols you want to build these layers and achieve their goals.
This architecture also ensures that the components of any data lakehouse are loosely coupled, so any component can be replaced with another one that achieves the same end goal without affecting other components. This adds to the “No Vendor Lock” benefit of using data lakehouses.
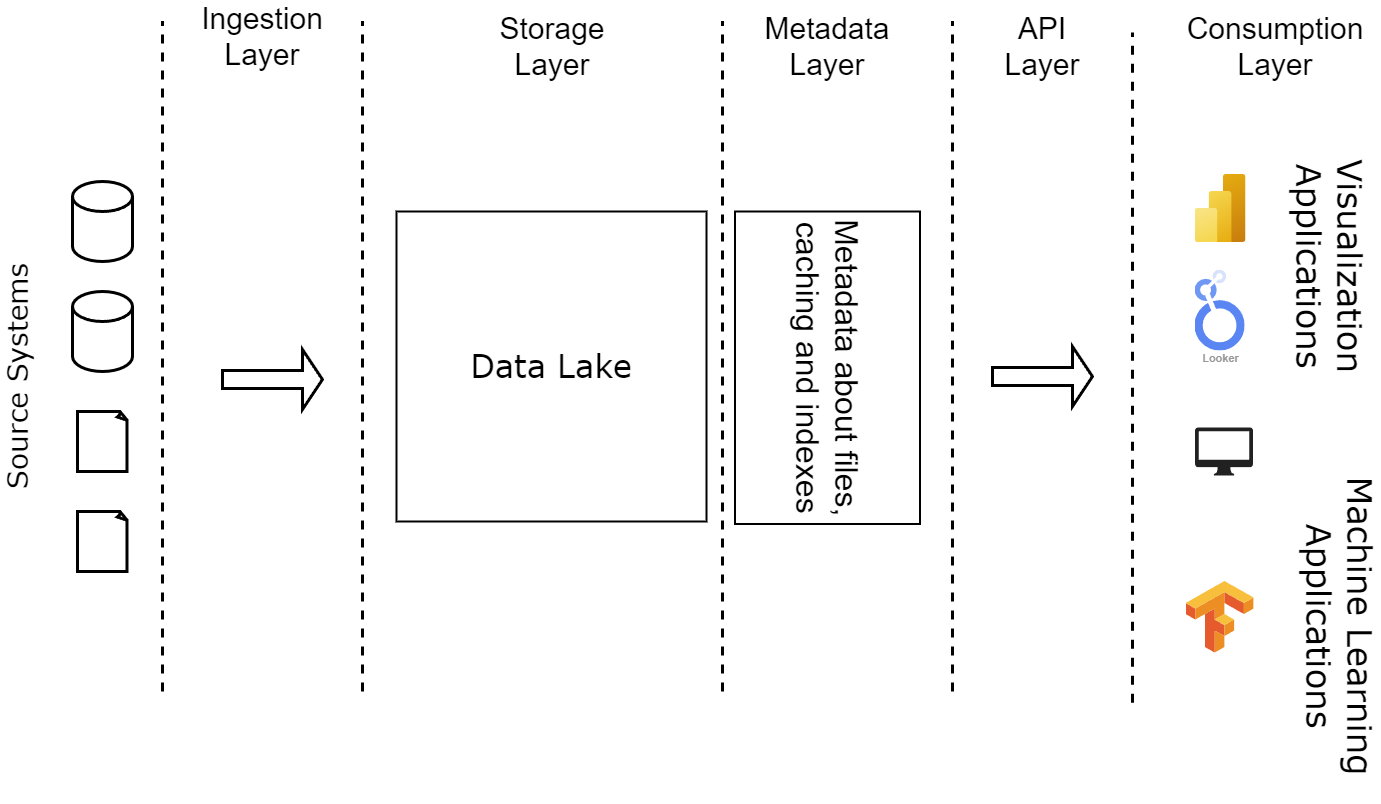
The layers of a data lakehouse are:
- Ingestion layer. This layer collects data from multiple sources and puts it into the data lakehouse. It can have different tools and protocols and should support batch and streaming processing.
- Storage layer. Structured, semi-structured, and unstructured data can be stored freely in this layer using open-source formats like parquet or ORC.
- Metadata layer. This layer is the main component of a data lakehouse. It is responsible for collecting, managing, and providing metadata about data stored in the data lakehouse. This metadata allows a data lakehouse to implement many of its important features, such as schema enforcement, ACID transactions, versioning, caching, and indexing. This layer also allows the data lakehouse to have data governance on all of the data stored in it.
- API layer. This layer provides multiple APIs with which users can read the data. These APIs can be SQL or application-specific APIs that connect to the data storage layer directly on an abstract level, such as TensorFlow for machine learning applications.
- Consumption layer. This layer serves all applications and tools that might need to read data from the data lakehouse, such as machine learning jobs and visualization tools. These clients connect to the metadata layer to get the table definitions and the storage layer to read the data.
Future Trends and Developments
The data lakehouse is still a new concept. It was introduced to the world around 2021 by Databricks. There is much room for improvement. New frameworks and tools are being developed continuously. Some of the aspects that are being worked on right now are:
- New file formats. New open-source file formats that are more optimized for the access pattern of data lakehouses can increase performance and reduce storage costs significantly.
- Better metadata layer. The metadata layer is considered the main layer of a data lakehouse. Attempts are underway to enhance it with better data discovery, better caching policy, and automated pipeline optimization.
- Improved security features. With all of the data in one place ready to be queried, we need stronger security measures more than ever. We need to be able to secure the data both at rest and in transit, as well as have finer control over which users have access to which pieces of data.
- Real-time data processing. Even though the data lakehouse supports streaming, we need to improve such support and extend it to have real-time data analysis capabilities.
You can also learn more about the differences between data warehouse, data lake, and data lakehouse.

Conclusion
Data lakehouses were designed to fill the gaps left by data lakes and data warehouses. They offer strong data management of data warehouses on top of cheap storage like data lakes, allowing for the storage of different types of data (structured, semi-structured, unstructured) and the computation of different workloads (business intelligence, machine learning). With new tools and file formats, data lakehouses can be the new standard for storing and analyzing data.
Try a 14-day free trial with Hevo to seamlessly transfer your data and store in Data Lakehouses. Also, check out our unbeatable pricing to choose the best plan for your organization.
Frequently Asked Questions on Data Lakehouses
1. What is a data lakehouse?
Data Lakehouse is a new data architecture that combines the benefits of using a data warehouse and a data lake simultaneously by providing a metadata layer on top of a data lake to support ACID transactions and offer strong data management as in data warehouses.
2. What is the difference between a data lakehouse and a data lake?
Both data lake and data lakehouse are built on top of a cheap storage layer that supports structured, semi-structured, and unstructured data. But a data lakehouse offers strong data management, ACID transactions, caching, and indexing on top of its storage layer giving it an edge in performance and data governance on data lakes.
3. What is the difference between a data lakehouse and a data warehouse?
The largest difference is the ability to store different types of data. A data warehouse is optimized for storing structured data only. A data lakehouse, on the other hand, can store structured, semi-structured, and unstructured data. The data lakehouse can also have parallel read and write operations, giving it the edge when dealing with large amounts of data.
4. Is data lakehouse cheaper than data warehouse?
Yes, mostly, since a data warehouse is usually built using proprietary software, while a data lakehouse relies on open-source software and file formats.
5. How to build a data lakehouse?
Start by choosing a storage engine with an appropriate storage format. The format should satisfy your needs for compression and compatibility with other tools in your stack. Then, choose a metadata store/catalog and point it to your storage layer. After that, choose an API that can connect to your metadata store/catalog and read from your storage layer efficiently.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




