

Companies use Data Warehouses to store and analyze their business data to make data-driven business decisions. Querying through huge volumes of data and reach to a specific piece of data can be challenging if the queries are not optimized or data is not well organized.
Amazon Redshift is a fully managed Cloud Data Warehouse widely used by companies. It allows business users to store data in a unified format and run complex queries quickly. Sometimes it is convenient to run Amazon Redshift Dynamic SQL queries that make it easier for users to query data in an automated fashion.
Amazon Redshift Dynamic SQL use variables to execute queries in runtime which automates the process and saves time. In this article, you will learn about Amazon Redshift Dynamic SQL, how to use it and what are different ways to create Amazon Redshift Dynamic SQL with examples.
Table of Contents
Prerequisites
- An active AWS account. AWS offers free tier services for new users for 12 months. You can get more details about the AWS free tier services here. If you’re new to AWS, then sign up.
- Advanced knowledge of constructing and executing SQL queries.
Hevo allows users to configure Redshift as a Source as well as a Destination. Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. With integration with 150+ Data Sources (60+ free sources), we help you not only export data from sources & load data to the destinations but also transform & enrich your data, & make it analysis-ready.
With Hevo, you can:
- Automate Data Extraction: Effortlessly pull data from various sources and destinations with 150+ pre-built connectors.
- Transform Data effortlessly: Use Hevo’s drag-and-drop feature to transform data with just a few clicks.
- 24/5 Live Support: The Hevo team is available 24/5 to provide exceptional support through chat, email, and support calls.
Explore Hevo’s features and discover why it is rated 4.3 on G2 and 4.7 on Software Advice for its seamless data integration.
Get Started with Hevo for FreeWhat is Amazon Redshift?

Amazon Redshift is a Cloud-based serverless Data Warehouse provided by Amazon as a part of Amazon Web Services. It is a fully managed and cost-effective Data Warehouse solution. AWS Redshift is designed to store petabytes of data and perform real-time analysis to generate insights.
AWS Redshift is a column-oriented Database that stores the data in a columnar format compared to traditional Databases stored in a row format. Amazon Redshift has its own compute engine to perform computing and generate critical insights.
Amazon Redshift Architecture
AWS Redshift has straightforward Architecture. It contains a leader node and cluster of compute nodes that perform analytics on data. The below snap depicts the schematics of AWS Redshift architecture:
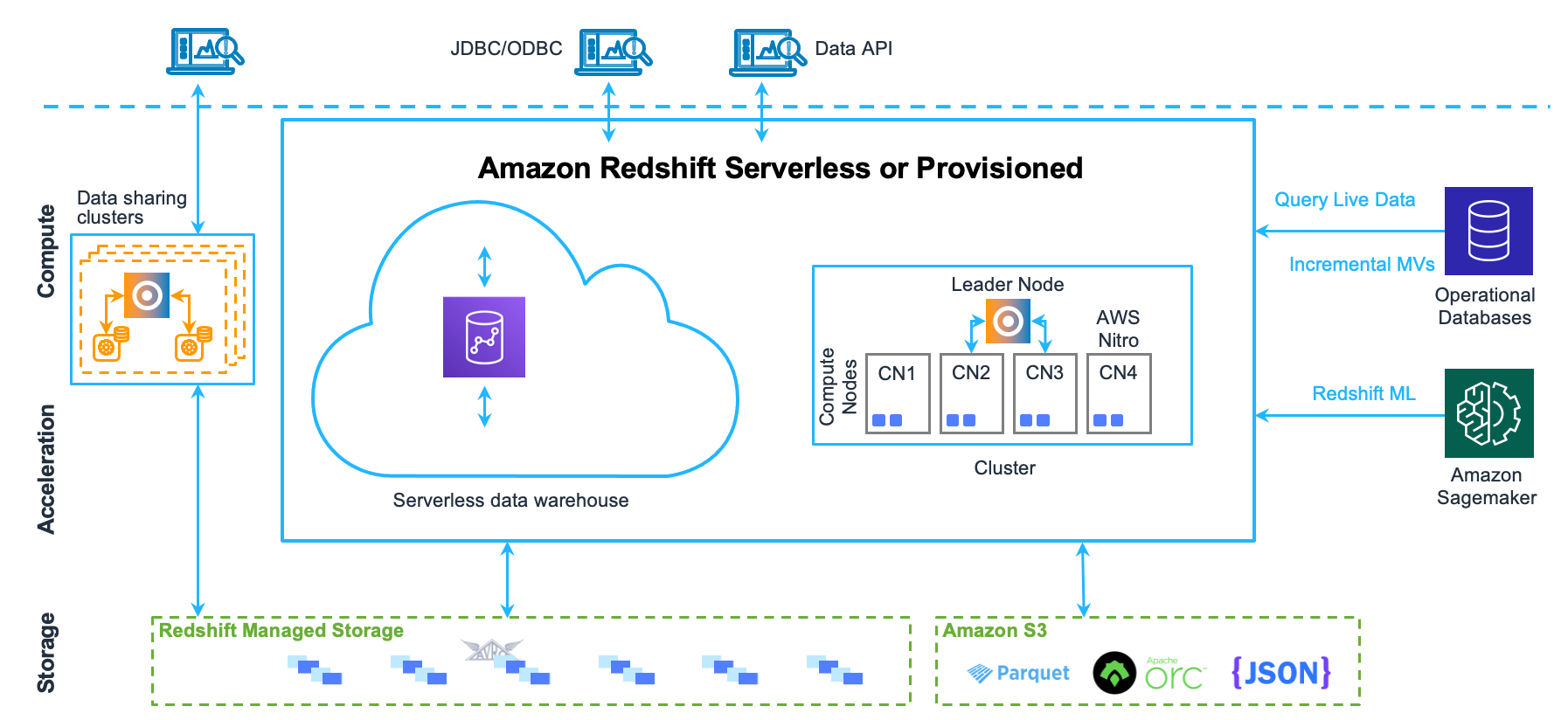
AWS Redshift offers JDBC connectors to interact with client applications using major programming languages like Python, Scala, Java, Ruby, etc.
Key Features of Amazon Redshift
- Amazon Redshift allows users to write queries and export the data back to Data Lake.
- Amazon Redshift can seamlessly query files like CSV, Avro, Parquet, JSON, and ORC directly with the help of ANSI SQL.
- Amazon Redshift has exceptional support for Machine Learning, and developers can create, train, and deploy Amazon Sagemaker models using SQL.
- Amazon Redshift has an Advanced Query Accelerator (AQUA) which performs the query 10x faster than other cloud data warehouses.
Also, check out more about: Amazon Redshift ETL – Top 3 ETL Approaches for 2025
What is Amazon Redshift Dynamic SQL?
Amazon Redshift Dynamic SQL is a technique to build parameterized SQL queries that can attain the variable values at runtime. Amazon Redshift Dynamic SQL offers flexibility and multi-use of SQL where the key parameters on the SQL’s are variables and attain their value at compilation/runtime.
For example, consider an application that performs repetitive queries on the database, where the user inputs the table names. You construct an Amazon Redshift Dynamic SQL that takes the key parameter, i.e., table name, as an argument and can only be synthesized at runtime to accommodate this behavior.
Benefits of Using Amazon Redshift Dynamic SQL
- Amazon Redshift Dynamic SQL allows users to parameterize the key parameters of the table.
- Amazon Redshift Dynamic SQL is more flexible and parameterized for usage.
- Users need to create one single SQL which can serve multiple purposes.



How to Create Amazon Redshift Dynamic SQL?
Now that we have a basic understanding of Redshift and Dynamic SQL, in this section, we will see how to construct Amazon Redshift Dynamic SQL.
Amazon Redshift offers two ways to create Amazon Redshift Dynamic SQL, listed below:
1) Prepared Statement
- The PREPARE statement in Redshift is used to prepare a SQL statement for execution, and it supports SELECT, INSERT, UPDATE or DELETE statements. PREPARED statements take parameters whose values are substituted into the SQL statement when executed.
- The PREPARED statement takes a list of datatype as the argument and refers to them via $1, $2,… The scope of the PREPARED statement is within the session. PREPARED statements are discarded automatically when the session ends. In the case of multiple sessions, you cannot use single PREPARED statements, and a separate PREPARED statement needs to be created for use.
- The PREPARED statement has a high-performance advantage when used on a single session for executing a large number of similar statements.
Prepared Statement – Statements
PREPARED statements have three different statements as defined below –
- Prepare: This statement creates a PREPARED statement and follows the below syntax.
PREPARE plan_name [ (datatype [, ...] ) ] AS statement- Execute: This statement is to execute the above created PREPARED statement.
EXECUTE plan_name (value1, value2, ..)- Deallocate: This statement is to deallocate or destroy the prepared statement from the session.
DEALLOCATE plan_namePrepared Statement – Syntax
PREPARE plan_name [ (datatype [, ...] ) ] AS statementwhere,
- plan_name: A name for the prepared statement by which it can be called.
- datatype: The data type of a parameter to the prepared statement. To refer to the parameters in the prepared statement itself, use $1, $2, and so on.
- statement: Any SELECT, INSERT, UPDATE, or DELETE statement.
Prepared Statement – Examples
- An example of using an INSERT statement in a PREPARED statement.
CREATE TABLE emp (id int, name char(20));
PREPARE prep_insert_plan (int, char)
AS insert into emp values ($1, $2);
EXECUTE prep_insert_plan (1, 'Cam');
EXECUTE prep_insert_plan (2, 'Harry');
EXECUTE prep_insert_plan (3, 'Kris');
DEALLOCATE prep_insert_plan;- An example of using SELECT statement in a PREPARED statement.
PREPARE prep_select_plan (int)
AS select * from emp where id = $1;
EXECUTE prep_select_plan (2);
EXECUTE prep_select_plan (3);
DEALLOCATE prep_select_plan;2) Stored Procedure
Stored Procedures are mostly used to encapsulate the logic inside a procedure to provide the dynamic arguments to the query at runtime. The Stored Procedure allows users to encapsulate logic for data transformation, validation, business rules, and many more under one single Stored Procedure.
Stored Procedures can also be used to enable users to perform functions without giving access to actual functions users. For example, only the admin can truncate the table, and instead of granting a user permission to the table, they can create a Stored Procedure and give access to the users for that Procedure.
Stored Procedure – Syntax
The syntax for creating a Stored Procedure is as follows:
CREATE [ OR REPLACE ] PROCEDURE sp_procedure_name
( [ [ argname ] [ argmode ] argtype [, ...] ] )
AS $$
procedure_body
$$ LANGUAGE plpgsql where,
- sp_procedure_name – The name of the procedure
- [argname] [ argmode] argtype – A list of argument names, argument modes, and data types.
- AS $$ procedure_body $$ – A construct that encloses the procedure to be run.
Stored Procedure – Example
A simple example of a Stored Procedure is as follows:
CREATE PROCEDURE delete_record(id_value INOUT VARCHAR, table_name INOUT VARCHAR)
LANGUAGE plpgsql
AS $$
DECLARE
BEGIN
EXECUTE 'DELETE FROM ' || table_name || ' WHERE id = ' || quote_literal(id_value);
END;
$$;In the above example, the Stored Procedure delete_record takes table_name and id_value as a parameter that can be passed during the Stored Procedure call.
Calling Stored Procedure
Once the Stored Procedures are created, they can be called by using the CALL function.
Calling Stored – Syntax
CALL sp_name ( [ argument ] [, ...] )Calling Stored – Example
CALL delete_record(5, emp);Conclusion
In this article, you learnt about Amazon Redshift Dynamic SQL and how to create Amazon Redshift Dynamic SQL by using Prepared statements and Stored Procedures. You also went through a few examples to get a better understanding of Amazon Redshift Dynamic SQL queries. With the help of Amazon Redshift Dynamic SQL, users can automate and speed up the process.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. How to create a dynamic query in Redshift?
You can create a dynamic query in Redshift using stored procedures with EXECUTE statements. This lets you build SQL queries as strings and execute them within the procedure.
2. What is the difference between stored procedure and dynamic SQL?
A stored procedure is a saved set of SQL commands that can be reused, while dynamic SQL is built and executed at runtime, allowing flexibility in query generation.
3. What kind of SQL does Amazon Redshift use?
Amazon Redshift uses a SQL-based query language similar to PostgreSQL, with additional features for large-scale data analysis.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





