




Amazon Redshift is a completely managed Data Warehouse, offered as a cloud service by Amazon. It can scale up to petabytes of data and offers great performance even for complex queries.
Its columnar nature with Postgres as the querying standard makes it very popular for analytical and reporting use cases.
These days it is very common to use Amazon Redshift as the backbone Data Warehouse for highly reliable ETL or ELT systems.
In this article, you will look at ways of setting up a robust Amazon Redshift ETL.
Table of Contents
What is Amazon Redshift?

Amazon Redshift is a popular cloud-based Data Warehouse solution. Powered by Amazon, this Data Warehouse scales quickly and serves users, reducing costs and simplifying operations.
In addition, it communicates well with other AWS services, for example, AWS Redshift analyzes all data. present effectively in data warehouses and data lakes.
Redshift uses Machine Learning, Massive Parallel Query Execution, and High-Performance Disk Column Storage, Redshift delivers much better speed and performance than industry peers.
AWS Redshift is easy to use and scalable, so users don’t need to learn any new languages. Just download the cluster and use your favorite tools, you can get started with Redshift.
Data Extraction in Amazon Redshift ETL
Whether it is an ETL or ELT system, extraction from multiple sources of data is the first step. If you are looking for an ETL system, the extraction will involve loading the data to intermediate filesystem storage like S3 or HDFS.
In ELT’s case, there is no need for intermediate storage, and the data is directly pushed to Amazon Redshift, and transformations are done on Amazon Redshift tables.
Finalizing the extraction strategy will depend a lot on the type of use case and the target system one envisions. At a broader level, the extraction strategy will depend on the following factors:
- The use case can be handled using batch processing and source data is in the AWS ecosystem itself.
- The use case can be handled using the batch process and the source data is in an on-premise database.
- The use case needs real-time processing and the source is streaming ETL data.
Let’s first consider the case where the data is already part of the AWS ecosystem.
1) Source Data is Inside AWS
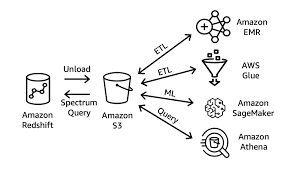
This assumes that the source data is already in S3 or some kind of AWS database service like RDS. In such cases, AWS itself provides us with multiple options for extracting and loading data to Amazon Redshift.
- AWS Data Pipeline: AWS Data Pipeline can integrate with all the available AWS services and provides templates with Amazon Redshift or S3 as a target. If you are imagining an ELT system, it would be worthwhile to use the Amazon Redshift target template directly so that the data is loaded directly to Amazon Redshift. That said, internally even this will use S3 as intermediate storage, but the end-user does not have to worry about that. One issue with the AWS data pipeline is that it normally works in the batch mode as periodically scheduled jobs and this does not do a good job in case the data extraction needs to be in real-time or near-real-time.
- AWS RDS Sync with Amazon Redshift: If your source data is in RDS and want to sync the RDS directly to Amazon Redshift in real-time, AWS offers partner solutions like Attunity and Flydata which work based on bin log streaming.
- Custom Pipeline Implementation: If you are unwilling to use a managed service for data load, it can be manually implemented by coding each step. Extracting the data first to AWS S3 and then using the copy command. More details on such an approach can be found here.
- Hevo, a No-code Data Pipeline: AWS data pipeline can be a bit overwhelming to set up considering the simple use case it serves. A No-code Data Pipeline like Hevo can do everything the AWS data pipeline does in just a few clicks, abstracting away all the complexity and intermediate steps involved. Hevo can also accomplish a near-real-time AWS Redshift ETL and can act as a one-stop tool that can do many things for you.
2) Source Data is Outside AWS
In cases where the source data is outside the AWS ecosystem, the options are fewer.
- AWS Data Migration Service: This is a completely managed AWS service, which can integrate with many databases like Oracle, Microsoft SQL Server, etc., and migrate data to Amazon Redshift or intermediate storage like S3. This is mainly used for one-off migrations and lacks integration with many widely used databases like MongoDB.
- Custom Pipeline Implementation: The custom pipeline mentioned in the above section can be used here as well. The first step is to extract data from the on-premise source to S3 and use the copy command. You can look at an example of how this can be achieved for MySQL to Redshift ETL. Similarly, the rest of the sources can be connected to the data load.
- Hevo, a No-code Data Pipeline: Hevo natively integrates with a multitude of data sources. Databases, Cloud Applications, Custom Sources like FTP, SDKs, and more. It can accomplish data extractions to Amazon Redshift in a matter of few clicks, without writing any ETL code, and can hide away much of the complexity. Explore its complete list of Data Sources here.
Hevo is a no-code data pipeline platform that not only loads data into your desired destination, like Amazon Redshift, but also enriches and transforms it into analysis-ready form without writing a single line of code.
Why Hevo is the Best:
- Minimal Learning Curve: Hevo’s simple, interactive UI makes it easy for new users to get started and perform operations.
- Connectors: With over 150 connectors, Hevo allows you to integrate various data sources into your preferred destination seamlessly.
- Schema Management: Hevo eliminates the tedious task of schema management by automatically detecting and mapping incoming data to the destination schema.
- Live Support: The Hevo team is available 24/7, offering exceptional support through chat, email, and calls.
- Cost-Effective Pricing: Transparent pricing with no hidden fees, helping you budget effectively while scaling your data integration needs.
Try Hevo today and experience seamless data transformation and migration.
Sign up here for a 14-day Free Trial!3) Real-time Data Extraction
In the case of real-time streams, whether or not the source is in AWS does not matter since the data anyway has to be streamed to the system-specified endpoints. Let’s explore different ways of accomplishing a real-time stream load to Amazon Redshift.
- AWS Kinesis Firehose: If there is a real-time streaming source of data that needs to be put directly into Amazon Redshift, Kinesis Firehose is the option you can use. Kinesis Firehose uses the COPY command of Amazon Redshift in a fault-tolerant way. This is also a completely managed service and charges only for actual use. Kinesis is not to be confused as a method for real-time duplication of data between two databases. That is a different use case and is accomplished using RDS sync or products like Attunity. Kinesis is for streaming data in the form of events. An example would be AWS cloud watch log events or S3 data update events.
- Kafka and Kafka Connect: In case, using a managed service is not preferable and you want close control over the streaming infrastructure, the next best thing to use is a Kafka ETL cluster and the open-source JDBC Kafka connector to load data in real-time.
Data Transformation in Amazon Redshift ETL
In the case of an ELT system, transformation is generally done on Amazon Redshift itself, and the transformed results are loaded to different Amazon Redshift tables for analysis.
For an ETL system, transformation is usually done on intermediate storage like S3 or HDFS, or in real-time as and when the data is streamed.
Regardless of this, all the tools mentioned below can be used for performing transformations.
Similar to extraction strategies, the transformation method to be used will depend on whether the use case demands batch/real-time transformations.
1) Batch Transformation
- AWS Glue: AWS glue is a completely managed Apache Spark-based ETL service that can execute transformations using an elastic Spark backend. The end-user is spared of all the activities involved in setting up and maintaining the spark infrastructure and is charged only for the actual usage. AWS Glue also provides automatic data catalogs using its crawlers and works with a wide variety of sources including S3. It can auto-generate Scala or Python code for running the jobs. Custom jobs are also possible along with the use of third-party libraries.
- AWS Data Pipeline: AWS Data Pipeline can also be used to perform scheduled transform jobs. It differs from Glue in the sense that more close control of the infrastructure of jobs is possible. AWS Data Pipeline allows selecting your EC2 clusters and frameworks for running the jobs. Jobs can be run using map-reduce, hive, or pig scripts or even using Spark or Spark SQL.
2) Real-time Transformation
- Kinesis Firehose: Kinesis Firehose has an option of invoking a custom Lambda function that can transform the streaming data in real-time and deliver the transformed data to destinations.
- Kafka Streaming: Kafka streams have functionalities like map, filter, flatmap, etc to do stateless transformations on the streaming data.
- Hevo Data Integration Platform: Hevo excels in its capability to run transformations on the fly. It provides a Python-based user interface where custom Python code can be written to clean, enrich, and transform the data. Users can even test the scripts on sample data before deploying the same. Hevo does all of this on the fly and in real-time. This takes away the complexity of reliably transforming the data for analysis.
Top 3 Approaches for Amazon Redshift ETL
Data loading into the Amazon Redshift Data Warehouse is now easier than ever. You can use any one of the below 3 approaches for Amazon Redshift ETL:
- Creating your own ETL Pipeline
- Amazon Redshift ETL with AWS Glue
- Third-Party Tools for Amazon Redshift ETL
You can also take a look at the best data extraction tools to help you decide the right approach that fits your needs.
1) Creating your own ETL Pipeline
Creating your own ETL pipeline improves performance and scalability. While implementing the Amazon Redshift ETL pipeline, you need to follow some best practices.
Below is the list of practices that should be followed:
- While using the COPY command of Amazon Redshift, it is always better to use it on multiple source files rather than one big file. This helps to load them simultaneously and can save a lot of time. Using a manifest file is recommended in case of lading from multiple files.
- In cases where data needs to be deleted after a specific time, it is better to use the time series tables. This involves creating different tables for different time windows and dropping them when that data is not needed. Dropping a table is way faster than deleting rows from one master table.
- Execute the VACUUM command at regular intervals and after the large update or delete operations. Also, use ANALYZE command frequently to ensure that database statistics are updated.
- AWS workload management queues enable the user to prioritize different kinds of Amazon Redshift loads by creating separate queues for each type of job. It is recommended to create a separate queue for all the ETL jobs and a separate one for reporting jobs.
- While using intermediate tables and transferring data between an intermediate table and a master table, it is better to use ALTER table APPEND command to insert data from the temporary table to the target table. This command is generally faster than using CREATE TABLE AS or INSERT INTO statements. It is to be noted that ALTER table APPEND command empties the source table.
- If there is a need to extract a large amount of data from Amazon Redshift and save it to S3 or other storage, it is better to use UNLOAD command rather than the SELECT command since the former command will be executed parallelly by all the nodes saving a lot of time.
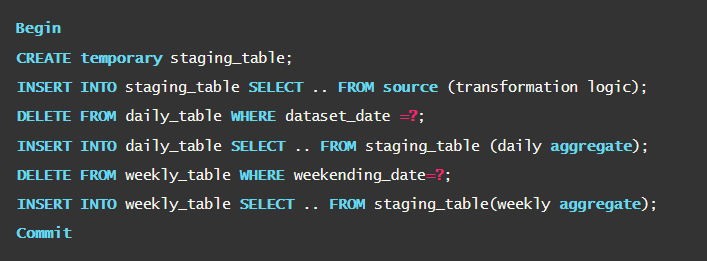
- For transformations that span across multiple SQL statements, it is recommended to execute the commit command after the complete group is executed rather than committing after each statement. For example, let’s say there are two INSERT statements in one of your ETL steps. It is better to use the COMMIT statement after both statements than to use a COMMIT after each statement. Below is a code snippet provided by Amazon.
2) Amazon Redshift ETL with AWS Glue

Instead of developing your own Amazon Redshift ETL pipeline, you can use Amazon Web Services’ Glue.
Creating an Amazon Redshift ETL pipeline using Glue does not require much effort because the data model and schema are auto-generated. Some of the benefits of using AWS Glue include:
- Rapid Data Integration: AWS Glue allows different groups in your company to collaborate on data integration tasks. This enables you to minimize the time to analyze the data.
- No overhead of Server Management: You need not take the burden of managing the infrastructures of AWS Glue. It automatically manages, configures, and scales based on the ETL requirements.
- Integrated Data Catalog: Data Catalog contains the metadata of all data assets. Data Catalog helps you to automate a lot of the other heavy work that goes into cleaning, categorizing, and enriching data so that you can spend more time analyzing data.
3) Third-Party Tools for Amazon Redshift ETL
Several third-party cloud ETL tools can be integrated with Amazon Redshift. One of the key benefits of using third-party tools is that they come with numerous external data sources.
However, AWS Glue will be an ideal choice if all your data resides in the Amazon infrastructure. Some of the popular third-party AWS Redshift ETL tools include:
- Hevo Data: It provides a no-code data pipeline that can be used to replicate data from 150+ Data Sources. It also helps you directly transfer data from a source of your choice to a Data Warehouse, Business Intelligence tools, or any other desired destination in a fully automated and secure manner without having to write any code
- Stitch: Stitch is also one of the popular ETL tools that allow replicating data from numerous data sources to the Data Warehouse. However, Stitch does not allow for arbitrary data transformations.
- Xplenty: Xplenty is also one of the cloud-based ETL data integration tools that allow you to connect many data sources with ease. Some of the benefits of using Xplenty include security, scalability, and customer support.
See how to connect AWS Glue to Redshift for optimized data handling. Explore our detailed guide for an easy setup and better performance.
If you are looking for more approaches, check out our blog on Loading Data to Redshift: 4 Best Methods

Conclusion
Amazon Redshift is a great choice to be used as a Data Warehouse because of its columnar nature and availability of multiple tools to cover the entire spectrum of Amazon Redshift ETL activities.
AWS itself provides multiple tools, but the choice of what to use in different scenarios can cause a great deal of confusion for a first-time user.
The AWS ETL tools also have some limitations in supporting source data from outside the AWS ecosystem.
All the above drawbacks can be addressed by using a fuss-free Redshift ETL tool like Hevo, which can implement a complete ETL system in a few clicks without any code. Hevo’s fault-tolerant ETL architecture will ensure that your data from any data source is moved to Amazon Redshift in a reliable, consistent, and secure manner. Sign up for Hevo’s 14-day free trial and experience seamless data migration.
FAQs
What is AWS Redshift used for?
AWS Redshift is a fully managed data warehouse service designed for analyzing large datasets quickly.
What is the best ETL tool for AWS?
The best ETL tool for AWS often depends on specific use cases, but popular options include AWS Glue for serverless ETL, Hevo for no-code data integration, and Apache NiFi for data flow automation.
Is Redshift a data lake or data warehouse?
Redshift is a data warehouse designed for fast querying and analysis of structured data, offering advanced analytics capabilities. While it can integrate with data lakes, it primarily functions as a data warehouse.


Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



