

A large language model (LLM) is a computational model based on machine learning that can identify and generate text.
It functions on deep learning, a type of machine learning method that understands how characters, words, and sentences work together.
To deploy and execute LLMs, you need seamless access to the data that you will use to train ML models. It is best to integrate and keep all your data on a storage platform from where it can be easily retrieved.
Snowflake is a secure and scalable platform for storing and analyzing datasets. It easily integrates with most data sources and provides effective features such as Snowflake Cortex or Snowpark for accessing and creating LLM-based applications.
This article provides in-depth information on Snowflake LLM services and features. You can use it to understand various LLMs and utilize Snowflake to build AI and ML-based applications.
Table of Contents
What is Snowflake LLM?
Snowflake Cortex is a fully managed service of Snowflake that offers a set of functions known as Snowflake LLM.
You can use them to leverage LLMs like Meta, Google, or Snowflake Arctic to query, translate, and generate texts.
It enables you to develop AI applications easily without much expertise in artificial intelligence and machine learning. Other than this, Snowflake offers Snowpark and integrates with Streamlit to facilitate the creation of LLM services.
To streamline your Snowflake data pipeline, consider using Hevo Data—a zero-code ELT platform designed for efficient data integration. This tool automates data storage in Snowflake, ideal for training LLM models. Hevo Data offers over 150 source connectors, real-time integration, and is cost-effective, making it a strong choice for automated data workflows.
Key Hevo Data Features for Snowflake Integration:
- Data Transformation: Transform data with Python-based or drag-and-drop tools to ensure consistency before training.
- Automated Schema Mapping: Automatically syncs Snowflake schema to the incoming data, avoiding manual setup and ensuring compatibility.
- Incremental Data Load: Transfers only updated data in real-time, saving bandwidth and compute costs, which optimizes Snowflake for LLM training.
Hevo’s streamlined approach enhances Snowflake’s capabilities, making it an efficient choice for LLM preparation.
Get Started with Hevo for FreeSnowflake Cortex LLM Functions
The functions of LLM Snowflake Cortex are as follows:
- COMPLETE
You can use the COMPLETE LLM function to complete a prompt using your desired LLM. You can give either a single or multiple prompts to get corresponding responses.
For a single response, you can use the following syntax:
SNOWFLAKE.CORTEX.COMPLETE(
<model>, <prompt_or_history> [ , <options> ] )- EMBED_TEXT_768
The EMBED_TEXT_768 function generates vector embeddings from the English language. Vector embedding is a process of converting texts into numerical form. The syntax for this function is as follows:
SNOWFLAKE.CORTEX.EMBED_TEXT_768( <model>, <text> )- EXTRACT_ANSWER
The EXTRACT_ANSWER LLM function provides answers to the questions in a text document. The text document could be in English language or in the form of a string of a semi-structured data object (JSON).
SNOWFLAKE.CORTEX.EXTRACT_ANSWER(
<source_document>, <question>)- SENTIMENT
The SENTIMENT function returns a score between -1 and 1 for an English-language input text. A score of -1 represents negative sentiment, 0 is for neutral, and 1 is for highly positive sentiment. The syntax for this function is as follows:
SNOWFLAKE.CORTEX.SENTIMENT(<text>)- SUMMARIZE
The SUMMARIZE function gives a summary of an English-language text, and its syntax is as follows:
SNOWFLAKE.CORTEX.SUMMARIZE(<text>)- TRANSLATE
The TRANSLATE LLM function translates text in English to a language of your choice. However, the languages supported by this function are limited. The syntax for the TRANSLATE function is as follows:
SNOWFLAKE.CORTEX.TRANSLATE(
<text>, <source_language>, <target_language>)Usage Cost of Snowflake Cortex LLM Functions
You are charged for using Snowflake LLM functions on the basis of number of tokens processed. The smallest unit of text processed by the Snowflake Cortex function is known as a token, and it consists of four text characters. The calculation for input and output tokens differ for various Snowflake Cortex LLM functions.
- For
COMPLETE,SUMMARIZE, andTRANSLATEfunctions that generate new text in output, both input and output tokens are counted. - For
EMBED_TEXTfunctions, only input tokens are counted. EXTRACT_ANSWERandSENTIMENTfunctions only extract text from input information. For them, only input tokens are counted.- The number of billable tokens while using the
EXTRACT_ANSWERfunction is the sum of the tokens in the from_text and questions fields. - The input token count is slightly more than the number of tokens in the text provided for querying the
SUMMARIZE,TRANSLATE,EXTRACT_ANSWER, andSENTIMENTfunctions. These functions add prompts to the input text to get the output response, which increases the utilization of tokens.
It is recommended that you use small warehouses to execute Snowflake LLM queries. A smaller warehouse consumes less compute resources and is, therefore, more cost-effective.
The following table gives the costs in the form of credits per million tokens for each LLM function:

To track the costs of using AI services in Snowflake, including the usage of Snowflake Cortex, you can use the METERING_HISTORY view. The syntax for this function is:
SELECT *
FROM snowflake.account_usage.metering_daily_history
WHERE SERVICE_TYPE='AI_SERVICES'Choosing the Right LLM for Snowflake
You should choose an LLM that aligns with the content size and complexities of your tasks. Here is a detailed overview of the models supported by Snowflake LLM functions:
1. Large Models
You should start with Snowflake’s most capable models, such as Reka-core, Lama3-70 b, and Mistral-large, to get experience working with leading LLMs.
- Reka-core is an advanced LLM of Reka AI with strong reasoning abilities, code generation, and multilingual fluency.
- Llama3-70b is an open-source model that is suitable for chat applications, content creation, and enterprise applications.
- Mistral-large is an advanced LLM offered by Mistral AI to conduct complex tasks that require large reasoning capabilities. It is also used to perform highly specialized functions, such as synthetic text generation, code generation, or agents.
2. Medium Models
- Snowflake-arctic is an LLM internally developed by Snowflake and excels at enterprise tasks such as SQL generation, coding, and instruction following benchmarks.
- Reka-flash is a highly capable multilingual language model optimized for fast workloads. It can be used to write code and to extract answers from documents with hundreds of pages.
- Mistral-8x7b is used for text generation, classification, and question answering. It supports low latency with low memory requirements and gives higher throughput for enterprise applications.
- Llama2-70b-chat is used for performing tasks that require less reasoning, like extracting data or helping you write job descriptions.
3. Small Models
- Llama3-8b can be used to conduct less specialized operations with better accuracy than the llama2-70b-chat, like text classification, summarization, and sentiment analysis.
- Mistral-7b is useful to perform instantaneous tasks such as simplest summarization, structuration, and question answering.
- Gemma-7b can be used for simple code and text completion tasks. Even though it has a context window of 8,000 tokens, it is highly capable and cost-effective within that limit.
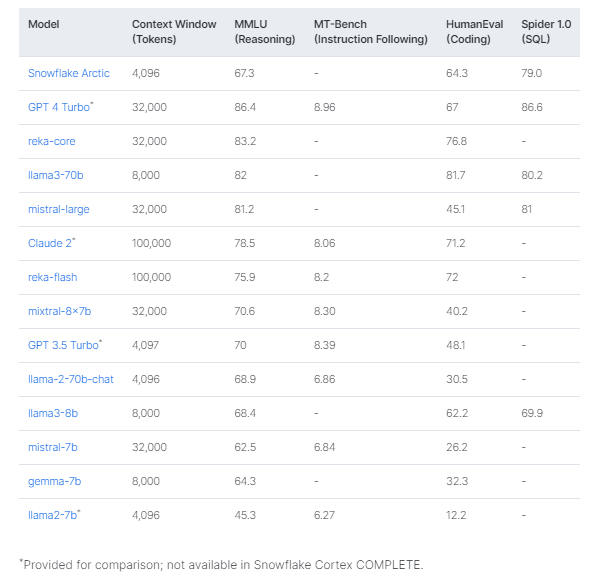
You can refer to the table below to understand how different models fulfill different performance parameters:
Using Snowflake Cortex LLM Functions with Python
You can run Snowflake Cortex LLM functions in Python. If you want to run these functions outside Snowflake, you will have to create a Snowpark session.
For single data values, you can use the Snowflake Cortex LLM functions with Python in the following way:
from snowflake.cortex import Complete, ExtractAnswer, Sentiment, Summarize, Translate
text = """
The Snowflake company was co-founded by Thierry Cruanes, Marcin Zukowski,
and Benoit Dageville in 2012 and is headquartered in Bozeman, Montana.
"""
print(Complete("llama2-70b-chat", "how do snowflakes get their unique patterns?"))
print(ExtractAnswer(text, "When was snowflake founded?"))
print(Sentiment("I really enjoyed this restaurant. Fantastic service!"))
print(Summarize(text))
print(Translate(text, "en", "fr"))You can also use Snowflake LLM functions on multiple values, such as data in a table column. In the example below, the SUMMARIZE LLM function is used on the abstract_text column of the table named articles, which creates a new column called abstract_summary.
from snowflake.cortex import Summarize
from snowflake.snowpark.functions import col
article_df = session.table("articles")
article_df = article_df.withColumn(
"abstract_summary",
Summarize(col("abstract_text"))
)
article_df.collect()A Snowflake-native app to monitor Fivetran costs.

How Snowflake Supports LLM Services?
Snowflake offers AI and ML features for LLM by supporting the following services:
- Snowflake Cortex Functions: Snowflake Cortex is a fully managed service that handles all the infrastructure management tasks. It also enables you to perform vector embedding and semantic search to understand how the model responds to your data, which helps you create customized apps easily.
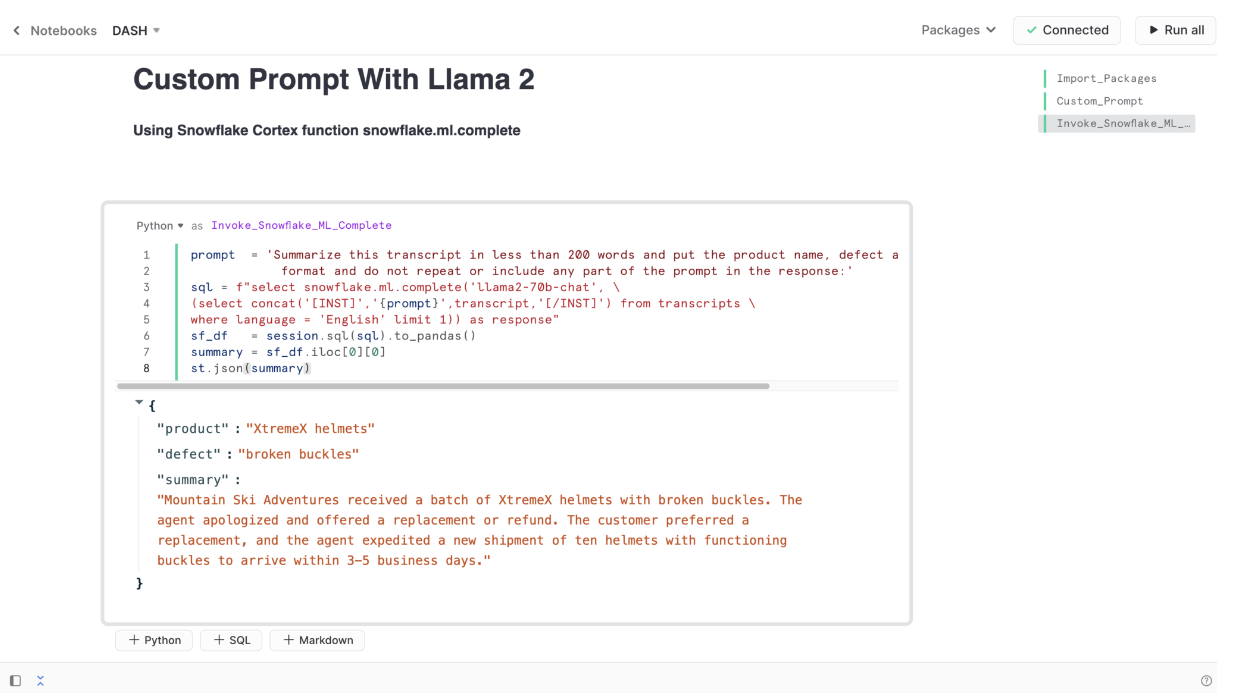
Here is an example of extracting a custom summary from a table in Snowflake using Llama 2:
- Snowpark: Snowflake offers a library called Snowpark that provides fully managed container services. It enables the deployment and management of containerized applications in the Snowflake ecosystem. Snowpark allows you to fine-tune open-source LLMs, use commercial LLMs, and develop custom user interfaces for LLM apps. When using Snowpark, you do not need to move data out of Snowflake for processing.
- Streamlit: Streamlit is an open-source library in Python that is used to develop web-based applications using machine learning. It allows you to build LLM-based applications using your data in Snowflake without moving it or the application code to an external system. You can then deploy and share these applications across an organization through unique URLs.
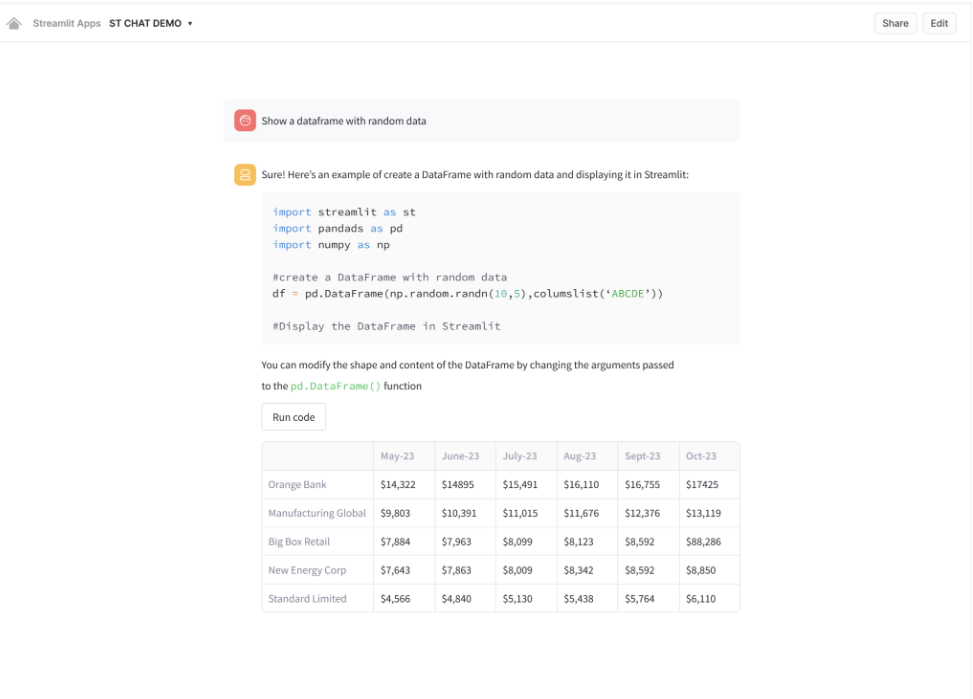
The below image shows a component of Streamlit chat running in Snowflake.
- Centralized Accessibility: If the data for training LLMs is scattered, its accessibility becomes difficult, which delays the application development process. Snowflake helps you eliminate this constraint by storing data from varied sources in consolidated form. The platform provides native support for structured, semi-structured, and unstructured data, and you can access the required data from a centralized database to train your LLMs.
- Aggregation and Analysis of Unstructured Data: Several organizations possess most of the data in an unstructured format, which is difficult to aggregate and analyze. Snowflake has acquired Applica, a multi-modal LLM for document intelligence, to facilitate the discovery and consumption of all data, including unstructured data types.
- Interactive Data Search: Snowflake’s LLM acquisition of Neeva, a search company, has facilitated efficient data searching through generative AI. It enables you to question and retrieve answers from LLMs with high precision.
- Enhanced Data Security: Snowflake offers powerful security features such as data encryption and masking. These features allow you to prioritize data analytics tasks rather than worry about the security of your data.
Snowflake Arctic: The Snowflake Owned LLM
Snowflake Arctic is an open-source and enterprise-focused LLM developed by Snowflake. Available under the Apache 2 license, you can use it for SQL generation, coding, and training high-quality models in a cost-effective manner. Arctic has a mixture-of-experts (MOE) architecture with a smaller size than other massive LLMs. However, it gives an optimum level of performance with half the training resources compared to the other LLMs.
The Arctic is trained on a dynamic data curriculum, which involves training the model by changing the combination of code and language over time. This makes it well-equipped with better language and reasoning skills. The Arctic comprises 480 billion parameters, of which only 17 billion are used at a time for training. Contrary to other similar models, this has resulted in less usage of compute resources.
Discover how to create Streamlit apps on Snowflake with this step-by-step guide, enhancing your ability to leverage Snowflake LLM for building high-performance AI solutions.
Use Cases of Snowflake LLM
The prominent applications of LLM in Snowflake are as follows:
- Topic Modeling: It is an unstructured machine learning technique that enables you to detect related words and phrase clusters in unstructured text, such as email or social media posts. You can use it to identify common themes in text data indicating a particular issue and improve your organization’s services.
For instance, you can use topic modeling to analyze customer complaints and identify similar issues faced by several customers. Then, you can make changes to your product to enhance your business.
- Data Labeling: Data labeling is a process of identifying raw data and adding informative labels to it while training machine learning models. You can use this services to label data. It reduces manual efforts by proposing tags for labeling data.
- Text Classification: Text classification involves the categorization of text documents based on their content. LLMs facilitate the automation of text classification, which is useful in sentiment analysis, spam detection, document analysis, and language translation.
- Data Cleansing and Imputation: LLMs simplify data cleansing tasks such as flagging duplicate data, data parsing and standardization, and identifying outliers or deviated values within data.
- Automating Data Science Workflows: You can use LLMs to automate various tasks involved in data workflow and analytics. For instance, LLMs enable text summarization and give a summary of large text data from business reports. You can use this summary to gain meaningful insights for your business growth.

Conclusion
- This blog gives you a comprehensive explanation of LLM on the Snowflake platform. It provides you with information about Snowflake Cortex LLM functions and their usage costs.
- The article also explains how Snowflake enables you to build LLMs through its various services and features, along with Snowflake LLM applications.
- To efficiently train data for LLMs, you can integrate it with Snowflake using Hevo Data. It offers a simple user interface and robust features that enable seamless data integration prior to the execution of LLMs. You can schedule a demo to take advantage of these features today!
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also checkout our unbeatable pricing to choose the best plan for your organization.
FAQs
1. Is Snowflake’s customer data used to train LLMs?
Snowflake does not use its customer data to train any of its LLM models. It also does not use your data stored in a warehouse for fine-tuning any model except on your direction. Only you can use the fine-tuned models built using your data.
2. Is Snowflake Cortex publicly available?
According to Snowflake documentation, Snowflake Cortex is in public preview, and you can easily use its LLM functions.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





