

Data professionals such as data engineers, scientists, and developers often use various tools and programming languages to get their work done. For your organization, these preferences can lead to overly complicated architecture, increased maintenance and operating costs, and new data silos that expose the data to security risk. What if there is a way to enable you and your entire team to collaborate securely on the same data in a single platform that works regardless of programming language?
Introducing Snowpark, the developer framework for Snowflake that opens data programmability to all users regardless of what language they use to code. Snowpark enables users to write code in their familiar construct and run it directly inside Snowflake, leveraging the Snowflake engine with no other processing system needed.
This write-up will delve deeper into Snowpark architecture, its core components, and their interactions. We will also explore how Snowpark can be used to revolutionize your data operations.
Table of Contents
What is Snowpark?
Snowflake, a famous cloud-based data warehousing platform, has changed how we manage and process our data. Building on its solid foundation, Snowflake created Snowpark, a powerful extension that is designed to enhance the data engineering, data science, and application development processes.
With Snowpark, users can interact with Snowflake programmatically using familiar programming languages such as Python, Scala, and Java. This capability simplifies complex data transformations, machine learning, and application development tasks within the Snowflake world.
Snowpark solves the limitations of traditional data processing architectures by offering a unified, serverless, and highly scalable environment for modern data problems. By leveraging Snowflake’s core strengths, Snowpark enables organisations to derive actionable insights from their data more efficiently and effectively.
Snowpark also prioritizes security and governance control by protecting your data from external threats and internal mishaps. Rather than moving between different systems, your data and code live in a single, highly secure system with full admin control, so you know exactly what is running in your environment. With Snowpark, you focus less on infrastructure management and more on data.
Loved by 2000+ customers, Hevo is the only near real-time ELT platform that provides more than 150+ sources(including 60+ free sources) to transfer your data across destinations such as Snowflake, Redshift, BigQuery and Databricks.
With Hevo, you can:
- Achieve transformations within the pipeline using Python scripts or a drag-and-drop interface.
- Fetch all your historical data from databases or SaaS sources.
- Perform integrations with a friendly user interface, no coding required.
Key Features of Snowpark
- Support for Different Programming Languages: Snowpark’s Python, Java, and Scala APIs let users write code in their preferred programming languages. This adaptability allows data engineers, data scientists, and developers to operate within their usual ranges of familiarity, speeding up advancement and reducing the expectation to learn and adapt.
- Convenience: Snowpark’s Data Frame API is based on Apache Spark, allowing intuitive, declarative data manipulations and transformations. By removing the complexities of distributed data processing with the Data Frame API, users can concentrate on their primary tasks without worrying about the underlying infrastructure details.
- Integration with Snowflake: Snowpark uses Snowflake’s strong SQL engine, virtual warehouses, and unified data-sharing abilities, guaranteeing superior execution, performance, scalability and robust security. This integration allows users to benefit from Snowflake’s features while expanding their capabilities with Snowpark.
Traditional Data Processing Architectures
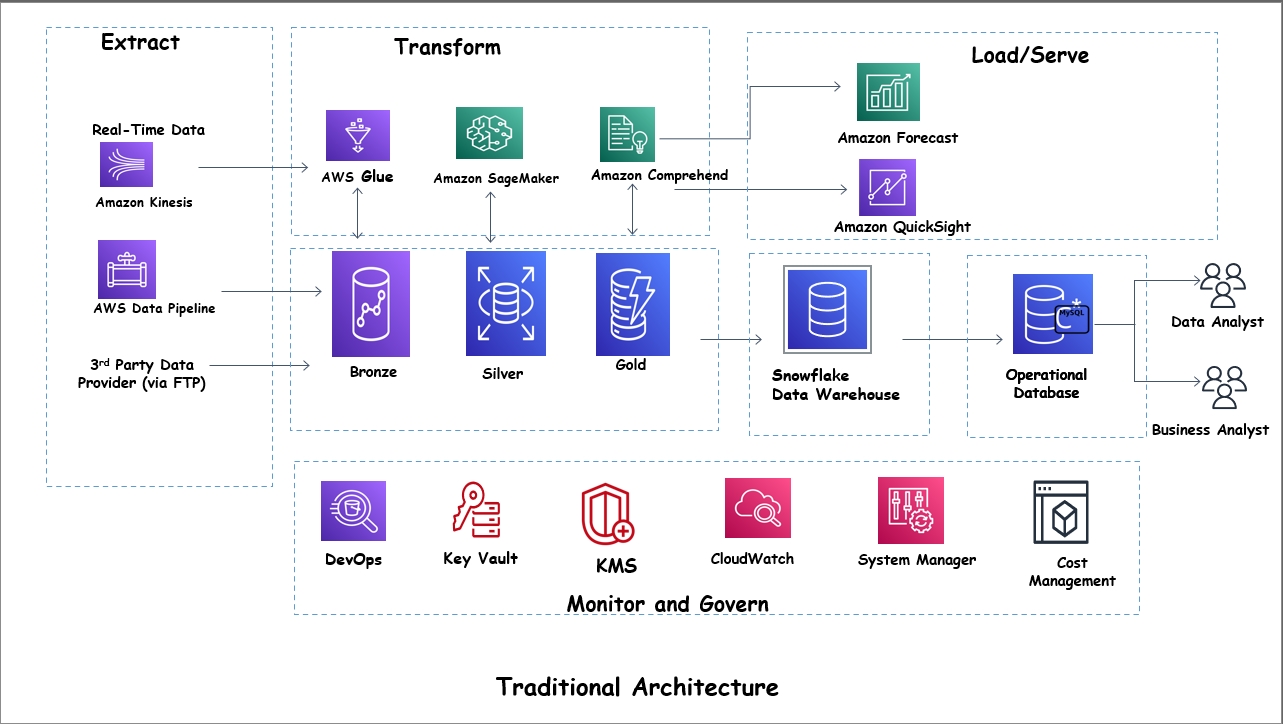
The architecture of traditional data processing has served organizations for decades, but it comes with significant limitations that hamper its effectiveness in modern data environments.
- Batch Processing: Traditional batch processing techniques process large amounts of data at scheduled intervals. While efficient for some tasks, batch processing often results in delayed data insights. This latency can be challenging for businesses that require real-time or near-real-time data to make informed decisions.
- Real-Time Processing: Carrying out real-time processing in traditional architectures can sometimes be complex and resource-intensive. Real-time systems require continuous data ingestion, processing, and delivery, which can strain resources and complicate system design. Traditional architectures often lack the flexibility and scalability needed to handle real-time data workloads efficiently.
- Management of Resources: Traditional setups often struggle with resource allocation and scaling, resulting in inefficiencies and increased costs. Fixed infrastructure limits the ability to scale up or down based on workload demands, resulting in either underutilized resources or performance bottlenecks
Modern Data Architecture with Snowpark
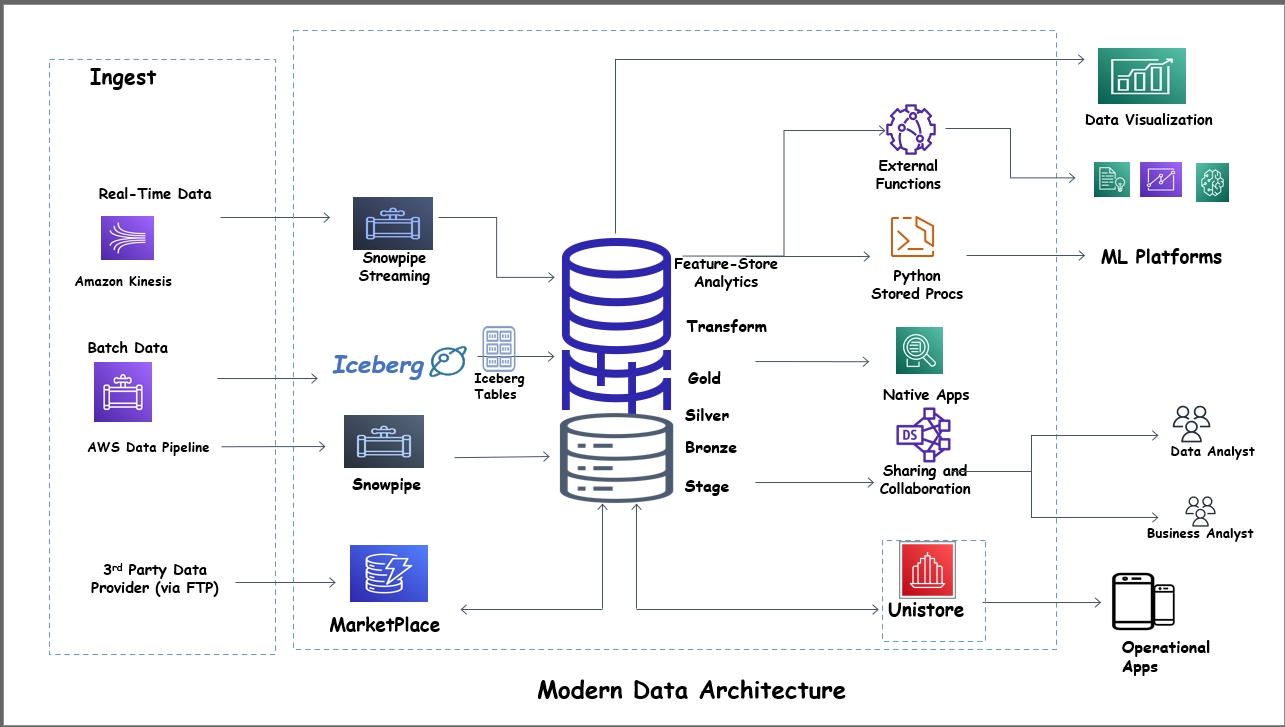
Snowpark reduces the limitations of traditional architectures by providing a cutting-edge, unified data platform that integrates seamlessly with Snowflake.
- Unified Data Platform: Snowpark integrates very well with Snowflake’s unified data platform, providing a singular environment for all data operations. Data workflows are made simpler, and this integration enhances collaboration across teams. By consolidating data processing, storage, and analysis in one platform, Snowpark eliminates data silos and ensures consistency across the organization.
- Serverless Execution: Auto-scaling and cost-effectiveness are just two of the significant advantages of Snowpark’s serverless architecture. Users can only pay for their computing resources, eliminating the need to over-provision resources. Serverless implementation ensures that resources are distributed dynamically based on workload demands, optimizing performance and reducing operational overhead.
- Programming Language Backing: Snowpark supports different programming languages, including Java, Scala, and Python. This adaptability simplifies data operations, enabling developers, data engineers, and data scientists to utilize the tools with which they are most familiar. Snowpark provides native APIs for popular languages, making it possible to integrate with existing codebases and development workflows seamlessly.
- Custom Transformation and Jobs: Snowpark allows custom data transformations and complex workload management, making it simpler to perform sophisticated data processing tasks directly within the Snowflake environment. Users can define and execute complex data pipelines utilizing familiar programming languages, thereby enhancing productivity and reducing development time.
A Snowflake-native app to monitor Fivetran costs

Key Components of Snowpark Architecture
Snowpark’s architecture comprises several key components that work together to provide a robust and flexible data processing environment.
- Snowpark API: The Snowpark Programming interface is available for Python, Java, and Scala, providing a familiar interface for data operations. Thanks to the API, users can write code in the language of their choice, removing the complexities of distributed data processing.
- Snowflake Engine: For effective data processing, Snowpark uses Snowflake’s powerful SQL engine and virtual warehouses. High performance and scalability are guaranteed by the Snowflake engine’s handling of query optimization, execution, and resource management.
- User-Defined Functions, or UDFs: Snowpark permits users to create custom Java, Scala, or Python functions. UDFs allow users to extend the functionalities of Snowpark by creating custom operations that can be applied to their data.
- Stored Procedures: Snowpark supports JavaScript for automating complex work processes. Users can summarize logic in a reusable script with stored procedures hence, simplifying the implementation of repetitive tasks.
- Integration with Features of Snowflake: Snowpark seamlessly works with the data sharing, security, and performance features of Snowflake. Snowpark can take advantage of Snowflake’s extensive feature set, which includes advanced analytics, access controls, and data governance, thanks to this integration.
- Connectors and Extensions: Snowpark allows you to connect to platforms and tools from third-party companies. Users can connect Snowpark to their existing data infrastructure through connectors and extensions, which improves interoperability and expands functionality.
Importance of Snowpark in Modern Data Ecosystems
Snowpark improves the Snowflake environment by providing an advanced, versatile, and unified platform for data processing and application development.
Its architecture uses the qualities of Snowflake while offering the adaptability and power of modern programming languages. Snowpark is a useful tool for businesses that want to get more value out of their data because of its capabilities.
Snowpark in Action: Use Cases
The flexibility of Snowpark makes it suitable for a wide range of data processing tasks, including:
- Data Ingestion: Ingesting data from multiple sources into Snowflake.
- Data Transformation: Cleaning, enriching, and transformation of data.
- Data Analysis: Performing simple and complex data analysis and machine learning.
- Data Pipelines: Building automated data pipelines for ETL and ELT processes.
- Real-Time Processing: Handling data streaming and generating real-time insights.
Snowpark Performance and Optimization
The performance of Snowpark is heavily influenced by factors such as data volume, complexity of computations, and hardware resources. To optimize performance, consider the following best practices:
- Data Partitioning: Large data can be partitioned to improve query performance.
- Clustering: Query efficiency can be improved by clustering data based on columns that are frequently accessed.
- Caching: Make use of Snowflake’s caching process to minimize query latency.
- Code Optimization: Leverage vectorized operations and write efficient code.
- Hardware Acceleration: Explore the GPU option for acceleration for complex workloads.
Benefits and Challenges
Benefits
- Ease of Use: Simple API and seamless Snowflake integration
- Performance: processing of high-performance data with the help of Snowflake’s SQL engine.
- Adaptability: Support for numerous programming languages and custom capabilities.
- Scalability: Based on the workload demands. The Snowpark serverless architecture ensures efficient scaling.
- Security and Compliance: inherits the robust security features of Snowflake, ensuring regulatory compliance and data privacy.
Challenges
- Curve of Change: New users might face an expectation to learn and adapt while adjusting to Snowpark’s features and capacities. Familiarising oneself with the underlying programming languages and data processing concepts is essential for effective use.
- Integration Issues: challenges that might arise when integrating with non-standard data sources. While Snowpark supports many connectors and extensions, some custom integrations may require additional development effort.
- Cost Management: Careful monitoring and optimization are necessary to control costs.
- Performance Tuning: Optimizing Snowpark performance can be complex for complex workloads.
Conclusion
Snowpark is a game-changer for data engineering, data science, and application development within the Snowflake ecosystem. By providing a unified platform, flexible programming options, and robust integration capabilities, Snowpark enables organizations to unlock the full potential of their data. Its modern architecture addresses the limitations of traditional data processing methods and offers significant benefits in terms of performance, scalability, and ease of use.
Try Hevo with a 14-day free trial.
Frequently Asked Questions
1. Why use Snowpark over SQL?
With Snowpark you can use familiar programming languages and APIs for complex data transformations, making it more adaptable than standard SQL. Although SQL is powerful for querying and basic data manipulations, Snowpark extends its capabilities by enabling advanced data processing and machine learning tasks.
2. What is the difference between Snowflake and Snowpark?
Snowflake is a cloud-based data warehousing platform, while Snowpark is an extension that allows programmatic interaction with Snowflake using Python, Java, and Scala. Snowflake focuses on data storage, query execution, and management, while Snowpark enhances these capabilities by providing a flexible programming interface for custom data operations.
3. Why is Snowpark used?
The Snowpark is used to simplify data processing, machine learning, and app development within the Snowflake environment. Snowpark allows users to make use of their existing programming skills and tools to build complex data workflows, reducing the time and effort required to derive insights from data.
4. Is Snowpark an ETL tool?
While Snowpark can be used for ETL (Extract, Transform, Load) processes, it is a versatile tool that supports a wide range of data operations beyond traditional ETL. Snowpark’s capabilities extend to data transformations, machine learning, and real-time data processing, making it a comprehensive solution for modern data workloads.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



