

According to The Gartner Group, poor data quality drains a company on average $12.9 million annually in resources and expenses for operational inefficiencies, missed sales and unrealized new opportunities. Many companies, even today, struggle with balancing the high cost of computational resources against their often unpredictable needs. Autoscale Databricks is a practical answer to this problem, saving companies from losing money and increasing performance by adjusting cluster sizes to match demand.
In this blog, we shall see the benefits of autoscaling and review the best practices that are implemented to maintain optimal cluster performance while controlling expenses. We’ll learn together why Databricks is such an adaptable technology.
Table of Contents
What is Autoscaling in Databricks?
Autoscaling in Databricks is a powerful tool that makes the best use of computing power by adjusting the cluster’s size automatically based on the workload. Rather than adjusting resources manually, Databricks helps companies automate the process of adding and removing nodes for heavier tasks. It’s particularly beneficial for handling fluctuating demands in data processing tasks. When workloads increase, autoscaling adds more worker nodes to handle the demand. Businesses may avoid wasting money on unnecessary tools and have the resources they require. You can also use Databricks Overwrite in tandem with autoscaling for better resource utilization.
Seamlessly integrate your data into Databricks using Hevo’s intuitive platform. Ensure streamlined data workflows with minimal manual intervention and real-time updates.
- Seamless Integration: Connect and load data into Databricks effortlessly.
- Real-Time Updates: Keep your data current with continuous real-time synchronization.
- Flexible Transformations: Apply built-in or custom transformations to fit your needs.
- Auto-Schema Mapping: Automatically handle schema mappings for smooth data transfer.
Read how Databricks and Hevo partnered to automate data integration for the Lakehouse.
Get Started with Hevo for FreeBenefits of Autoscaling in Databricks
Cost Efficiency
By adjusting the number of nodes as workload demand changes, autoscaling helps avoid excessive costs associated with idle resources. This is a very important benefit for businesses that have to deal with varying data-processing needs. For instance, in a retail analytics platform that experiences high demand during holiday seasons or major shopping events, autoscaling ensures resources match peak demand without incurring unnecessary costs during low-activity periods.
Optimal Use of Resources
Autoscaling makes the most effective use of available resources. Let’s say that we have an e-commerce platform where user demand can change unpredictably. When resources are needed, autoscaling makes sure they are available. By avoiding both over-provisioning and under-provisioning, this optimization improves the user experience without compromising system stability.
Enhanced Performance for Data-Intensive Applications
In data-intensive industries like finance and healthcare, performance is paramount. During data-heavy tasks, such as machine learning training sessions or real-time analytics, autoscaling expands clusters to provide the required computational power. For example, in financial trading, where split-second decisions depend on vast datasets, autoscaling helps prevent latency issues during market hours by dynamically adjusting resources.
Reduced Administrative Overhead
Cluster management can become tiresome without autoscaling. It requires constant adjustments to cluster size. The process is automated by autoscaling, which frees up resources for other uses. For example, data science teams can focus on developing and optimizing machine learning models without needing to monitor and adjust computational resources manually.
Environmentally Friendly Computing
Autoscaling helps businesses lower their carbon footprint by preserving resources. Moreover, businesses do their best to achieve their sustainability objectives. Businesses can save energy and support more environmentally friendly and sustainable cloud computing operations by using only the computational resources required.
How does Autoscaling work with Databricks Clusters?
Databricks autoscaling is based on intelligent algorithms that track the cluster’s workload. These algorithms dynamically add or remove worker nodes based on the cluster’s CPU and memory usage, as well as on the task queue and job load. When more nodes are needed, autoscaling will add them from the cloud infrastructure that is available. When demand drops, nodes are turned off to minimize costs.
When autoscaling is enabled, users define a minimum and maximum range of nodes that the cluster can scale between. This range will be automatically adjusted by the cluster to ensure that resources are accessible during periods of high workload without going over budget during periods of low activity.
You can take a look at how you can create database clusters as well as the two types of database clusters in detail.
Databricks Runtime
The Databricks Runtime offers a customized autoscaling environment with preconfigured libraries and parameters to facilitate the scaling process. You can choose from different Databricks runtimes based on the amount of workload. Here are the examples:
- Standard Runtime: Best for general-purpose workloads.
- ML Runtime: Designed to work best with deep learning and machine learning.
- GPU Runtime: This is the best time for jobs that use a lot of GPU power, like training complex neural networks.
- Photon Runtime: Designed to work best with SQL.
Databricks is a flexible platform for a wide range of use cases since each Databricks autoscale with runtime is tailored to the particular scaling requirements of the workloads it targets.
Configuring Autoscale Databricks with Different Runtimes
| Databricks Runtime | Autoscale Compatibility | Description |
| Standard Runtime | Yes | General-purpose data engineering and analytics |
| ML Runtime | Yes | Machine learning tasks, training and evaluation |
| GPU Runtime | Yes | GPU Intensive Applications such as deep learning |
| Photon Runtime | Yes | Optimized for high-performance SQL processing |
Using the right Databricks autoscale with runtime can boost speed while still making good use of resources, especially for applications that need specific memory or computational configurations.


Steps to Enable Autoscaling in Databricks
Enabling autoscaling in Databricks is straightforward and can be done from the cluster settings. Here’s a step-by-step guide:
- Step 1: Open the Databricks workspace: Start by navigating to the Databricks workspace where you’ll configure the cluster.
- Step 2: Go to Clusters: From the sidebar, select Clusters.
- Step 3: Create or Edit a Cluster: You can either create a new cluster or edit an existing one. Under the cluster setup options, you can turn on autoscaling.
- Step 4: Turn on auto-scaling: Toggle Enable Autoscaling on and off in the settings panel.
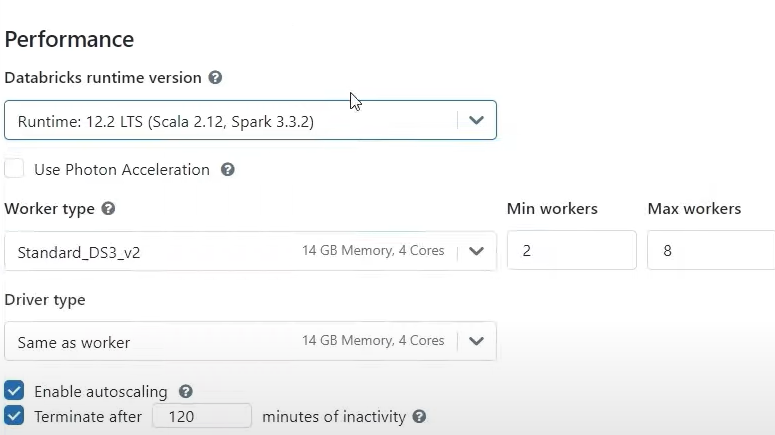
- Step 5: Describe the Min and Max Workers: Set the minimum and highest number of worker nodes that the cluster should have. The cluster will only scale within this range, allowing you to control costs.
- Step 6: Save and Launch: Once you’ve configured autoscaling, save the settings and launch the cluster.
Here’s a sample JSON configuration code snippet to define autoscaling in Databricks:
{
"cluster_name": "Example Cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "i3.xlarge",
"autoscale": {
"min_workers": 2,
"max_workers": 10
}
}Common Challenges Faced While Autoscaling in Databricks
- Scaling Delays – Due to setup and teardown time, autoscaling may not respond instantly to workload spikes, causing temporary performance lags. These delays can make it harder to handle data in real-time and may cause response times that aren’t optimal for some applications.
- Resource Constraints – There are times when cloud service companies may not have enough resources, especially in areas with a lot of demand or during peak periods. These restrictions can make it difficult for Databricks to scale up, which can lower job performance.
- Cost Overruns – Without proper limits on node scaling, autoscaling can lead to unexpected expenses. A common pitfall is setting maximum worker nodes too high, which can cause resource over-allocation during minor workload spikes.
- Compatibility Issues – Not all Databricks Runtimes support every autoscaling feature, and using an incompatible runtime can lead to configuration issues. It’s essential to select the correct runtime to prevent errors or reduced efficiency.
- Dependency Conflicts – Autoscaling can sometimes encounter issues with specific libraries or dependencies required for certain jobs, particularly in complex workflows where multiple dependencies interact dynamically.
Best Practices for Using Autoscaling in Databricks
- Set Appropriate Limits – Set realistic minimum and maximum node limitations based on how much work is often done. To minimize unexpected expenses, do not set excessively high limits.
- Monitor Cluster Performance Regularly – You can use Databricks’ monitoring tools to look at how well your cluster is doing and make changes to the scaling settings over time. Check the efficiency of autoscaling on a regular basis to make sure it meets operational and financial needs.
- Optimize Job Scheduling – Schedule data processing jobs during non-peak hours when possible. This practice helps avoid competition for resources and reduces the likelihood of scaling delays due to cloud provider limitations.
- Utilize the Right Databricks Runtime – Select a runtime based on the type of workload you have. For example, ML Runtime works best for machine learning tasks, while Photon Runtime is best for SQL tasks.
- Define Usage Policies – Establish policies on how and when to enable autoscaling, particularly for shared resources. This method stops users from scaling unexpectedly which could unintentionally affect other users’ costs or performance.
- Use Automation to Manage Scaling – Use automation tools to handle autoscaling configurations based on real-time needs. Automation can optimize resource usage by modifying parameters in response to preset triggers without manual intervention.
Also, take a look at Databricks cost optimization to get a better understanding of how you can save maximum costs while using Databricks.
Use Cases and Examples of Autoscale Databricks
Autoscaling is an important part of data processing because it meets the needs of different businesses. Let’s look at some examples of how autoscaling in Databricks helps different types of businesses:
Retail
Peak data loads for retailers frequently occur during flash sales like Black Friday or during holiday seasons. Using autoscaling, they can deal with a lot of data at once, without having to worry about resources being idle during slow times.
Healthcare
With the help of autoscaling, healthcare workers can handle data from electronic health records, medical imaging, and tracking patients in real-time. Autoscaling makes sure that there are enough computing resources to handle large amounts of data at once, which is especially important during health situations.
Financial Services
In financial services, autoscaling is critical for applications like stock trading, where performance spikes during market hours are crucial. Autoscaling dynamically meets computational demands, enabling data processing for large-scale transactions.
Manufacturing and IoT
Autoscaling helps manufacturers handle data from IoT devices used in predictive maintenance, especially when the way machines are used changes. Autoscaling is helpful because it gives you the tools you need to handle large amounts of data from sensors and predictive analytics platforms.
Comparing Autoscaling in Databricks with Other Platforms
Autoscaling with Databricks is made for high-performance systems like Apache Spark. This is a quick look at how it stacks up against other cloud data platforms’ autoscaling features:
| Feature | Databricks | Google BigQuery | Snowflake | AWS Redshift |
| Scaling Type | Dynamic cluster autoscaling | Serverless query scaling | Auto scale warehouse | Concurrency |
| Ease of use | Simple via interface | Fully managed | Configurable | Manual setup |
| Cost efficiency | Terminates idle clusters | Pay as you go | Pauses unused clusters | Overprovision risk |
| Workload focus | Analytics, ML | Analytics | Analytics | Analytics |
| Response | Fast | Fast | Fast | Moderate |
Autoscaling with Google BigQuery
BigQuery provides scaling for data warehousing and analysis but lacks Databricks’ focus on big data processing and machine learning, making it better suited for SQL-heavy tasks.
Autoscaling with Amazon Redshift
Redshift supports scaling for data warehousing but has limitations in handling large-scale data science workloads like Spark. Databricks’ autoscaling suits companies needing more flexible and complex data analytics.
Autoscaling with Snowflake
Snowflake offers autoscaling with excellent concurrency support. But Databricks’ unique Spark-based environment makes it better for machine learning, real-time analytics, and ETL-heavy tasks.
For a deeper understanding of Databricks’ features, check out how to fully leverage the overwrite functionality.
Conclusion
Databricks autoscaling is a powerful way to handle changing workloads effectively which improves efficiency and minimizes costs. Businesses can focus on their main data processing and analytics jobs without having to worry about managing cluster size by hand when they use this feature. Autoscaling not only optimizes resource usage but also enables companies to dynamically meet the demands of complex data workloads, making it a valuable tool for data scientists and engineers alike.
To maximize the benefits of autoscaling, it’s essential to configure it correctly, monitor usage patterns, and apply best practices for effective resource management. Organizations can ensure that their Databricks infrastructure is always appropriate for their workloads, allowing them to achieve higher agility, scalability and cost-efficiency.
For businesses looking to simplify their data management and integration processes, Hevo provides a reliable, no-code data pipeline solution. Hevo helps automate data transfer and ensures seamless integration of data from multiple sources into platforms like Databricks while maintaining data integrity and consistency.
Sign up for Hevo’s 14-day free trial and experience seamless migration.
Frequently Asked Questions
1. What is autoscaling in Databricks?
Autoscaling in Databricks is a feature that automatically adjusts the number of worker nodes in a cluster based on current workload demands, enabling efficient resource utilization and cost savings.
2. What is the primary goal of autoscaling?
The main goal of autoscaling is to dynamically manage computational resources, ensuring optimal performance during peak times while minimizing costs during low-demand periods.
3. What are the types of autoscaling options available in Databricks?
Based on the runtime, Databricks offers a number of autoscaling configurations, such as Standard, ML, GPU, and Photon. There are different runtimes that are best for different types of workloads, like machine learning, GPU-heavy, or SQL-heavy jobs.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





