



MongoDB Oplog happens to be a special collection that keeps a record of all the operations that modify the data stored in the database. The Oplog in MongoDB can be created after starting a Replica Set member. The process is carried out for the first time with a default size. A collection of mongod processes maintaining the same dataset is known as a Replica Set in MongoDB. They provide redundancy and high availability along with serving as the basis for production deployments.
This article helps you wrap your head around MongoDB Oplog, after which it explores its features, its data operations, and the processing methodology.
Table of Contents
Introduction to MongoDB Oplog
MongoDB uses a Transaction log internally just like many other databases. This is known as an Oplog in MongoDB. This serves as an internal log of every internal operation used for replication in a MongoDB Cluster. Each Replica Set, in a Sharded Cluster, has its own Oplog.
This can be accessed in a fashion similar to any other Collection in MongoDB. MongoDB allows for two operations: commands and data manipulation ops. Before delving into the MongoDB commands and data manipulation ops, here is a look at the Oplog entry structure.
{"ts": 6642324230736183304,
"h": -1695843663874728470
"v": 2,
"op": "u",
"ns": "analysts.analysts",
"o": {
"$set": {
"r": 0
}
},
"o2": {
"_id": "598262a2f79853492c9bc3b1"} }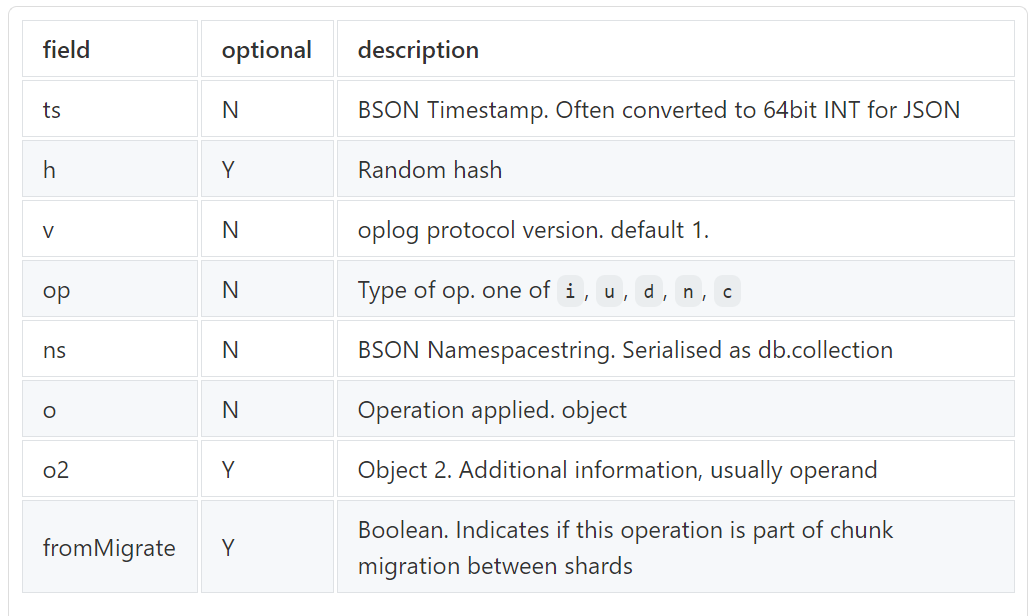
The above image gives you an idea of the most common and useful fields, with many more fields for other types of operation present.
With Hevo Data, you can easily integrate MongoDB with a wide range of destinations. While we support MongoDB as sources, our platform ensures seamless data migration to the destination of your choice. Simplify your data management and enjoy effortless integrations.
Check out how Hevo can be of help:
- No-Code Data Pipelines: Set up data transfers from MongoDB to your desired destination without writing a single line of code.
- Automated Schema Mapping: Automatically detect and map MongoDB schemas to match the destination structure, ensuring accurate data transfer.
- Secure Data Transfer: Ensure your data is protected during migration with encryption and secure connections.
Explore Hevo’s features and discover why it is rated 4.3 on G2 and 4.7 on Software Advice for its seamless data integration. Try out the 14-day free trial today to experience hassle-free data integration.
Get Started with Hevo for FreeUnderstanding MongoDB Oplog Features
After MongoDB has rolled in new updates, MongoDB Oplog is no longer simply a special capped Collection that keeps a rolling record of all operations, that modify the data stored in your databases. After version 4.0 was introduced, it can now grow past its configured size limit, unlike other capped Collections. This is done to avoid deleting the majority commit point.
As MongoDB ushered in version 4.4, it allowed specifying the retention period in terms of hours. MongoDB would remove an entry only under the following conditions:
- The Oplog entry is older than the configured number of hours.
- The Oplog has reached the maximum configured size.
Every operation taking place in the MongoDB Oplog is idempotent. This means that these operations give the same results irrespective of whether it has been applied once or many times on the target dataset. Coming to its features, here are a few significant ones:
1) Size
When a Replica Set member is started for the very first time, MongoDB creates an Oplog of a default size unless mentioned otherwise. Here are the sizes for different OS (Operating Systems):


Generally, the default size for the Oplog in MongoDB is more than enough. Putting this in perspective, if an Oplog occupies 5% of the free disk space and fills up in 24 hours of operations, then the secondaries can stop copying the entries from the MongoDB Oplog for another day without having to worry about becoming too stale to continue replication.
You can also specify the size of the Oplog in MongoDB using the ‘oplogSizeMB’ option before its creation. When a Replica Set member has been set for the very first time you can use the ‘replSetResizeOplog’ administrative command to change the size. This allows you to resize it dynamically without having to restart the mongod process.
2) Period
MongoDB doesn’t set a Minimum Retention Period for the Oplog. It automatically truncates it, starting from the oldest entries. This is done to maintain the configured maximum MongoDB Oplog size.
You can configure the Minimum Oplog Retention Period when starting the mongod process through either of the following two steps:
- Adding the ‘–oplogMinRetentionHours’ command-line option.
- Adding the ‘storage.oplogMinRetentionHours’ setting to the mongod configuration file.
Setting the Minimum Retention Period while the mongod is running, overrides any values that you may have set during its startup. You would have to update the value of the corresponding configuration file setting or command-line option to maintain those changes through a server restart.
3) Replication Lag and Flow Control
There exist some situations, where the updates to a secondary’s MongoDB Oplog might lag behind the desired performance time. This is pretty rare, but if and when it occurs you can use ‘db.getReplicationInfo()’ from a secondary member along with the replication status output to assess the current state of replication. This can also help you determine any unwanted replication delays.
As far as flow control goes, in the default state, it is enabled.
4) Collection Behavior
If your MongoDB deployment uses the WiredTiger Storage Engine then you cannot drop the ‘local.oplog.rs’ Collection from any Replica Set member. Starting in version 4.2, you aren’t allowed to drop the local.oplog.rs Collection from a standalone MongoDB instance. In case the node goes down, the mongodb will need the Oplog for both replication and recovery of a node.
Understanding MongoDB Oplog Data Operations
The MongoDB data operations that can be used for data manipulation are Oplog Inserts, Updates, and Deletes. Each operation happens to be idempotent. This bit of information carries weight to understand how the Oplog in MongoDB is interpreted and processed.
1) Insert
This operation lists the inserted document as the value of the ‘o’ field without an ‘o2’ field. In case of a bulk insert or creation of multiple Documents, each Document has a corresponding MongoDB Oplog entry. Here an ‘o’ field will include an ‘_id’ field that corresponds to the document ID.
2) Update
This operation is concerned with updating parts of the Document. Here the ‘o2’ field consists of the ‘_id’ of the updated Document. The operation present in the ‘o’ field is present in the form of ‘$set’ or ‘$unset’. There is no delta or incremental operation in place.
The ‘$set’ record presents the updated final value in place of the increment. For instance, if ‘ {“a”: 1}’ is updated to ‘{“a”: 5}’, the ‘o’ field will be set to ‘{“set”: {“a”: 5}}’. When a field is removed, the ‘$unset’ object contains the name of the field is removed.
3) Delete
As the name suggests, the delete operation is used for deleting all Documents from Collections. This operation does not provide a list of the document contents, unlike the previous two operations. This operation mentions only the object ID of the document in the ‘o’ field.
Understanding MongoDB Oplog Processing
One of the main aspects one should consider while processing an Oplog is streaming changes from MongoDB. You can then generate snapshots for ingesting data into a Data Warehouse or Data Lake. This can also be used directly for any application that you may be working on.
1) Resharding Operations
The ‘fromMigrate’ field in the Oplog entry denotes where the operation belongs. It could be an internal transfer of Documents from one Shard to another. In the Resharding operation, on the original Shard, the delete operation can be seen with ‘fromMigrate: true’. During the same operation, the new Shard can be seen where the insert operations contain ‘fromMigrate: true’.
Interruption of the Resharding operation may leave orphaned documents that won’t be visible unless connected to the Replica Set directly. You can manually update or delete them but there is no robust way of ignoring them completely.
2) Timestamp
In the absence of a library that understands BSON (Binary JSON), the timestamp will be presented in the form of a 64-bit Long number. This can be treated as a serially increasing timestamp similar to Unix time. A BSON timestamp is made up of two parts: time and increments. The time option is a Unix timestamp of seconds since epoch. Increments on the other hand are serially increasing numbers that denote the operation number in the given time.
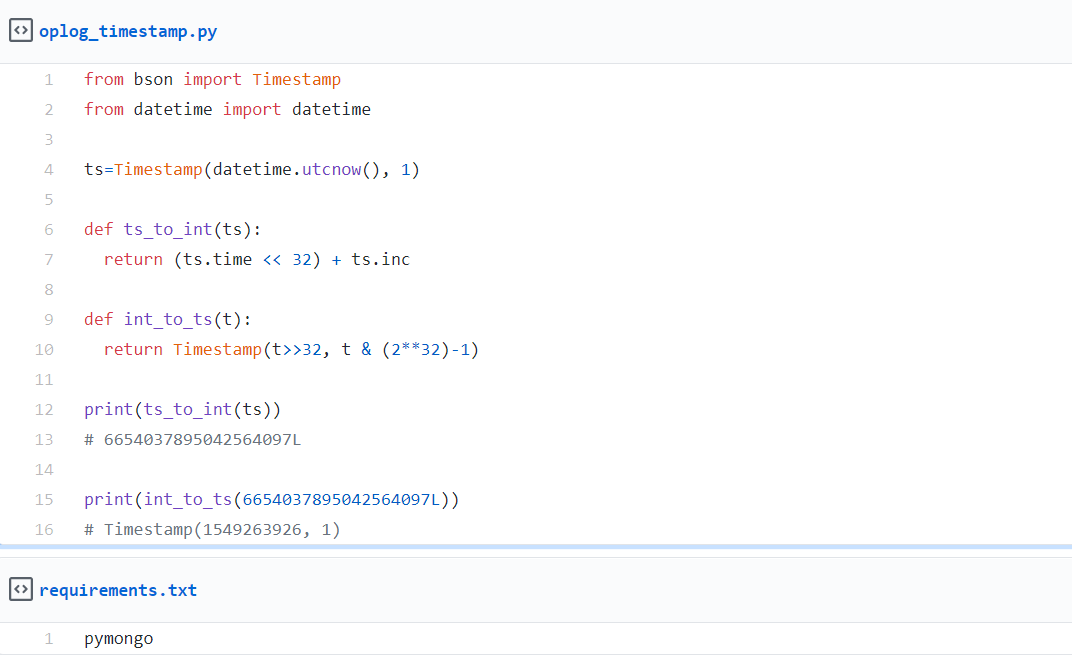
The most significant 32 bits of the BSON timestamp represent the time portion and the least significant 32 bits represent the increment. Computing this in python would look something like the code snippet above.
3) Failovers and Primary Re-elections
As a Distributed Database, MongoDB has the concept of a Master Node that can change over time. There exist multiple strategies to handle this, albeit complex. When tailing the MongoDB Oplog from a primary, a network issue might cause another node to be elected as the new primary while the previous primary steps down eventually. In this scenario, some events may have been read that hadn’t been replicated to another node yet.
This means that when a new primary is elected, these events won’t be a part of the current state of the database. To put it in layman’s terms, the events never happened, but the process tailing the Oplog in MongoDB thinks they did. To further drive the point home, here is a picture to simplify matters. Here events D and E do not exist in the database end state, but the observer believes that they do.

Conclusion
In this article, you were able to wrap your head around the concept of Oplogs in MongoDB, its features, data operations allowed, along with a basic understanding of how the processing works.
Extracting complex data from a diverse set of data sources can be a challenging task and this is where Hevo saves the day! Hevo offers a faster way to move data from Databases or SaaS applications into your Data Warehouse to be visualized in a BI tool. Hevo is fully automated and hence does not require you to code. Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
FAQs
1. Can the Oplog size be changed?
Yes, you can also configure the Oplog size at the time of replica set creation or later by using MongoDB configuration options.
2. How can I use the Oplog for Change Data Capture (CDC)?
Tailing of Oplog enables monitoring and capturing changes in MongoDB, making it useful for real-time applications such as synchronization of data and auditing.
3. What is the purpose of the Oplog in sharded clusters?
There is an Oplog for every shard in a sharded MongoDB cluster so that there could be redundancy and availability of the data set replicated across each node.
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



