




Snowflake’s Data Cloud is based on a cutting-edge Data Platform that is available as Software-as-a-Service (SaaS). Snowflake provides data storage, processing, and analytic solutions that are faster, easier to use, and more adaptable than traditional systems. Snowflake is not based on any current database technology or “Big Data” software platforms like Hadoop. Snowflake, on the other hand, combines a completely new SQL query engine with an innovative Cloud-native architecture.
This article covers topics like an introduction to Snowflake and Zero Copy Clone Snowflake, its advantages, and how to do it.
Table of Contents
What is Snowflake?

- Snowflake is a leading Cloud-computing Data Warehousing startup that will play a key role in AI’s future.
- Snowflake is a Data Warehouse as a Service (DWaaS). It helps businesses to set up and operate a system without relying heavily on DBAs or IT personnel.
- Snowflake provides Data Collection, Analysis, and Analytical solutions that are significantly quicker, easier to use, and more adaptable than traditional systems.
- It helps with System Integration, Business Intelligence, sophisticated analytics, and security and governance, among other things.
- You can clone a table, schema, or even a database in seconds without taking up any space with Snowflake. To put it another way, the cloned table only contains data that differs from the original table.
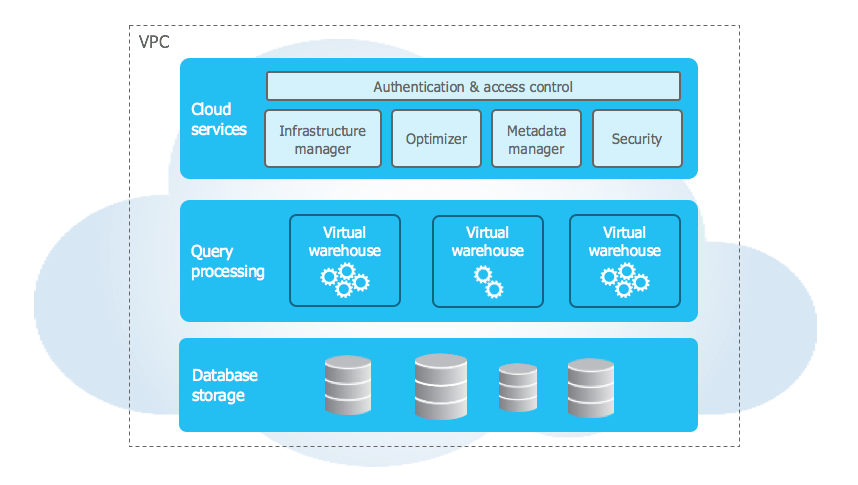
There are three layers to the architecture:
- Cloud Services: The service coordinator and collection.
- Query Processing: The system’s brain, where queries are executed utilizing “Virtual Warehouses”.
- Database Storage: This is where the data is physically stored in columnar mode.
Hevo Data, a No-code Data Pipeline platform, helps to replicate data from 150+ data sources to a destination of your choice, such as Snowflake, and simplifies the ETL process. Check out some of the cool features of Hevo:
- Completely Automated: Set up in minutes with minimal maintenance.
- 24/5 Live Support: Round-the-clock support via chat, email, and calls.
- Schema Management: Automatic schema detection and mapping.
- Live Monitoring: Track data flow and status in real time.
What is Zero Copy Clone Snowflake?
The Snowflake Zero Copy Clone Snowflake function is one of the most powerful features of Snowflake.
- It allows you to take a snapshot of any table, schema, or database at any point in time and generate a reference to an underlining partition that originally shares the underlying storage till you make a change.
- This can be quite useful for quickly producing backups that don’t cost anything extra until the copied object is changed.
- The clone can be replicated an unlimited number of times in Snowflake, with each clone having a piece of shared storage and independent storage.
- Every table in Snowflake has a unique ID that is used to identify it. Similarly, every table has a CLONE GROUP ID, which indicates whether or not the table is cloned. If both columns have a different ID, this table is cloned; otherwise, it is not.
Advantages of Zero Copy Clone Snowflake
The following are some of the advantages of Zero Copy Clone Snowflake:
- Saves you Time: You usually have to wait hours, days, or even weeks to create a test or development environment from a copy of your production data warehouse, And you’re going to have to pay more for a test or development environment that can handle all of the replicated data.
- Snowflake “Fast Clone”: Zero Copy Clone Snowflake is a quick technique that allows you to make many copies of your data without incurring the additional storage expenses associated with data replication, saving you a lot of time.
- Saves Money on Storage: Zero copy clone Snowflake creates a clone of the item without having to reproduce the underlying storage. When a table is cloned, it does not utilize any data storage because it maintains all of the parent database’s existing micro-partitions at the moment of cloning; nonetheless, rows in the clone can be added, deleted, or updated independently of the original table. Each clone update generates new micro-partitions that relate solely to the clone and are safeguarded by CDP.
A Snowflake-native app to monitor Fivetran costs.

Clonable Objects in Zero Copy Clone Snowflake
Before you go into how to clone an object, it’s important to evaluate what objects are cloneable and any limitations. Here is a list of all cloneable objects at the time of writing. A current list may be found in Snowflake’s Cloning Documentation:
- Data Storage Objects such as:
- Databases
- Schemas
- Tables
- Streams
- Data Configuration Objects:
- Stages
- File Formats
- Sequences
Tasks are divided into groups based on how the cloning functionality for each category changes.

What Privileges Are Required in Zero Copy Clone Snowflake?
To clone an item, you must have the bare minimum of permissions. Your current role should have the necessary privilege(s) on the source object to generate a clone:
- Tables: SELECT
- OWNERSHIP OF PIPEWORK, STREAMWORK, AND TASKWORK
- Additional items: USAGE
- In addition, to clone a schema or an object within a schema, your current role should have the requisite privileges on both the source and the clone container object(s).
How to Use Clone in Zero Copy Clone Snowflake?
1. To Clone an Object
A single SQL statement is needed to clone an object in Zero Copy Clone Snowflake:
CREATE <object_type> <object_name>
CLONE <source_object_name>2. To Clone Existing Object to New Object
This statement will clone an existing object to generate a new one. The above is a condensed version of the statement; the full syntax is given below:
CREATE [ OR REPLACE ] { DATABASE | SCHEMA | TABLE | STREAM | STAGE | FILE FORMAT | SEQUENCE | TASK } [ IF NOT EXISTS ] <object_name>CLONE <source_object_name>- With the above command, clone Table A. Clone is generated at stage end with the data accessible in the production table named TABLE A at the time of doing this query.
3. To clone a production database
CREATE DATABASE Dev CLONE Prod;4. To clone a schema
CREATE SCHEMA Dev.DataSchema1 CLONE Prod.DataSchema1;5. To clone a single table
CREATE TABLE C CLONE Dev.public.C;
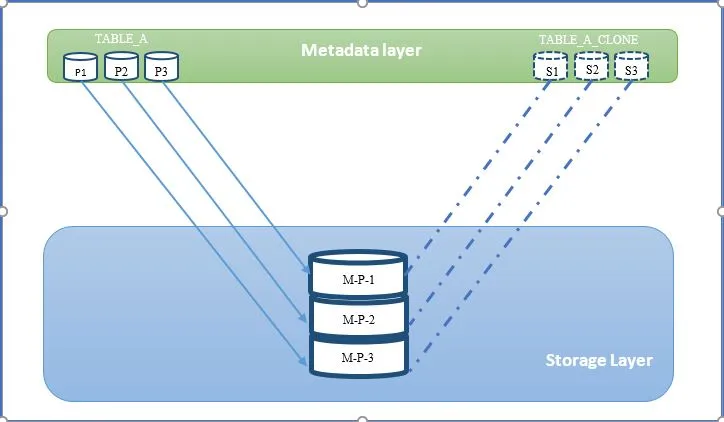
Consider the following diagram:
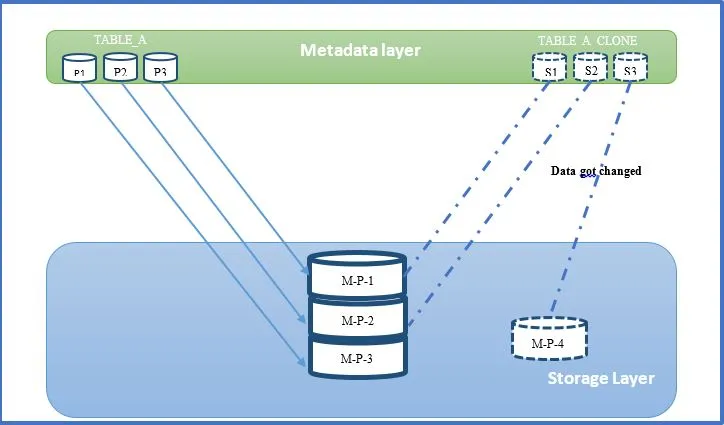
- Let’s imagine your ETL processes were run in a staging environment as part of your integration testing operations, and they inevitably changed some data from TABLE A CLONE.
- Micro Partition -3 is the owner of all of the updated data since this update belongs solely to the Table A clone.
- Snowflake duplicates that modified micro-partition generate a new micro-partition and assign it to the stage environment.
- Snowflake’s micro partitions are immutable. As a result, the variation in stage environment is recorded individually, and metadata will reference the newly generated micro partition, updating TABLE A CLONE as shown below.
Need of Cloning an Object in Zero Copy Clone Snowflake
There are many reasons to clone an item in any Data Warehouse, not just Snowflake. Most cloning occurs for one of three reasons:
- To support a variety of environments, such as development, testing, and backup.
- To test prospective modifications/development without establishing a new environment and without putting the source object at risk.
- To complete a one-time task that makes use of its own source item.
Conclusion
This article explains the Zero Copy Clone Snowflake feature. You can easily accumulate hundreds of terabytes of redundant storage because cloning entire databases for testing is so straightforward. If the Snowflake administrators are aware of the underlying process, you can easily find and remove this storage. This could help us save a lot of money. Cloning a table duplicates the structure, data, and some other aspects of the original table. In cloned tables, the load history of the source table is not kept. Data files can be loaded into clones of a source table if they were previously loaded into the source table.
However, as a Developer, extracting complex data from a diverse set of data sources like Databases, CRMs, Project management Tools, Streaming Services, Marketing Platforms can seem to be quite challenging. If you are from non-technical background or are new in the game of data warehouse and analytics, Hevo Data can help!
Hevo Data will automate your data transfer process, hence allowing you to focus on other aspects of your business like Analytics, Customer Management, etc. This platform allows you to transfer data from 150+ multiple sources to Cloud-based Data Warehouses like Snowflake, Google BigQuery, Amazon Redshift, etc. It will provide you with a hassle-free experience and make your work life much easier.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. You can also have a look at our unbeatable pricing that will help you choose the right plan for your business needs!
FAQs
1. What is the difference between clone and copy in Snowflake?
In Snowflake, a clone creates a duplicate of a database, schema, or table without copying the data physically, while a copy creates a full physical duplication of the data. Cloning is faster and saves storage costs.
2. What cannot be cloned in Snowflake?
Snowflake cannot clone temporary tables, transient objects, external tables, or specific user permissions. Some data configuration objects like network policies also cannot be cloned.
3. Can temporary tables be cloned in Snowflake?
No, temporary tables cannot be cloned in Snowflake. Cloning is only available for permanent and transient tables. Temporary tables are session-based and, thus, non-cloneable.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



