

About PhysicsWallah
Observing the financial implications of many enrolling in expensive online courses, PhysicsWallah focuses on providing affordable education to help students ace various entrance exams.
 What do they do?
What do they do?
 Industry
Industry
 Location
Location
PhysicsWallah is an educational platform that aims to provide high-quality and affordable educational content free of cost or at a minimal cost. It is an app designed for students aspiring to take a wide range of competitive exams in India.
Sandeep Penmetsa works on all things data at PhysicsWallah. His role is to build intelligence to enhance student experience and learning using AI/ML. He focuses on building a robust central data platform to serve business & operational needs. As of January 2023, the Physics Wallah app has been downloaded over 10 million times and has a DAU of 1.5M. Sandeep and his team faced the problem of large volumes of data generated by the system, which needed to be managed effectively and with no data loss. They were on the lookout for a cost-effective and scalable solution to help them manage growing data volumes.

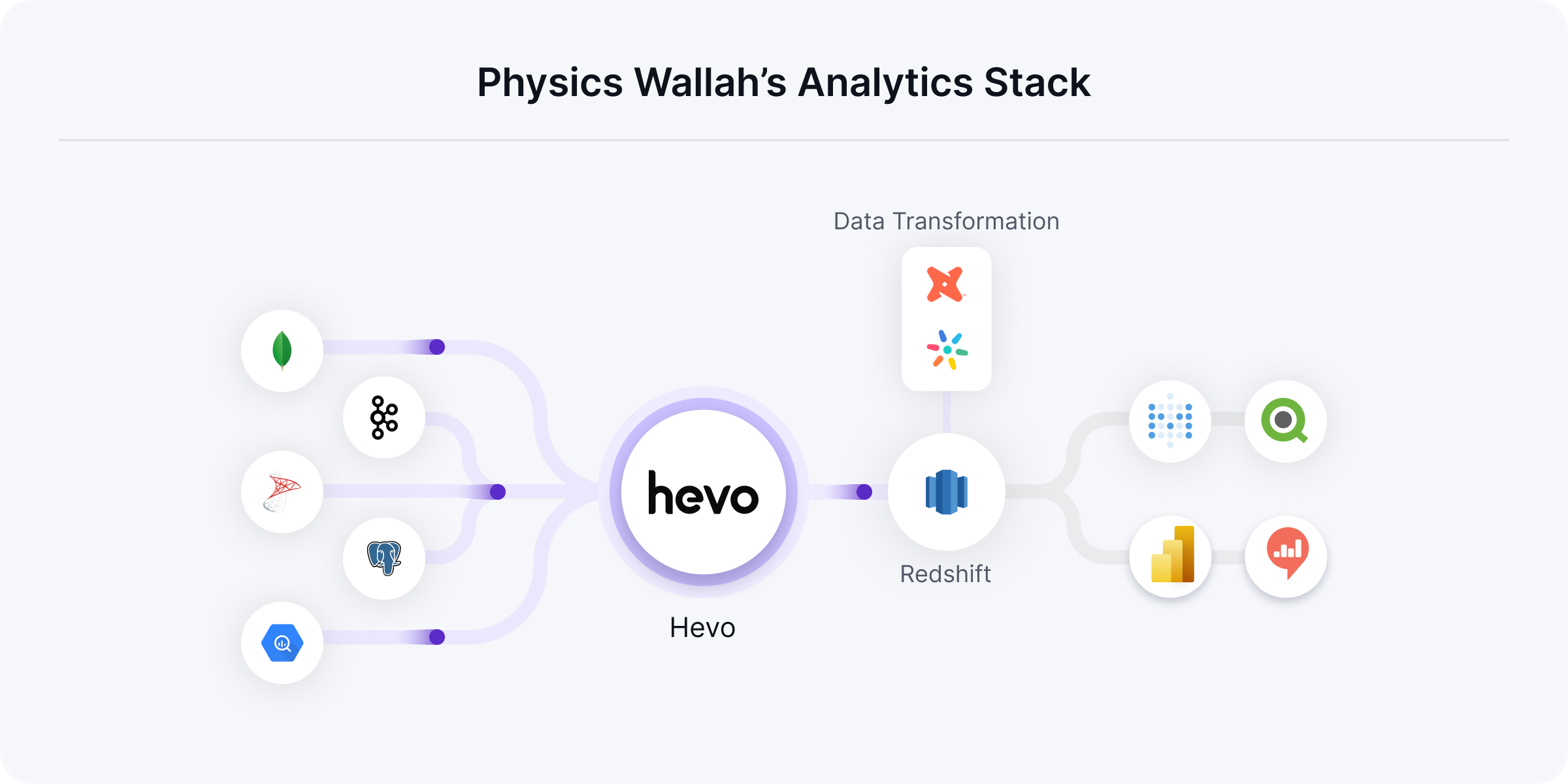
The Problem: Managing a whopping 600 tables with Python batch jobs
Due to the low cost of the app offering high-quality education, PhysicsWallah has a 1.5M DAU and MAU of ~12M and hence has a massive scale of data. Business teams in PW are dependent on the data team to ingest all the business and operational data from various databases like MongoDB, PostgreSQL, and MS SQL to create daily reports and dashboards in the warehouse. Over 1,000 people across teams access these reports. The main challenge for the data team when building their data stack was to handle the volume and concurrency of the data.
Before Hevo was brought into the picture, the analytics team would pull data from primary sources. This would increase resource utilization, thus impacting real-time users. Due to this, the application used to stopped responding very frequently. Additionally, they initially relied on Python batch jobs for their priority tables, around 30 in number. However, they had around 600 tables in total, and managing them internally was a pain.
That is when they started their journey with Hevo Data to set up a warehouse and build a robust ELT system quickly.
The Solution: Using Hevo Data to set up pipelines at scale
PW evaluated Hevo and Airbyte for their ETL needs and discovered that Hevo was the better option for their high-priority workloads that required low latency. Additionally, Sandeep had already used Hevo Data at a previous organization- Slice- which is a FinTech company that also had to deal with large data volumes. He remembered the ease and speed with which Hevo was implemented to handle the data at Slice.

I worked at a fintech startup Slice from 2016 to 2020, and I was one of the early members in using Hevo there. Given how fast we were able to implement Hevo there, thus enabling multiple analytics teams, it was obvious to me to implement the same solution here as well. Hevo helped us deliver things at a great pace and in a very scalable manner.
Sandeep was highly pleased with Hevos’ performance at PW as well. The experience with Hevo Data has been seamless and supports the data needs in a variety of ways.
Hevo’s hybrid schema mapping helps throw alerts for schema changes and customize the destination schema.
Pre-load transformations help unpivot data from their nested architecture for priority tables.
Important tables are prioritized within the platform, ensuring they are loaded quickly and with adequate resources.
Observability and monitoring of data flow became easy using Slack alerts and other monitoring options, so failure management became easy.
The support is impeccable, often working with them through odd hours to ensure that the pipelines are running very smoothly.
Now, Sandeep and his team enable all teams across the organization to access large volumes of data easily and quickly. They use dbt along with Hevo models to easily model their data and BI tools like Qliksense and Metabase for visualizations. A much larger number of tables can now be operationalized for analysis and provide a well-rounded view of crucial metrics. They can now easily generate key reports like academic analytics reports and product analytics reports.
The Impact: Boosting customer experience with lower effort
The impact of onboarding Hevo Data has been huge for PhysicsWallah. There has been a large amount of time and effort saved, allowing the data team to focus on more critical projects. There has also been a huge downstream business impact of integrating all the data into the warehouse.
Hevo saves the work of 3-4 engineers for the building and monitoring of data pipelines, as they were able to literally plug and leave the data pipelines. In other words, they saved over 90% of the time they would have spent on this activity at a nominal cost.
Hevo plays a pivotal role currently. We started with 200M events per month and are currently moving 1.5B events per month. That just shows how Hevo helped us in fastracking the ELT process, thus empowering multiple teams and unlocking the data potential to enhance student learning and experience.
Over 500 analysts use the data that is transferred to their DW, from where they create product and academic analytics reports. These reports are used to improve the customer experience and the questions answered by the SST team. Through product and academic decisions backed by data, PhysicsWallah has been able to make critical improvements to the app. Data always back the product changes, and the outcomes are reflected in the smiles on customer faces- the NPS score of PW has increased by over 50% in their recent customer survey!
Excited to see Hevo in action and understand how a modern data stack can help your business grow? Sign up for our 14-day free trial or register for a personalized demo with our product expert.