About Postman
Postman is the world’s leading API platform. Postman's features simplify each step of building an API and streamline collaboration to help create better APIs—faster. More than 30 million developers and 500,000 organisations across the globe use Postman today.
 What do they do?
What do they do?
 Industry
Industry
 Location
Location
Postman is the world’s leading API platform. Postman's features simplify each step of building an API and streamline collaboration to help create better APIs faster.
Since the company was first founded in 2014, they have had a sharp focus on creating a data-driven culture. Hence, teams across Postman always have a very data-backed way of thinking about the decisions they make. Dashboards are built in such a way that each team can start their day looking at the data in a self-serve manner. The data team, meanwhile, gets involved in larger, newer, or more advanced projects and dashboard requests. Over 70% of the organization interacts with data directly each month.

Existing data stack
Prudhvi, Head of Data at Postman, joined the organization over 4 years ago and has been on a constant quest to streamline and improve their data stack. Besides tracking their major metrics of active users and ARR, they have 3 main applications for their data:
Analytics: Postman uses a lot of their data for day-to-day decision-making.
Client reporting: for enterprise customers, Postman offers reporting services powered by their warehouse.
Production services: Services like their recommendation engine, search engine, etc, are powered by different types of transformed data.
The production data from the Postman platform is powered by MySQL or DocumentDB, while SaaS sources like Stripe, Zendesk, Twitter, etc. are also used to collect various points of customer information. dbt is then used to stitch different types of data together to create a 360° view of the customer from these various platforms.
The diverse data requirements and the number of data sources require a solid foundational data stack to keep things running. Unfortunately, 1.5 years ago, Postman faced a number of issues with their previous third-party data integration tool, with issues keeping up with the API updates and not having many feature improvements. Due to this, at least half a day of engineering work would go into repairing and developing solutions for the missing features, every single time there was a breakage.
Such issues had widespread consequences for the business, especially within such a data-driven one. There was a lack of continuity and trust in the data, and, at times, entire teams would have to come to a standstill due to a lack of data.
There was also an issue of a lack of connector breadth in their previous tool. In a fast-growing and data-led organization like Postman, new data sources are always being added to the stack.
With their previous tool, setting up pipelines for new data sources was often a time-consuming process for the Postman data team. Although supported features could be configured swiftly, any unsupported requirements meant manually constructing pipelines from scratch - a process that routinely demanded 3-4 working days due to the tool's constraints.
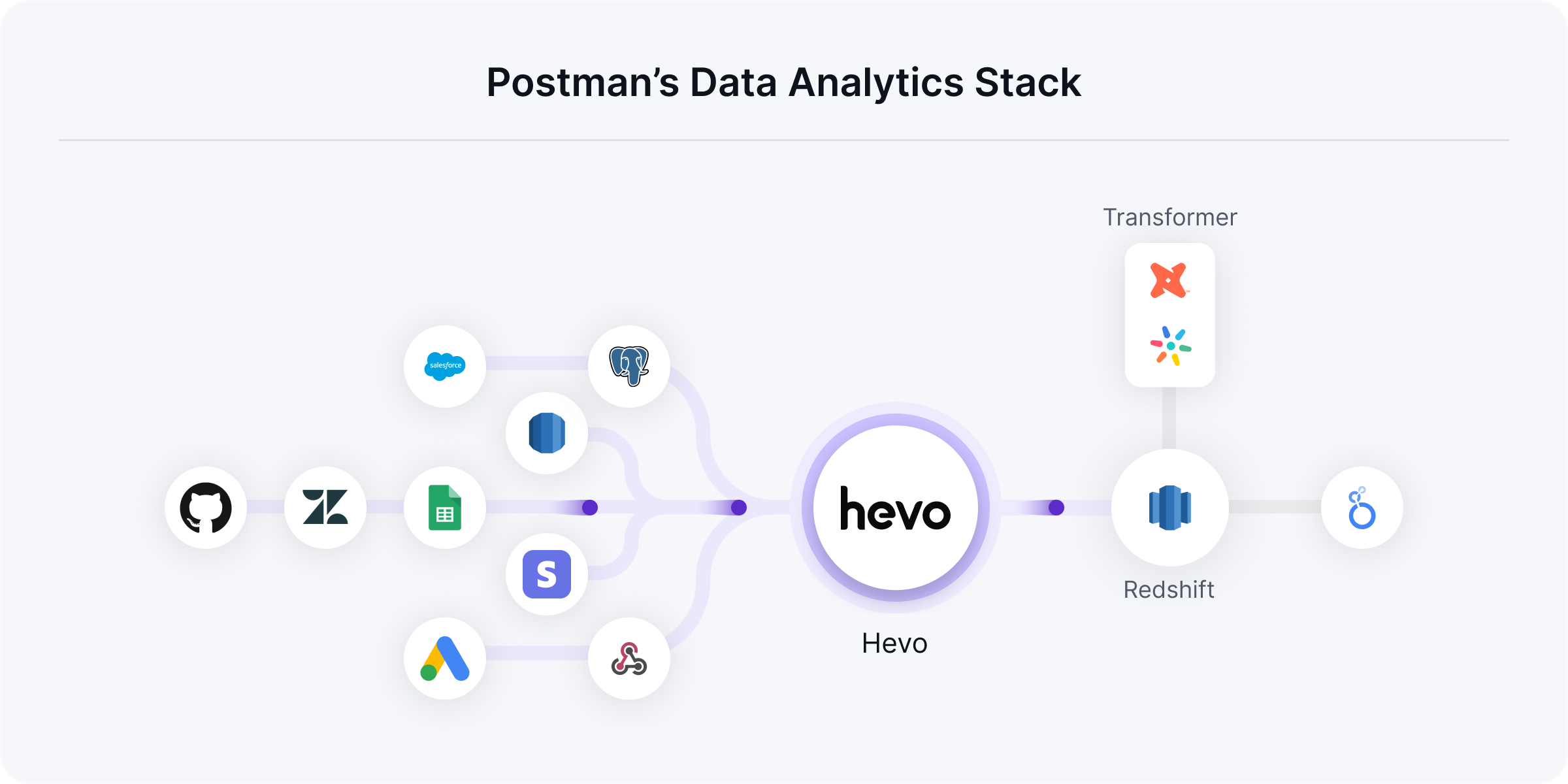
The journey to crafting a perfect data stack

We did a proper evaluation between Hevo and its competitors. We realized that Hevo provided the best value out of all of them; it had all the features that we wanted at a price that we were comfortable with. It was the best option for us.
This was when Prudhvi went on the lookout for a new tool that would solve their problems. He wanted to find a tool that was reliable, would have pre-built connectors for a majority of the sources that he was using, and would keep up to date with API changes and other updates to their pipelines.
The main criteria the team was looking for were:
Data source coverage
How fresh and up-to-date the tool is with the APIs for third-party tools
Easy data ingestion pipeline creation and robust Role-Based Access Control (RBAC)
At this time, Prudhvi considered two leading data integration tools, one of which was Hevo Data. Though both tools were comparable in their features, Postman felt very drawn to the vision of Hevo Data. They felt that Hevo had a clear intent to play a long-term game with data, which aligned with his goal to build a data ecosystem at Postman that would be solid for years to come. He also got a much better response from Hevo Data.
Hence, Postman was assured that they would save countless man-hours with Hevo, and the evaluation phase of the product, as well as the excellent dollar-to-value that he found with Hevo, cemented his choice.
An evolved data stack
In the 1.5 years of using Hevo, Postman has had an exceedingly seamless experience, with any initial challenges or issues being promptly resolved by the Hevo team. This is a far cry from the days when pipeline breakages were a semi-constant issue and a real concern for the team. Analysts with limited experience in building pipelines can get a new source up and running within an hour, thanks to Hevo’s easy-to-use no-code interface.
30-40 developer hours are saved per month due to using Hevo, out of which over 10 hours are saved just on fixing breakages! Prudhvi is also very happy with the coverage of connectors, as he has a large number of sources - over 40 currently.
Hevo has great coverage, they keep their integrations fresh, and the tool is super reliable and accessible. The team was very responsive as well, always ready to answer questions and fix issues. It’s been a great experience!
The long-term vision of Hevo, to enable data-driven decisions for businesses in a reliable and scalable manner, really resonated with Prudhvi as someone who understands the importance of building a robust data foundation that can last for years. He is extremely happy to see Hevo turning that vision into reality for his organization and for countless others worldwide!
Excited to see Hevo in action and understand how a modern data stack can help your business grow? Sign up for our 14-day free trial or register for a personalized demo with our product expert.