About Redcliffe Labs
Redcliffe Labs provides diagnostics with a comprehensive portfolio approach both with routine and specialized test menus with advanced testing labs all over India. Its digital-first approach with on-demand 1-hour home collection and same-day report is disrupting the way diagnostics is delivered today and thus is the fastest growing in India. Redcliffe Labs is providing 3500+ tests across its wide network of labs and collection centers.
 What do they do?
What do they do?
 Industry
Industry
 Location
Location
Redcliffe Labs is revolutionizing healthcare and disrupting diagnosis services in India by adopting a digital-first approach and maximizing data usage. Established in 2018 with a mission to make quality diagnostics accessible and affordable, today, they serve 180 cities, catering to over 2.5 million people.
A steadfast emphasis on efficiency and scale was their key to transforming the diagnostic process, which was possible by unlocking real-time data at every step of the customer journey and enabling stakeholders to make quicker and optimized decisions.


Our focus is to deliver fast, quality healthcare at an affordable cost that can be achieved only by being digital-first, digitizing the complete process where data plays a vital role.
Data Challenges
The customer journey in a diagnostic service is operation-heavy, with multiple stakeholders and touchpoints involved. In the case of Redcliffe Labs, they have 17-18 stakeholders across the journey - from acquiring a customer, appointment booking, allocating delivery person, and collecting samples to the delivery of the diagnostic report. And they have multiple customer booking channels like one-click online booking, calls, and Whatsapp.
To optimize decisions and drive operations with razor-sharp efficiency, stakeholders at each touchpoint need access to relevant insights for their specific roles.
During the initial days, the data generated was only a mere quarter of the magnitude it has reached today. They used PostgreSQL as a single data source, with every stakeholder having access to the entire data and being able to make data-driven decisions.
However, as Redcliffe Labs expanded to multiple cities, the volume of data and the number of data sources increased, causing gaps in data and insights and creating a need to merge all the data for impactful and comprehensive insights. Today, around 200-250 datasets are updated for every booking.
Additionally, the wide accessibility of data within each business process posed a security risk, as sensitive information was vulnerable, creating a need to build a limited view for each stakeholder.
To overcome these challenges, Prabhat and his team decided to adopt a modern data stack with Snowflake as the data warehouse. The next step was to move all data from its various sources and tools into Snowflake.
Initially, they attempted to replicate data using a Kafka cluster; however, it proved to be a resource-intensive and time-consuming process that drained valuable engineering hours and crippled efficiency. Recognizing the need for a more efficient solution, Prabhat started looking for a plug-and-play solution to automate data replication and unlock near-real-time insights for all stakeholders.
The Solution
After consulting with industry peers and evaluating several ELT tools, Prabhat and his team decided to use Hevo Data to automate their data replication process to Snowflake.
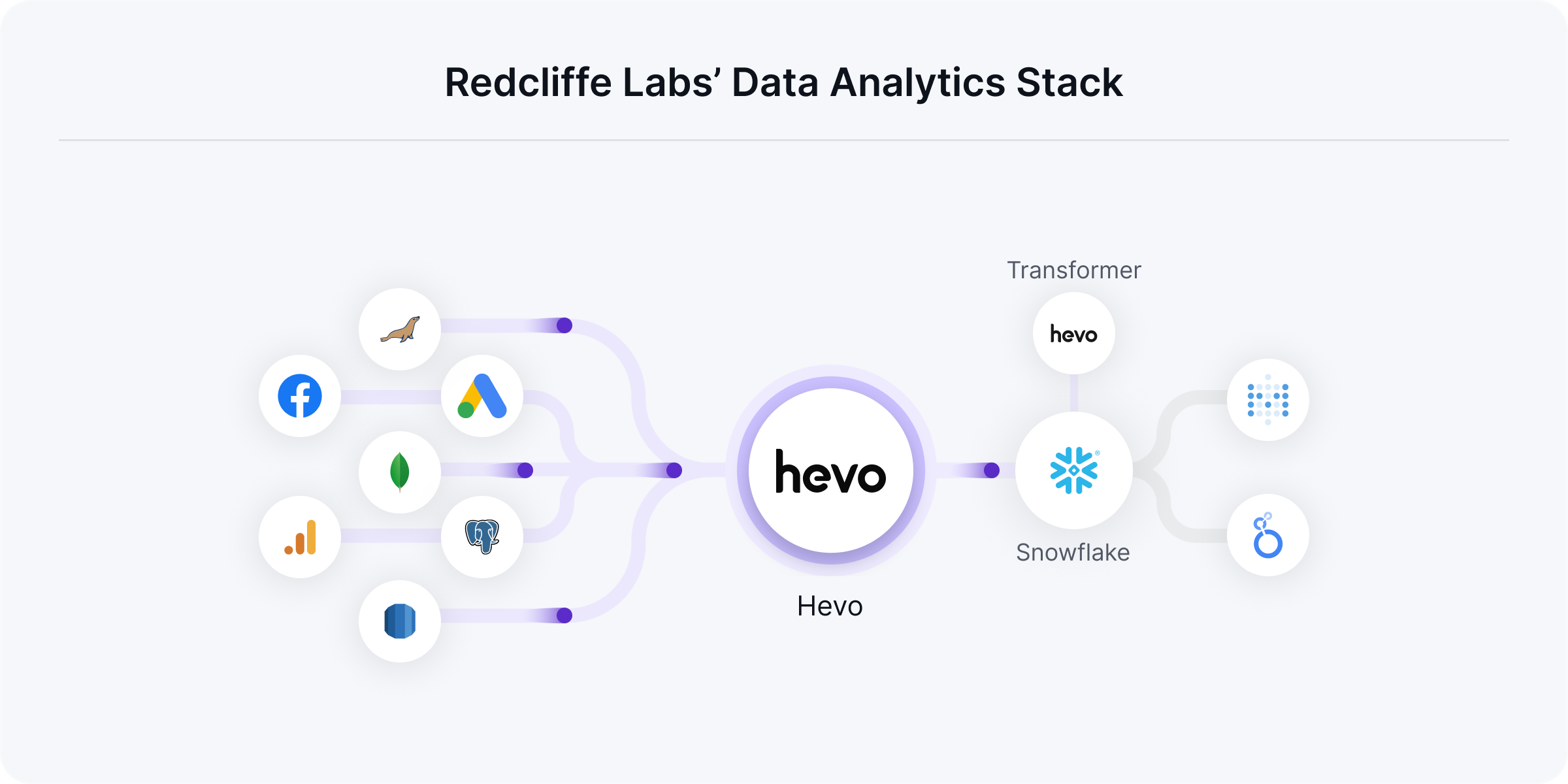
Using Hevo Data’s plug-and-play connectors, Mukesh at Redcliffe seamlessly integrated data generated across various touchpoints and departments (such as sales, marketing, operations, etc.) from their respective tools into Snowflake. This included campaign data from multiple advertising platforms like Facebook Ads, Google Ads, WhatsApp chat data recorded in MariaDb, website event data from Google Analytics, booking data stored in MongoDB, and more.
Now, we have the ability to merge various data sets to obtain relevant information at the right time while ensuring that sensitive information is not accessible to BI users.
Hevo Data's pre-load transformation enables Mukesh to remove the sensitive data points at the source itself, and the in-built post-load transformation capabilities make it simple for him to merge relevant tables and create customized reports and limited views specific to each stakeholder and department (with only the insights they need), which is built on Metabase and Looker.
The marketing team can now closely track over 200 campaigns and make informed decisions to improve campaign performance, while the sales team is equipped with the necessary information to interact effectively with leads and insights to increase re-bookings. The operations team has a comprehensive view of every booking, allowing them to quickly assign the nearest collection agents.
Furthermore, the verification team, communication team, lab team, and others now have access to the insights they require to deliver a smooth customer experience in an optimized and efficient manner.
Key Results
By adopting a modern data stack and Hevo Data, Redcliffe is gaining near-real-time access to data from diverse sources and channels, allowing them to make informed decisions with lightning-fast insights across the customer journey. Thus, operating at military-level efficiency and delivering timely and high-quality diagnoses at an affordable price.
Redcliffe offers their customers a remarkable TAT (turn around time) of 12 hours from receiving a booking to delivering the report, with a 96% success rate. Without the modern data stack and Hevo Data's automated data replication capabilities, this rate would have been around 75%.
This marks Redcliffe as a truly data-driven and digital-first organization!
We performed a time comparison for building pipelines in-house versus with Hevo; it took 8 hours in-house but only 15 minutes with Hevo.
Not only is this outcome a testament to being truly data-driven, but it's also done without putting stress on Mukesh or the engineering team. Instead, it saves Mukesh's bandwidth for deeper insights and analysis. With Hevo Data, Mukesh can set up a data pipeline in just 10-15 minutes, compared to the 8 hours he would have spent creating and managing pipelines without Hevo.
Mukesh loves the user-friendly interface of Hevo Data, with features like a workbench and in-built transformations giving him more freedom to explore data and discover new insights. Prabhas, Abhishek, and Mukesh are also extremely impressed with Hevo Data's excellent customer service and feel secure about their pipelines.
Excited to see Hevo in action and understand how a modern data stack can help your business grow? Sign up for our 14-day free trial or register for a personalized demo with our product expert.