

About Cure.Fit
CureFit is a health and fitness company offering digital and offline experiences across fitness, nutrition, and mental well-being through its 3 products, i.e, cult.fit, eat.fit & mind.fit. Cure.fit takes a holistic approach towards health and fitness by bringing together all aspects of a healthy lifestyle on a single platform.
 What do they do?
What do they do?
 Industry
Industry
 Location
Location
Meet Swati and Abhishek who are a part of Cure.fit’s data team. Swati works as a Lead Engineer and owns the entire lifecycle of Data, from raw to analytics. Whereas Abhishek is a Solution Engineer and he is responsible for integrating data across different sources, writing relevant transformations, and mapping the output to the data warehouse.
Swati is actually one of Hevo’s first customers and has been a power user of Hevo for a very long time. She has seen Hevo evolve and improve over the years, and she is always excited about trying out newly released features of Hevo.

Data Challenges
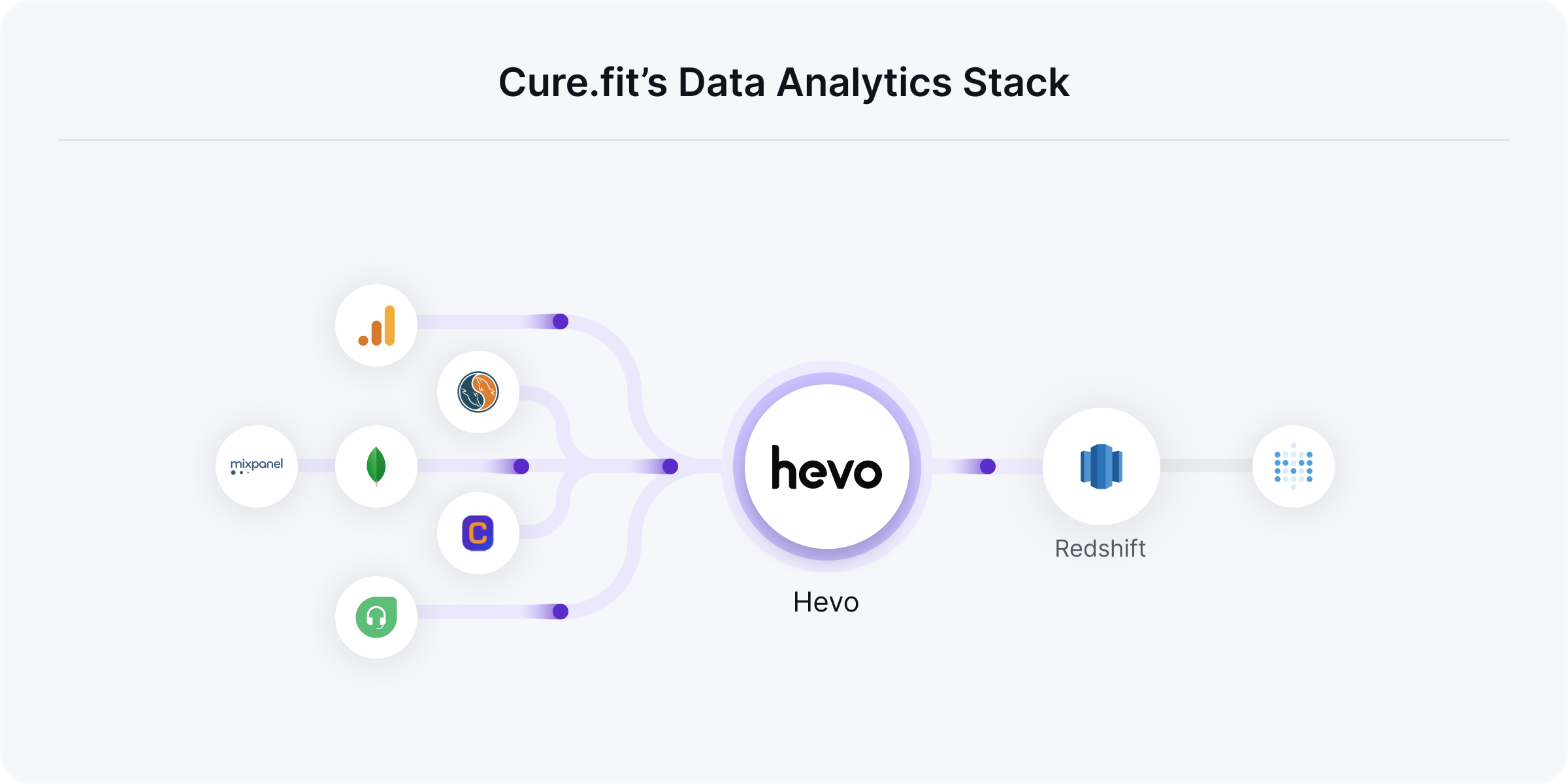
At Cure.fit, Abhishek and team were collecting loads of data generated by their app, offline centers, Databases like MongoDB, MySQL, systems like Google Analytics, CleverTap, Freshdesk, Mixpanel, and more. But, all this data was inaccessible by the majority of the teams. They were battling the same bottleneck problem many companies confront: A situation where only a few people can access the data, and the rest will have to wait to get their questions answered. This put the Data Platform team under the limelight.

We would literally slog to generate the reports needed by the Business teams making us the bottleneck.
Here’s how Abhishek and team’s overall process looked like:
The data team would gather data from multiple sources, write complex scripts to transform data, build data pipelines, and move data to their warehouse, Redshift.
They would then run a custom python script on Redshift to pull data, build reports and email this across to the business teams.
They would also handle all the changes/exceptions that occur at the source or destination to ensure data is flowing into the warehouse and with no data loss.
The data teams were literally swamped with tons of data requests drowning them in an array of data pulls all-day-long.
As a growing company, the engineering team would roll out new experiments regularly, causing changes at the source’s end. This made us stay on our toes at all points as we had to handle any exception or the data would not flow. The majority of the team’s bandwidth would be taken by data cleaning and transformation processes as certain systems like MongoDB are tricky to handle. This gave very little room for us to do more with Analytics. We threw our hands up. We needed to do something about this.
The Solution
Cure.fit was on a hunt for a modern tool that would simplify their data integration problem. Since one of their verticals, eat.fit stored the majority of data on MongoDB, they were particularly interested in a tool that would simplify the flattening of a nested Mongo event. Most of the products that they evaluated continued to show glitches with MongoDB. Additionally, Data loss issues also cropped up.
When I saw Hevo, I was amazed by the smoothness with which it worked so many different sources with zero data loss.
When Cure.fit settled on Hevo it took them only about two weeks to set the entire system up. Abhishek worked on connecting the sources, writing relevant transformations, and mapping the output to Redshift. Additionally, the team also built custom Data Models on Hevo that reflected on Redshift, ensuring that all business users are accessing the single source of truth.
Hevo nullified the dependency between the Data team and the business teams. Through a front-end reporting tool (Metabase), the teams now build their own reports on data made available by Hevo.
It was great. All I had to do was do a one-time setup and the pipelines and models worked beautifully. Data was no more the bottleneck.
Key Results
We can now generate over 100 reports daily, Thanks to Hevo. This is a 5X growth from before. Business teams are wowed by the speed and accuracy at which we operate!
Today, about 500 business users track their core metrics through the data made available by Hevo. The data team can now generate numerous in-depth reports drilling down on specifics on a daily basis. The freed-up bandwidth is being used to focus on bigger analytics projects, warehouse optimization, and more.
Hevo notifies me over slack and email every time something needs my attention. That is the only time I invest in maintaining this system. The support team at Hevo is amazing. With a turn around time of fewer than 10 mins, they make it easy for me to fix the problem and move on without having to disturb any workflow.
Cure.fit is now one of India’s largest players in the Health, Fitness, and Wellness sector. Hevo is proud to be a part of this journey by helping them realize their data potential.
Excited to see Hevo in action and understand how a modern data stack can help your business grow? Sign up for our 14-day free trial or register for a personalized demo with our product expert.