Set up in just few clicks
Configure your source and data warehouse in just a few clicks. Set up and maintain your data pipelines without writing a single line of code. Get analytics-ready data in your fingertips.

 4.4 (250+ reviews)
4.4 (250+ reviews)
Hevo combines extraction, loading, and dbt-based modeling into a single platform with detailed operational visibility across all data sources.
Configure your source and data warehouse in just a few clicks. Set up and maintain your data pipelines without writing a single line of code. Get analytics-ready data in your fingertips.
Configure your source and data warehouse in just a few clicks. Set up and maintain your data pipelines without writing a single line of code. Get analytics-ready data in your fingertips.


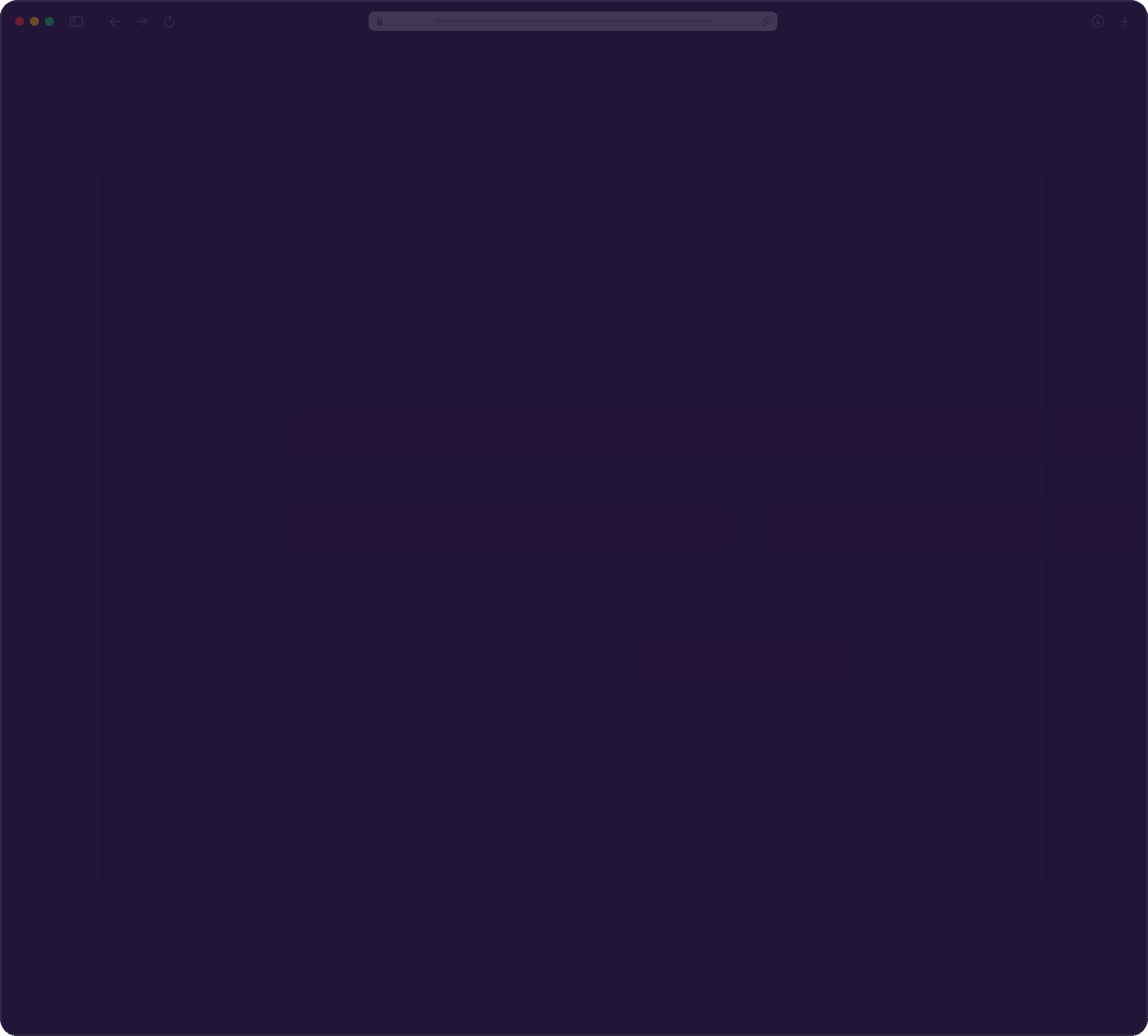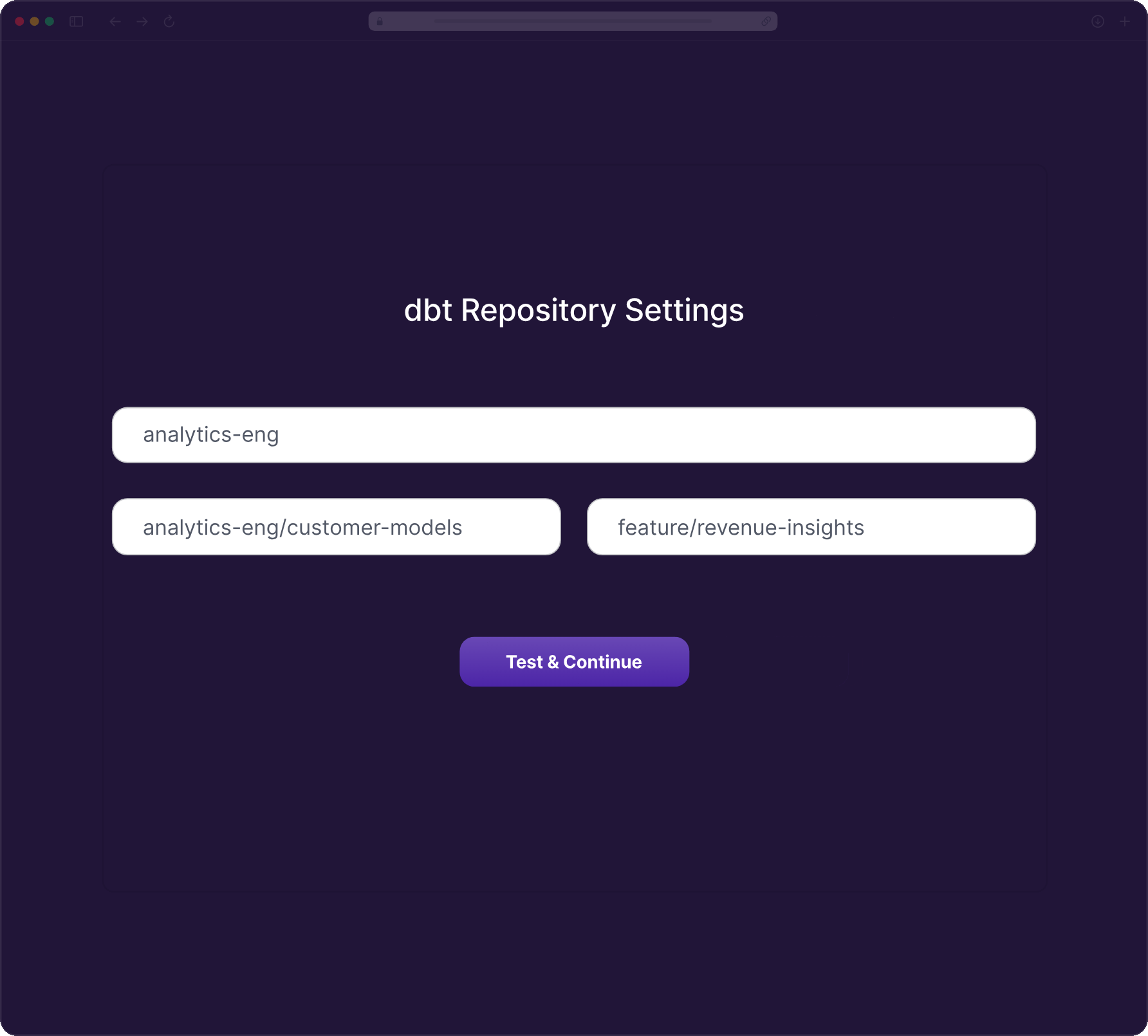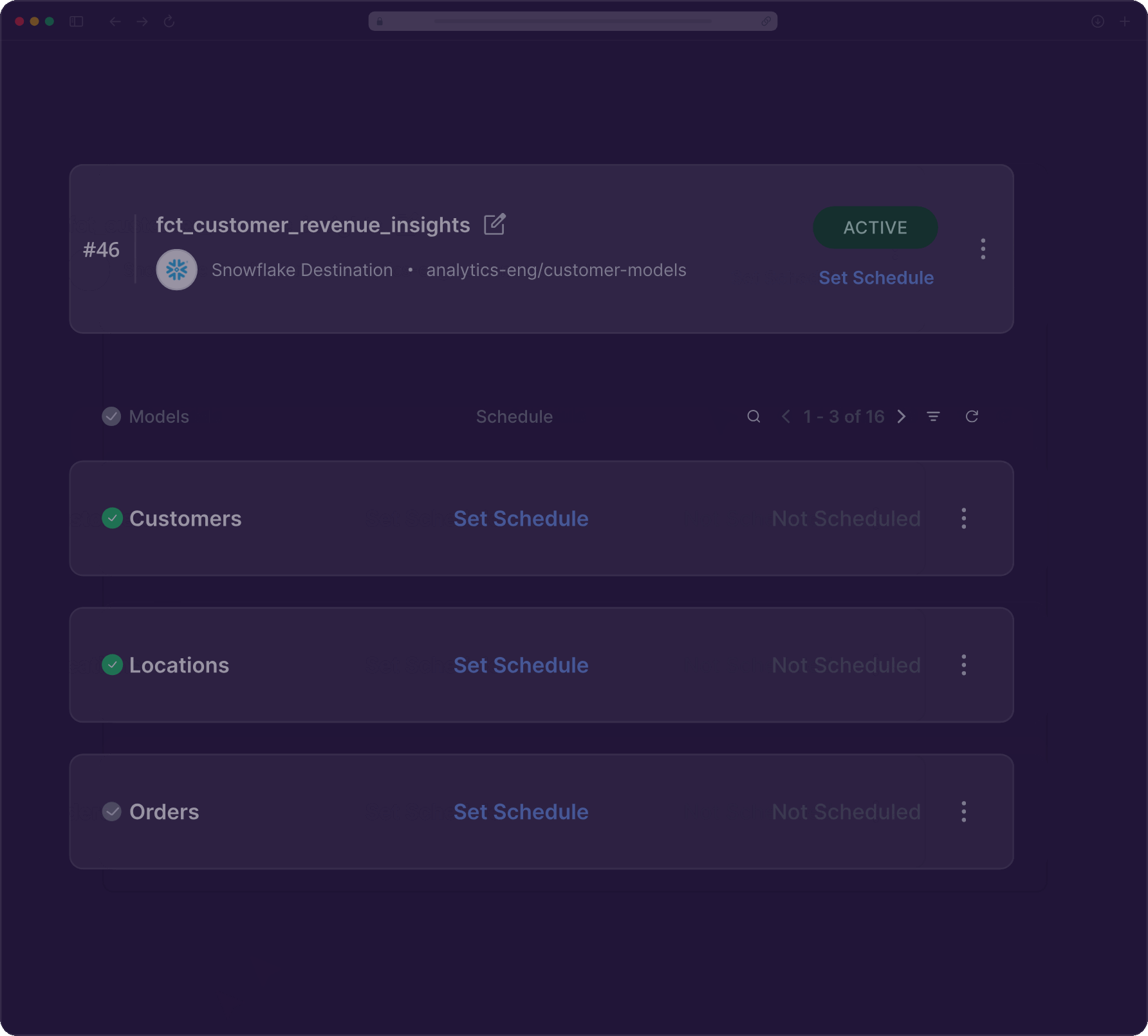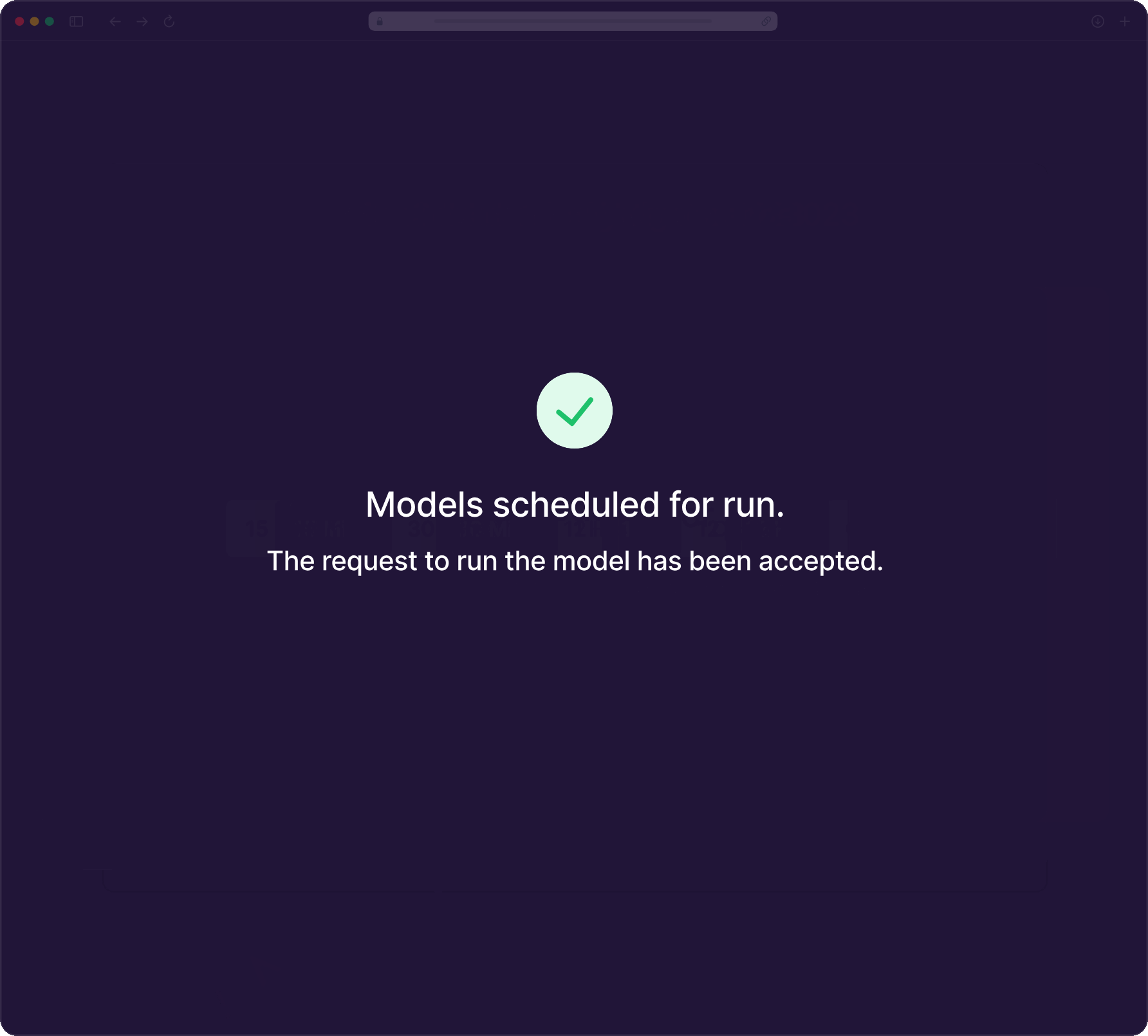
Use Python scripting, dbt models and a low-code GUI to craft precise transformations that ensure your data is always query-ready at the destination.
Use Python scripting, dbt models and a low-code GUI to craft precise transformations that ensure your data is always query-ready at the destination.
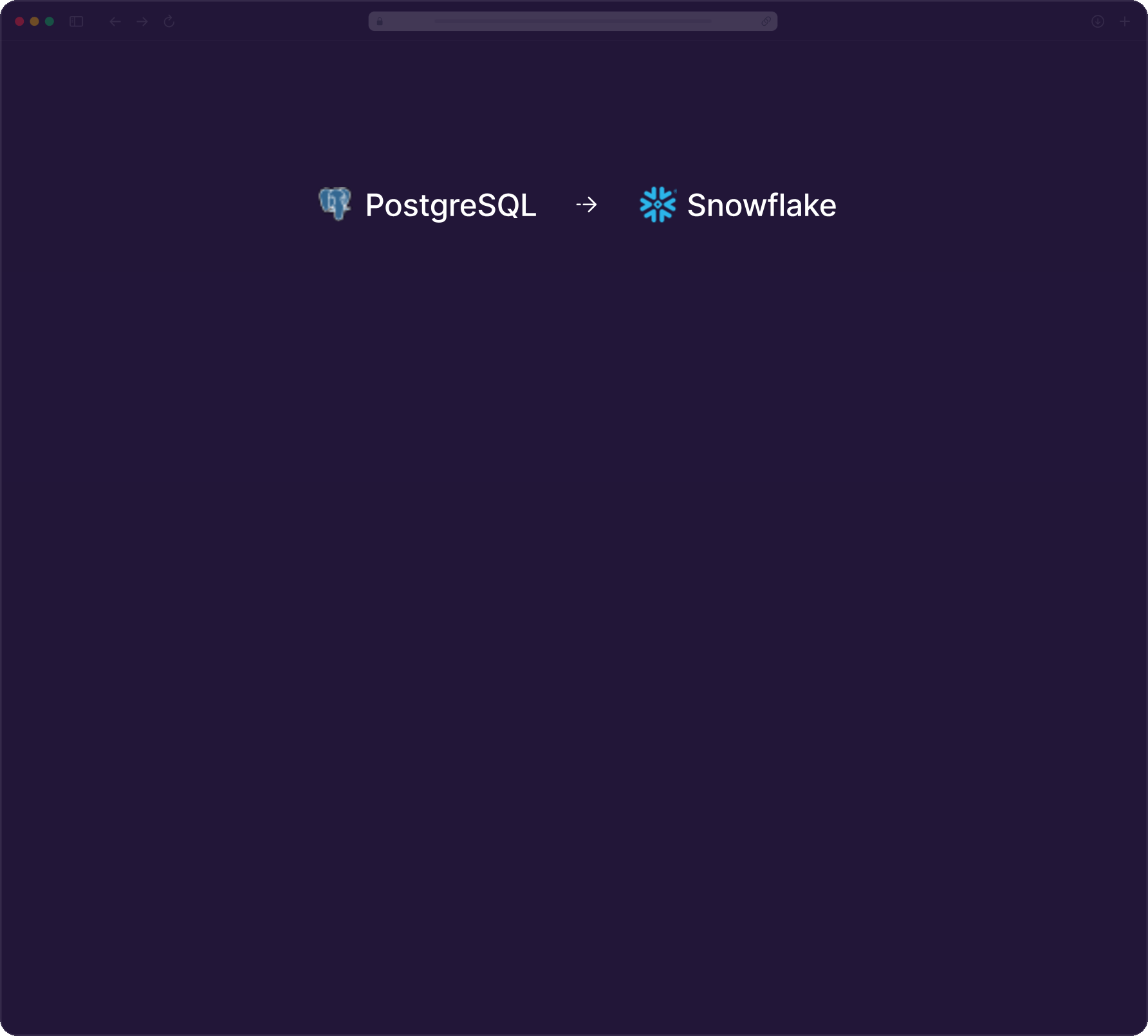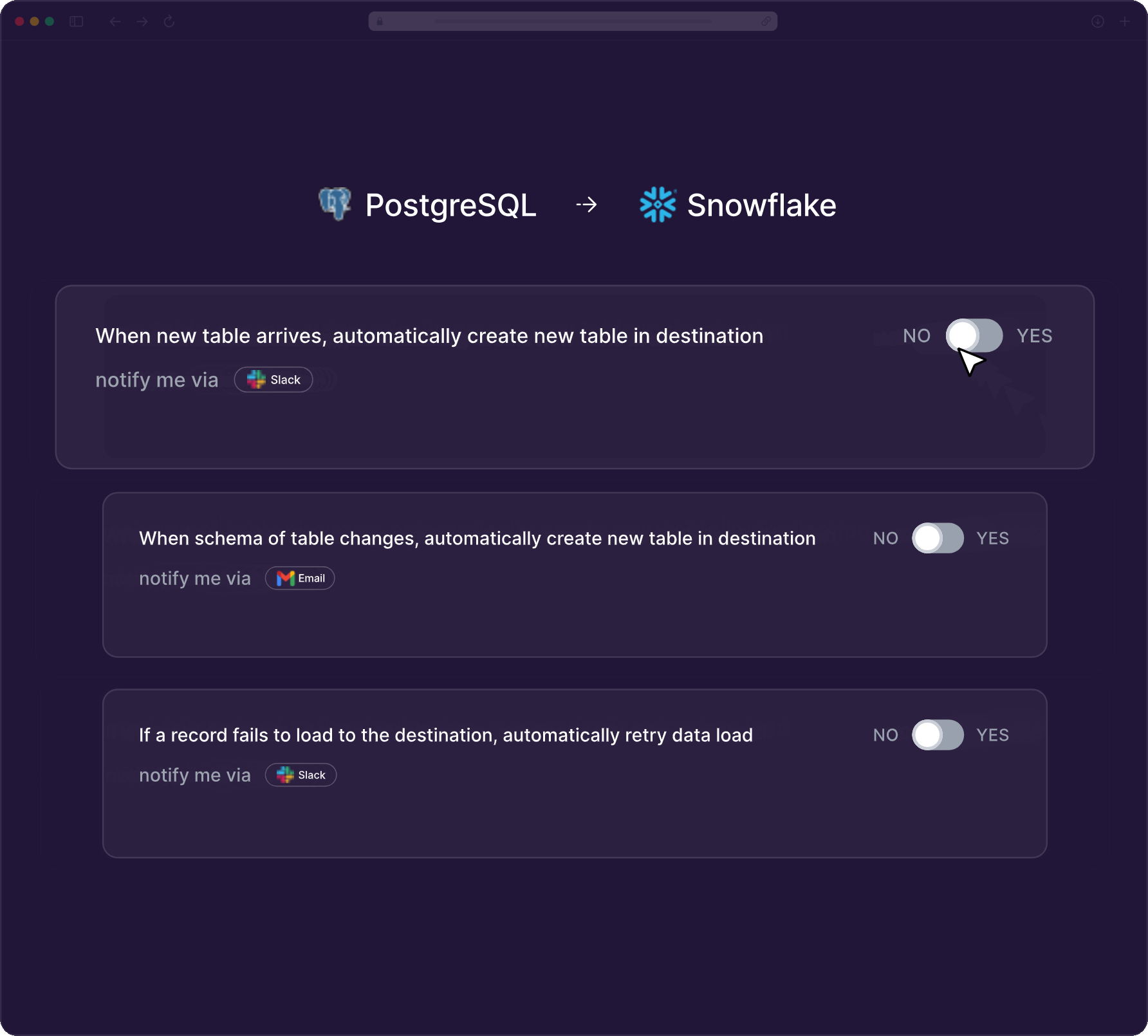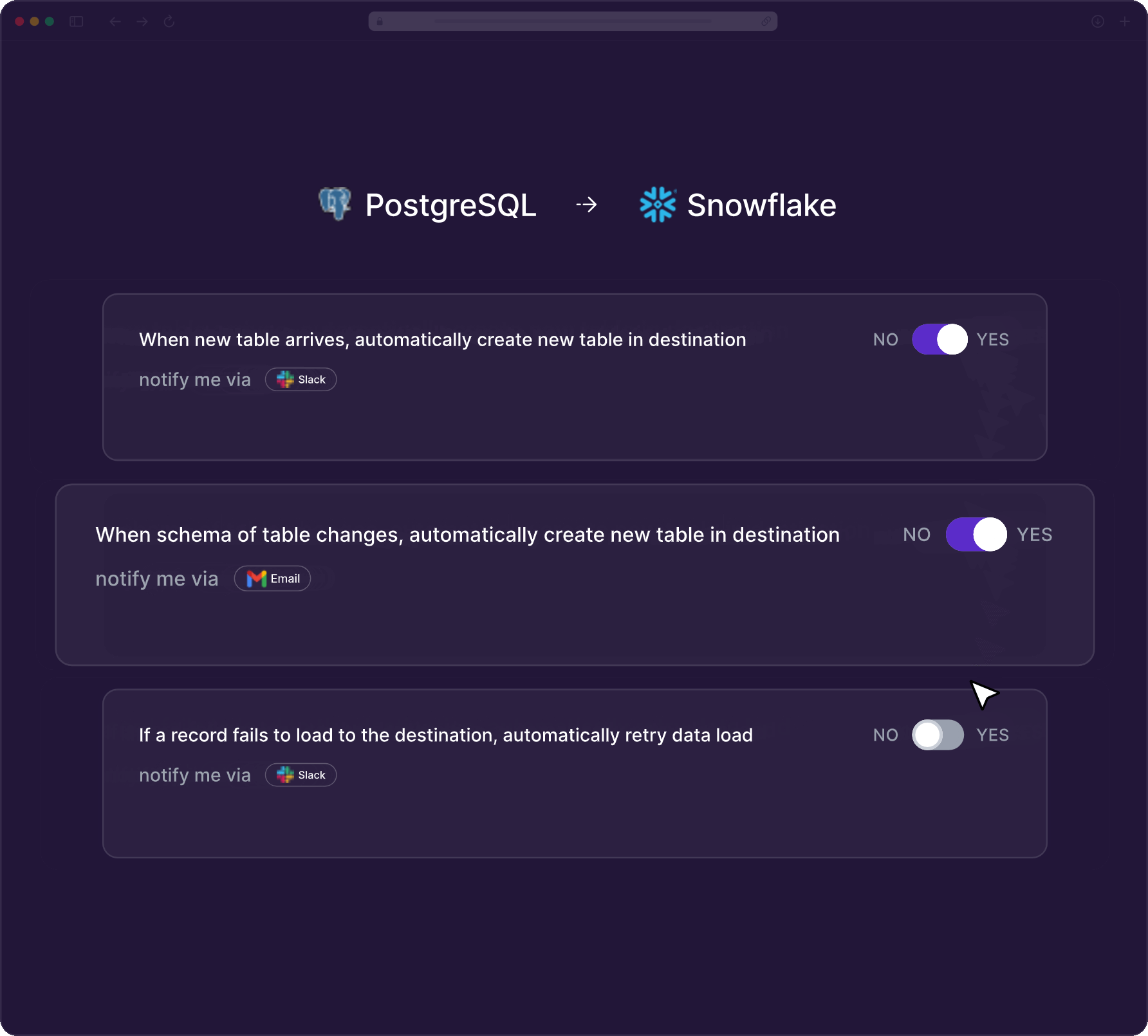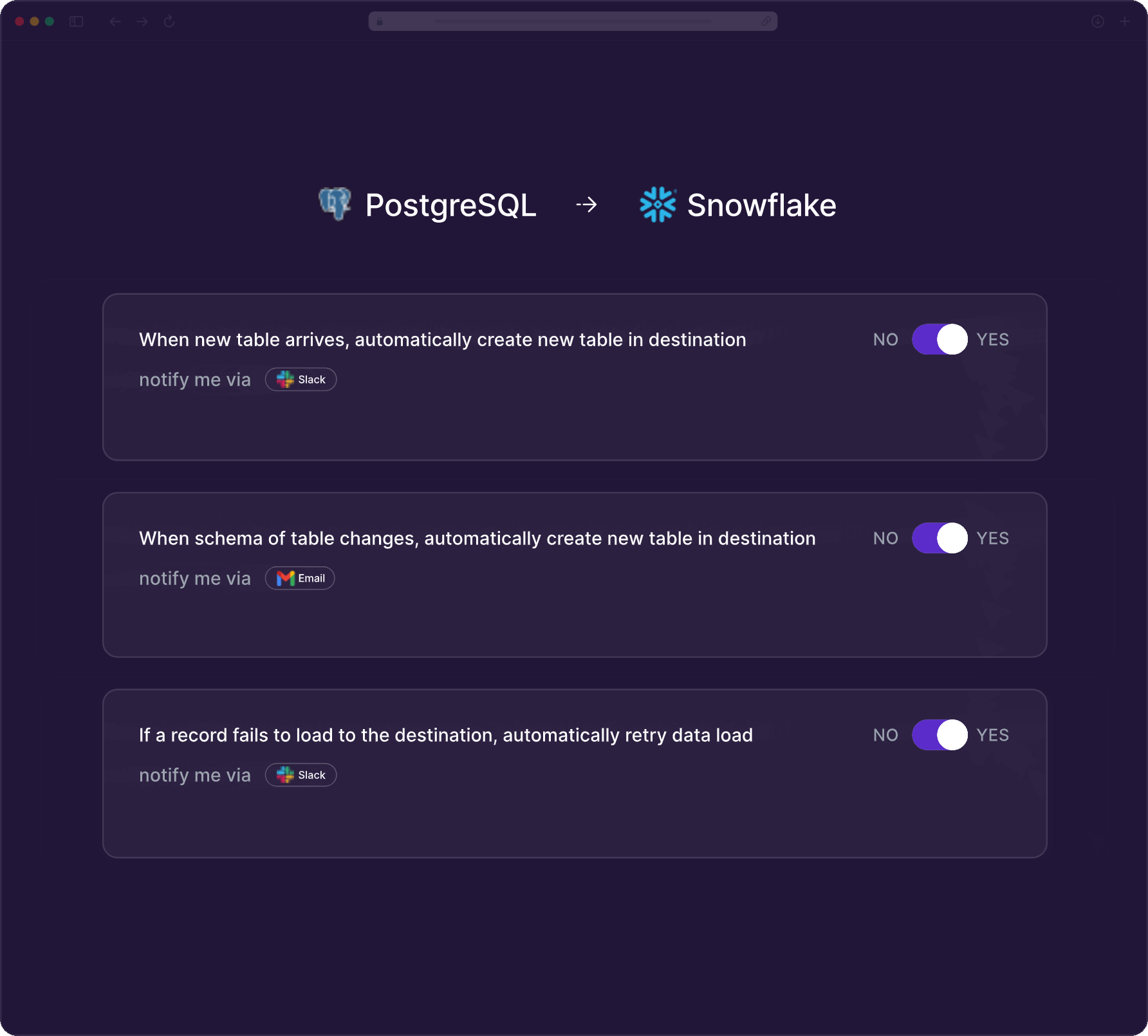
Automatically handle schema drifts and intelligently recover record failures. Get proactive alerts on changes. No manual intervention needed.
Automatically handle schema drifts and intelligently recover record failures. Get proactive alerts on changes. No manual intervention needed.







Observe every pulse of your pipeline in real time. Get granular visibility into system-level operations through logs.

Move billions of records with unparalleled speed and precision. Handle data spikes without a hiccup.

Efficiently manage pipelines with APIs, deploy with CI/CD, and seamlessly orchestrate advanced workflows.
Observe every pulse of your pipeline in real time. Get granular visibility into system-level operations through logs.
Move billions of records with unparalleled speed and precision. Handle data spikes without a hiccup.
Efficiently manage pipelines with APIs, deploy with CI/CD, and seamlessly orchestrate advanced workflows.