
In the Data Warehousing and Business Analysis environment, growing businesses have a rising need to deal with huge volumes of data. In cases like this, key stakeholders often debate on whether to go with Redshift or with Athena – two of the big names that help seamlessly handle large chunks of data. This blog aims to ease this dilemma by providing a detailed comparison of Redshift Vs Athena.
Although both the services are designed for Analytics, both the services provide different features and optimize for different use cases. This blog covers the following:
Hevo Data, an automated data pipeline, helps load data from over 150 sources onto the desired destination, such as Amazon Redshift. It transforms it into an analysis-ready form without writing a single line of code.
Here’s how Hevo can help:
- Security: Hevo’s fault-tolerant architecture ensures data is handled securely and consistently with zero loss.
- Live Support: The Hevo team is available 24/5 to extend exceptional support to its customers through chat, email, and support calls.
- Incremental Data Load: Hevo allows the transfer of modified data in real-time, ensuring efficient bandwidth utilization on both ends.
Explore why Scale Media uses a combination of Hevo, Redshift & Sisense to fulfill their analytics needs.
Get Started with Hevo for FreeTable of Contents
Amazon Redshift Vs Athena – Brief Overview
Amazon Redshift Overview
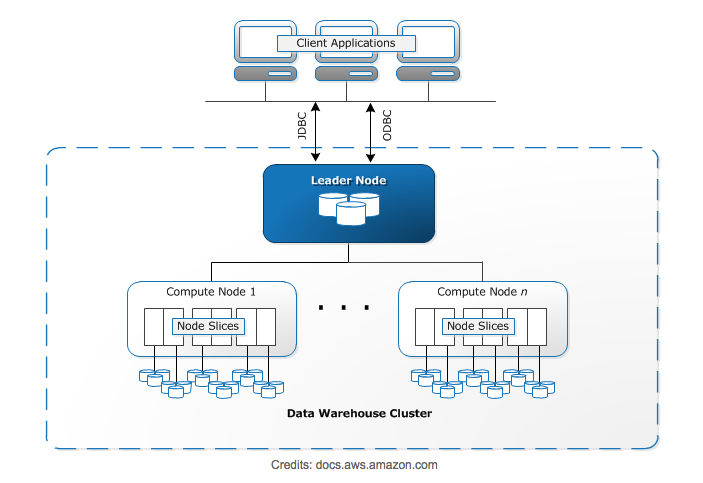
Amazon Redshift is a fully managed, petabyte data warehouse service over the cloud. Redshift data warehouse tables can be connected using JDBC/ODBC clients or through the Redshift query editor.
Redshift comprises Leader Nodes interacting with Compute nodes and clients. Clients can only interact with a Leader node. Compute nodes can have multiple slices. Slices are nothing but virtual CPUs
Athena Overview
Amazon Athena is a serverless Analytics service to perform interactive queries over AWS S3. Since Athena is a serverless service, the user or Analyst does not have to worry about managing any infrastructure. Athena query DDLs are supported by Hive and query executions are internally supported by Presto Engine. Athena only supports S3 as a source for query executions. Athena supports almost all the S3 file formats to execute the query. Athena is well integrated with AWS Glue Crawler to devise the table DDLs
Redshift Vs Athena Comparison
Feature Comparison
Amazon Redshift Features
Redshift is purely an MPP data warehouse application service used by the Analyst or Data warehouse engineer who can query the tables. The tables are in columnar storage format for fast retrieval of data. You can watch a short intro on Redshift here:
Data is stored in the nodes and when the Redshift users hit the query in the client/query editor, it internally communicates with Leader Node. The leader node internally communicates with the Compute node to retrieve the query results. In Redshift, both compute and storage layers are coupled, however in Redshift Spectrum, compute and storage layers are decoupled.
Athena Features
Athena is a serverless analytics service where an Analyst can directly perform the query execution over AWS S3. This service is very popular since this service is serverless and the user does not have to manage the infrastructure. Athena supports various S3 file-formats including CSV, JSON, parquet, orc, and Avro. Along with this Athena also supports the Partitioning of data. Partitioning is quite handy while working in a Big Data environment
Redshift Vs Athena – Feature Comparison Table
| Feature Type | Redshift | Athena |
| Managed or Serverless | Managed Service | Serverless |
| Storage Type | Over Node (Can leverage S3 for Spectrum) | Over S3 |
| Node types | Dense Storage or Dense Compute | NA |
| Mostly used for | Structured Data | Structured and Unstructured |
| Infrastructure | Requires Cluster to manage | AWS Manages the infrastructure |
| Query Features | Data distributed across nodes | Performance depends on the query hit over S3 and partition |
| UDF Support | Yes | No |
| Stored Procedure support | Yes | No |
| Maintenance of cluster needed | Yes | No |
| Primary key constraint | Not enforced | Data depends upon the values present in S3 files |
| Data Type supports | Limited support but higher coverage with Spectrum | Wide variety of support |
| Additional consideration | Copy command
Node type Vacuum Storage limit | Loading partitions
Limits on the number of databases Query timeout |
| External schema concept | Redshift Spectrum Shares the same catalog with Athena/Glue | Athena/Glue Catalog can be used as Hive Metastore or serve as an external schema for Redshift Spectrum |
Scope of Scaling
Both Redshift and Athena have an internal scaling mechanism.
Amazon Redshift Scaling
Since data is stored inside the node, you need to be very careful in terms of storage inside the node. While managing the cluster, you need to define the number of nodes initially. Once the cluster is ready with a specific number of nodes, you can reduce or increase the nodes.
Redshift provides 2 kinds of node resizing features:
- Elastic resize
- Classic resize
Elastic Resize
Elastic resize is the fasted way to resize the cluster. In the elastic resize, the cluster will be unavailable briefly. This often happens only for a few minutes. Redshift will place the query in a paused state temporarily. However, this resizing feature has a drawback as it supports a resizing in multiples of 2 (for dc2.large or ds2.xlarge cluster) ie. 2 node clusters changed to 4 or a 4 node cluster can be reduced to 2, etc. Also, you cannot modify a dense compute node cluster to dense storage or vice versa.
This resize method only supports VPC platform clusters.
Classic Resize
Classic resize is a slower way of resizing a cluster. Your cluster will be in a read-only state during the resizing period. This operation may take a few hours to days depending upon the actual data storage size. For classic resize you should take a snapshot of your data before the resizing operation.
Workaround for faster resize -> If you want to increase 4 node cluster to 10 node cluster, perform classic resize to 5 node cluster and then use elastic resize to increase 10 node cluster for faster resizing.
Athena Scaling
Being a serverless service, you do not have to worry about scaling in Athena. AWS manages the scaling of your Athena infrastructure. However, there is a limit on the number of queries, databases defined by AWS ie. number of concurrent queries, the number of databases per account/role, etc.
Ease of Data Replication
Amazon Redshift – Ease of Data Replication
In Redshift, there is a concept of the Copy command. Using the Copy command, data can be loaded into Redshift from S3, Dynamodb, or EC2 instances. Although the Copy command is for fast loading it will work at its best when all the slices of nodes equally participate in the copy command


Below is an example:
copy table from 's3://<your-bucket-name>/load/key_prefix'
credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' Options;You can load multiple files in parallel so that all the slices can participate. For the COPY command to work efficiently, it is recommended to have your files divided into equal sizes of 1 MB – 1 GB after compression.
For example, if you are trying to load a file of 2 GB into DS1.xlarge cluster, you can divide the file into 2 parts of 1 GB each after compression so that all the 2 slices of DS1.xlarge can participate in parallel.
Please refer to AWS documentation to get the slice information for each type of Redshift node.
Using Redshift Spectrum, you can further leverage the performance by keeping cold data in S3 and hot data in the Redshift cluster. This way you can further improve your performance.
In case you are looking for a much easier and seamless means to load data to Redshift, you can consider fully managed Data Integration Platforms such as Hevo. Hevo helps load data from any data source to Redshift in real-time without having to write any code.
Athena – Ease of Data Replication
Since Athena is an Analytical query service, you do not have to move the data into Data Warehouse. You can directly query your data over S3 and this way you do not have to worry about node management, loading the data, etc.
Data Storage Formats Supported by Redshift and Athena
Redshift data warehouse only supports structured data at the node level. However, Redshift Spectrum tables do also support other storage formats ie. parquet, orc, etc.
On the other hand, Athena supports a large number of storage formats ie. parquet, orc, Avro, JSON, etc. It also has a feature called Glue classifier. Athena is well integrated with AWS Glue. Athena table DDLs can be generated automatically using Glue crawlers too. Glue has saved a lot of significant manual tasks of writing manual DDL or defining the table structure manually. In Glue, there is a feature called a classifier.
Using the Glue classifier, you can make Athena support a custom file type. This is a much better feature that made Athena quite handy dealing in with almost all the types of file formats.
Data Warehouse Performance
Redshift Data Warehouse Performance
The performance of the data warehouse application is solely dependent on the way your cluster is defined. In Redshift, there is a concept of Distribution key and Sort key. The distribution key defines the way how your data is distributed inside the node. The distribution key drives your query performance during the joins. Sort key defines the way data is stored in the blocks. The more the data is in sorted order the faster the performance of your query will be.
Sort key can be termed as a replacement for an index in other MPP data warehouses. Sort keys are primarily taken into effect during the filter operations. There are 2 types of sort keys (Compound sort keys and Interleaved sort keys). In compound sort keys, the sort keys columns get the weight in the order the sort keys columns are defined. On the other hand in the compound sort key, all the columns get equal weightage. Interleaved sort keys are typically used when multiple users are using the same query but are unsure of the filter condition
Another important performance feature in Redshift is the VACUUM. Bear in mind VACUUM is an I/O intensive operation and should be used during the off-business hours. However, off-late AWS has introduced the feature of auto-vacuuming however it is still advised to vacuum your tables during regular intervals. The vacuum will keep your tables sorted and reclaim the deleted blocks (For delete operations performed earlier in the cluster). You can read about Redshift VACUUM here.
Athena Performance
Athena Performance primarily depends on the way you hit your query. If you are querying a huge file without filter conditions and selecting all the columns, in that case, your performance might degrade. You need to be very cautious in selecting only the needful columns. You are advisable to partition your data and store your data in columnar/compressed format (ie. parquet or orc). In case you want to preview the data, better perform the limit operation else your query will take more time to execute.
Example:-
Select * from employee; -- High run time
Select * from employee limit 10 -- better run timeAmazon Redshift Vs Athena – Pricing
AWS Redshift Pricing
The performance of Redshift depends on the node type and snapshot storage utilized. In the case of Spectrum, the query cost and storage cost will also be added
Here is the node level pricing for Redshift for the N.Virginia region (Pricing might vary based on region)
| Node type | Storage per node | Pricing |
| dc2.large | 0.16TB SSD | $0.25 per Hour |
| dc2.8xlarge | 2.56TB SSD | $4.80 per Hour |
| ds3.large | 2TB HDD | $0.85 per Hour |
| ds2.8xlarge | 16TB HDD | $6.80 per Hour |
AWS Athena Pricing
The good part is that in Athena, you are charged only for the amount of data for which the query is scanned. Your query needs to be designed such that it does not perform unnecessary scans. As a best practice, you should compress and partition the data to save the cost significantly
The usage cost of N.Virginia is $5 per TB of data scanned (The pricing might vary based on region)
Along with the query scan charge, you are also charged for the data stored in S3
Architecture
Athena – Architecture
Athena is a serverless platform with a decoupled storage and compute architecture that allows users to query data directly in S3 without having to ingest or copy it. It is multi-tenant and uses shared resources. Users have no control over the compute resources that Athena allocates from the shared resource pool per query.
Amazon Redshift Architecture
The oldest architecture in the group is Redshift, which was the first Cloud DW. Its architecture was not built to separate storage and computation. While it now has RA3 nodes, which allow you to scale compute and only cache the data you need locally, it still runs as a single process. Because different workloads cannot be separated and isolated over the same data, it lags behind other decoupled storage/computing architectures. Redshift is deployed in your VPC as an isolated tenant per customer, unlike other cloud data warehouses.
Scalability
Athena – Scalability
Athena is a multi-tenant shared resource, so there are no guarantees about the amount or availability of resources allocated to your queries. It can scale to large data volumes in terms of data volume, but large data volumes can result in very long run times and frequent time outs. The maximum number of concurrent queries is 20. Athena is probably not the best choice if scalability is a top priority.
Redshift – Scalability
Even with RA3, Redshift’s scale is limited because it can’t distribute different workloads across clusters. While it can automatically scale up to 10 clusters to support query concurrency, it can only handle 50 queued queries across all clusters by default.
Use Cases
Athena – Use Cases
For Ad-Hoc analytics, Athena is a great option. Because Athena is serverless and handles everything behind the scenes, you can keep the data where it is and start querying without worrying about hardware or much else. When you need consistent and fast query performance, as well as high concurrency, it isn’t a good fit. As a result, it is rarely the best option for operational or customer-facing applications. It can also be used for batch processing, which is frequently used in machine learning applications.
Redshift – -Use Cases
Redshift was created to help analysts with traditional internal BI reporting and dashboard use cases. As a result, it’s commonly used as a multi-purpose Enterprise data warehouse. It can also use the AWS ML service because of its deep integrations into the AWS ecosystem, making it useful for ML projects. It is less suited for operational use cases and customer-facing use cases like Data Apps, due to the coupling of storage and compute and the difficulty in delivering low-latency analytics at scale. It’s difficult to use for Ad-Hoc analytics because of the tight coupling of storage and compute, as well as the requirement to pre-define sort and dist keys for optimal performance.
Data Security
Amazon Redshift – Data Security
Redshift has various layers of security
- Cluster credential level security
- IAM level security
- Security group-level security to control the inbound rules at the port level
- VPC to protect your cluster by launching your cluster in a virtual networking environment
- Cluster encryption -> Tables and snapshots can be encrypted
- SSL connects can be encrypted to enforce the connection from the JDBC/ODBC SQL client to the cluster for security in transit
- Has facility the load and unload of the data into/from the cluster in an encrypted manner using various encryption methods
- It has a feature of CloudHSM. With the help of CloudHSM, you can use certificates to configure a trusted connection between Redshift and your HSM environment
Athena: Data Security
You can query your tables either using console or CLI
Being a serverless service, AWS is responsible for protecting your infrastructure. Third-party auditors validate the security of the AWS cloud environment too.
At the service level, Athena access can be controlled using IAM.
Below is the encryption at rest methodologies for Athena:
- Service side encryption (SSE-S3)
- KMS encryption (SSE-KMS)
- Client-side encryption with keys managed by the client (CSE-KMS)
Security in Transit
- AWS Athena uses TLS level encryption for transit between S3 and Athena as Athena is tightly integrated with S3.
- Query results from Athena to JDBC/ODBC clients are also encrypted using TLS.
- Athena also supports AWS KMS to encrypted datasets in S3 and Athena query results. Athena uses CMK (Customer Master Key) to encrypt S3 objects.
Redshift vs Athena: Which One Should You Choose?
Amazon Athena and Amazon Redshift are both cloud-based solutions for querying data on Amazon S3 using SQL, but they are designed for different purposes. Here’s a comparison to help you decide which is right for you:
- Data Structure: Athena is great for analyzing unstructured data in S3, while Redshift works best with structured data in clusters.
- Data Location: With Redshift, data needs to be moved into the cluster before analysis, while Athena queries data directly from S3.
- Setup Time: Athena is ready to use right away, whereas Redshift requires time to initialize clusters before queries can run.
- Partitioning: Athena offers more flexible partitioning, allowing partitions based on any key, while Redshift has more rigid partitioning.
- Pricing: Athena has a simple pricing model based on data scanned, while Redshift’s pricing depends on cluster configuration and usage, making it more variable.
- Use Case: Athena is ideal for quick, ad-hoc queries against S3, while Redshift is better suited for complex data warehouse reporting.
- Performance: Redshift is faster and more powerful but comes at a higher cost and requires more management, whereas Athena is simpler and more cost-effective for occasional queries.
- Serverless: Athena is a serverless service where you only pay for the queries you run, while Redshift requires you to manage uptime and pay accordingly.
Choosing between the two depends on your data needs—Athena for flexibility and simplicity, Redshift for more robust, high-performance data warehousing.
Conclusion
Both Redshift and Athena are wonderful services as Data Warehouse applications. If used in conjunction, it can provide great benefits. One should use Amazon Redshift when high computation is required and query large datasets and use Athena for simple queries.
Share your experience of learning about Redshift vs Athena in the comments section below!
You can try Hevo’s 14-day free trial. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs!
FAQs
1. What is the difference between Athena and Redshift?
Athena is a serverless query service that allows you to analyze data directly from S3 using SQL, whereas Redshift is a fully managed cloud data warehouse optimized for large-scale complex queries and analytics.
2. Why Redshift is better?
Redshift is better for structured, long-term analytics workloads, offering faster performance, scalability, and integration for advanced use cases like machine learning.
3. Is Athena a data warehouse?
No, Athena is not a data warehouse; it is a query engine. It doesn’t store data but queries data stored in S3 or external sources.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




