



Apache Kafka Exactly Once semantics is something which was much talked about but never achieved. Recently, Neha Narkhede, CTO of Confluent wrote an article that introduced the holy grail of Apache Kafka Exactly Once semantics in Kafka’s 0.11 release.
Before, people believed that it is not mathematically possible in distributed systems. This announcement raised eyebrows in the community. At Hevo, Kafka is our infrastructure backbone. So, we were curious too about the Kafka Exactly Once semantics. Here’s a detailed analysis of what is happening behind the scenes and how you can take advantage of Kafka’s Exactly once semantics.
Table of Contents
What is Kafka?
Apache Kafka is an open-source distributed event streaming platform. It provides a reliable pipeline to process data generated from various sources, sequentially and incrementally. Kafka handles both online and offline data consumption as the ingested data is persisted on disk and replicated within central clusters to prevent data loss. Kafka runs on a distributed system that is split into multiple running machines that work together in a single cluster. Apache Kafka provides its users with use cases such as:
- Publish and subscribe to streams of records.
- Store streams of records in a fault-tolerant way.
- Process streams of records as they occur.
- Provide a framework to develop a logic to perform analytics across streams of data using Kafka streams.
Kafka is usually used to build real-time data streaming pipelines and data streaming applications that adapt to data streams
What is Exactly Once Semantics?
The computers that comprise a distributed publish-subscribe messaging system can always fail independently of one another. In the case of Kafka, an individual broker or a network failure might occur when the producer is sending a message to a topic. Different semantics can be obtained depending on the producer’s response to such a failure.
Even if a producer retries sending a message, the message is only sent to the end consumer once. Exactly once Semantics is the most desirable assurance, but it is also the least understood. This is due to the fact that it necessitates collaboration between the messaging system and the application creating and consuming the messages. For example, if you rewind your Kafka consumer to an earlier offset after successfully consuming a message, you will get all the messages from that offset to the most recent one all over again. This demonstrates why the messaging system and the client application must work together to provide Exactly Once semantics.
What is the need for Kafka Exactly Once Semantics?
At Least Once Semantics guarantee that every message is written will be persisted at least once, without any data loss. It is useful when tuned for reliability. While ensuring this, the producer retries and causes duplicate in the stream.
Example
The broker may crash between committing a message and sending an acknowledgment back to the producer. It causes the producer to retry, which results in the duplication of messages in the target stream. Introducing idempotent producer semantics made more sense. Even in the event of client retries or broker failures, each message persists exactly once without any duplicates or data loss. Also, you can refer to the article Kafka to BigQuery

Problem with Kafka’s existing semantics: At Least Once
The Exactly Once Semantics allows a robust messaging system but not across multiple TopicPartitions. To ensure this, you need transactional guarantees – the ability to write to several TopicPartitions atomically. Atomicity is the ability to commit a bunch of messages across TopicPartitions as one unit, either all messages committees or none of them.
This Kafka Exactly Once Semantics Example clearly depicts how using these semantics can help build robust messaging systems, maintain atomicity and reduce data redundancy with ease.
We’ll see these features of Kafka version 0.11 in detail.
Hevo’s platform enhances your Kafka experience by providing:
- Wide Source Support: Integrate real-time from over 150+ sources effortlessly.
- Streamlined Setup: Connect Kafka as a source within minutes, without the need for complex coding.
- Seamless Scaling: Efficiently manage high-throughput Kafka topics with Hevo’s optimized pipelines.
- Data Accuracy: Ensure each event is processed exactly once, preserving data integrity.
Find out why Hevo is rated 4.3 on G2 and how 2000+ customers have chosen Hevo as their go to ETL tool.
Sign up here for a 14-Day Free Trial!Which Failures that must be handled?
To describe the challenges involved in supporting exactly-once delivery semantics, let’s start with a simple example.
Suppose there is a single-process producer software application that sends the message “Hello Kafka” to a single-partition Kafka topic called “EoS.” Further, suppose that a single-instance consumer application on the other end pulls data from the topic and prints the message. In the happy path where there are no failures, this works well, and the message “Hello Kafka” is written to the EoS topic partition only once. The consumer pulls the message, processes it, and commits the message offset to indicate that it has completed its processing. It will not receive it again, even if the consumer application fails and restarts.
However, we all know that we can’t count on a happy path. At scale, even unlikely failure scenarios are things that end up happening all the time.
- A broker can fail: Kafka is a highly available, persistent, and long-lasting system in which every message written to a partition is persisted and copied several times i.e., n. As a result, Kafka can withstand n-1 broker failures, which means that a partition may be accessed as long as at least one broker is available. Kafka’s replication mechanism ensures that once a message is successfully written to the leader replica, it is duplicated to all available replicas.
- The producer-to-broker RPC can fail: In Kafka, durability is determined by the producer obtaining an acknowledgment from the broker. Failure to obtain such acknowledgment does not always imply that the request failed. The broker can collapse after composing a message but before sending an acknowledgment to the producer. It may possibly crash before even attempting to write the message to the subject. Because the producer has no means of knowing the reason for the failure, it is obliged to presume that the message was not successfully written and to retry again. In certain situations, this will result in the same message being duplicated in the Kafka partition log, leading the end-user to receive it several times.
- The client can fail: Exactly-once delivery must account for client failures as well. Being able to tell the difference between a permanent failure and a soft one is important. For correctness, the broker should discard messages sent by a zombie producer. The same is true for the consumer. Once a new client instance has been started, it must be able to recover from whatever state the failed instance left behind and begin processing from a safe point. This means that consumed offsets must always be kept in sync with produced output.
What is an Idempotent Producer?
Idempotency is the second name of Kafka Exactly Once Semantics. To stop processing a message multiple times, it must be persisted to Kafka topic only once. During initialization, a unique ID gets assigned to the producer, which is called producer ID or PID.
PID and a sequence number are bundled together with the message and sent to the broker. As the sequence number starts from zero and is monotonically increasing, a Broker will only accept the message if the sequence number of the message is exactly one greater than the last committed message from that PID/TopicPartition pair. When it is not the case, the producer resends the message.

The Idempotent Producer
The producer ignores the low sequence number, which results in a duplicate error. Some messages may get lost due to high sequence numbers leading to an out-of-sequence error.
When the producer restarts, a new PID gets assigned. So the idempotency is promised only for a single producer session. Even though the producer retries requests on failures, each message is persisted in the log exactly once. There can still be duplicates depending on the source where the producer is getting data. Kafka won’t take care of the duplicate data received by the producer. So, in some cases, you may require an additional de-duplication system.
Which 3 types of Message Delivery Guarantees supports by Kafka?
Three different Message Delivery Guarantee types are supported by Kafka.
- At most Once: Every message in Kafka is only stored once, at most. If the producer doesn’t retry on failures, messages could be lost.
- At-Least Once: Every message will always be saved in Kafka at least once, according to this rule. There is no chance of message loss, but if the producer tries again after the message has already been persisted, the message may be duplicated.
- Exactly once: Despite broker failures or producer retries, Kafka guarantees that every message will be stored only once, without duplications or data loss.
What are the Pipeline Stages?
After you have the data in Kafka, we must process it. Thanks to Kafka Streams, you can do a lot with data without leaving Kafka. You can aggregate, generate queryable projections, window the data depending on event or processing time, and so on, in addition to simple mapping and filtering. Throughout the process, the data passes via numerous Kafka topics and processing stages.
So, how to make sure that in each stage, you observe each message as being processed exactly once?
The new Transaction feature is introduced into the picture. It allows you to atomically write data to various topics and partitions, as well as offsets of consumed messages. A single processing step receives data from one or more source topics, performs a computation, and then outputs the data to one or more target topics. And we can represent this as an atomic Kafka transaction unit by writing to target topics and storing offsets in source topics.
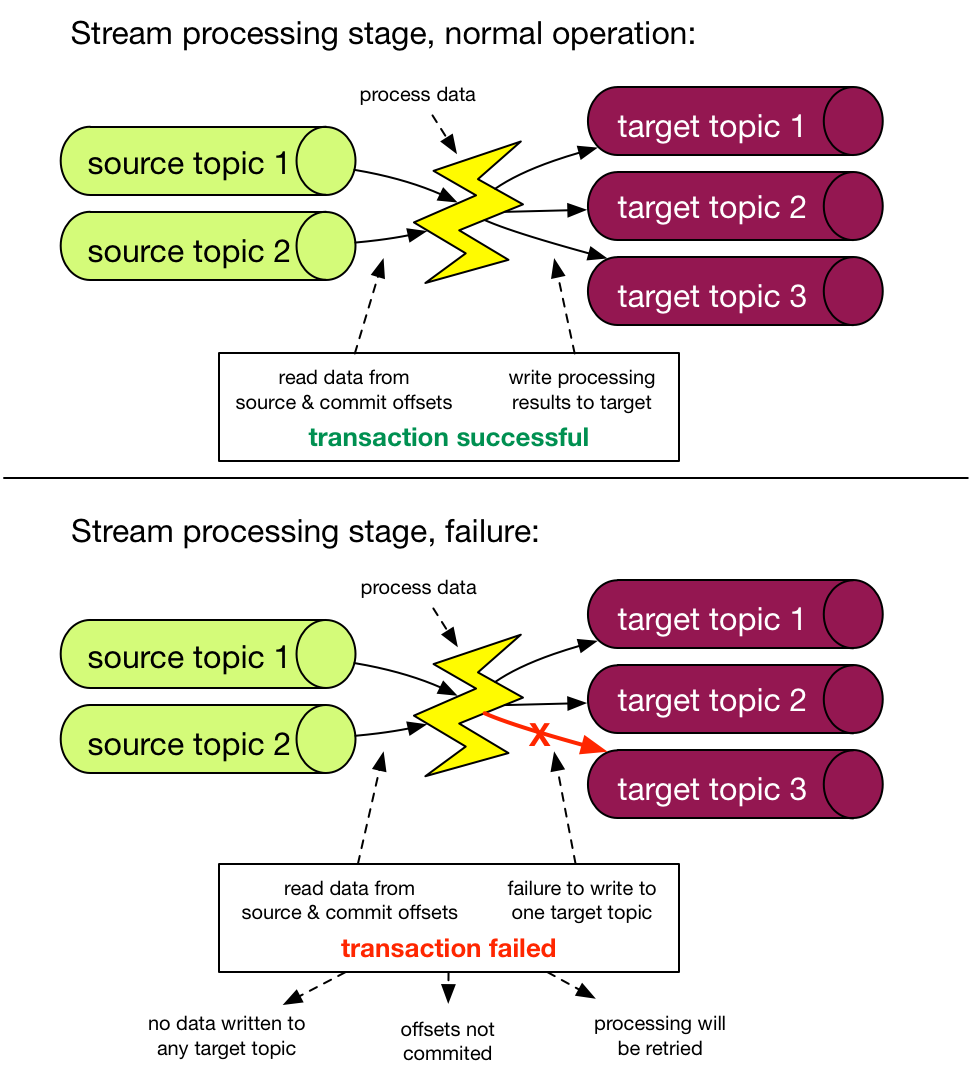
When the Exactly Once processing guarantee configuration is enabled on a Kafka streams application, the transactions are used transparently behind the scenes. There are no changes to how you establish a data processing pipeline using the API.
Transactions are difficult, however, in this instance, they are operating in a distributed system like Kafka. The crucial takeaway here is that they are operating within a closed system, i.e. the transaction spans solely Kafka topics/partitions.
Exactly-once guarantees in Kafka: Does it actually work?
We ended up with a simple design that also relies on the robust Kafka primitives to a substantial degree.
The following are as follows:
- Because our Transaction log is a Kafka Topic, it comes with the associated durability guarantees.
- Our newly implemented Transaction Coordinator (which manages the transaction state per producer) operates within the broker and handles failover naturally by leveraging Kafka’s leader election algorithm.
- For Stream Processing Applications developed using Kafka’s Streams API, we leverage the fact that the Source of Truth for the state store and input offsets are both Kafka topics. As a result, we can wrap this data transparently into transactions that atomically write to different partitions, providing the exactly-once guarantee for streams across read-process-write operations.
Because of the design’s simplicity, emphasis on leverage, and attention to detail, it had a better than fair chance of producing a workable implementation.
The solution is built on a simple and sturdy design with a well-tested, high-quality codebase.
Confluent gave itself the headroom to implement the idempotence and transactions feature with little performance overhead and to make Kafka quicker for everyone by fundamentally redesigning some of the underlying data structures. After a lot of hard work and years down to the line, Confluent is beyond delighted to provide the Exactly-once feature to the Apache Kafka community as a whole. Despite the effort put into developing Exactly-once semantics in Kafka, there will be improvements as the functionality is broadly embraced by the community.
Ensuring Atomic Transactions with Apache Kafka Exactly Once Semantics
The Idempotent producer ensures Exactly Once Semantics message delivery per partition. To do so in multiple partitions, Kafka guarantees atomic transactions, which powers the applications to produce multiple TopicPartitions atomically. All writes to these TopicPartitions will either succeed or fail as a single unit. The application must provide a unique id, TransactionalId, to the producer, which is stable across all sessions of the application. There is a one-one mapping between TransactionalId and PID. Kafka promises exactly one active producer with a given TransactionalId by baring off the old instance when new with the same TransactionalId is alive. Kafka also guarantees that the new instance is in the pure state by ensuring that all unfinished transactions have been completed (aborted/committed).
Here’s a code snippet that demonstrates the use of the new Producer Transactional APIs to send messages atomically to a set of topics.
<Code>
{
producer.initTransactions();
try{
producer.beginTransaction();
producer.send(record0);
producer.send(record1);
producer.sendOffsetsToTxn(…);
producer.commitTransaction();
} catch( ProducerFencedException e) {
producer.close();
} catch( KafkaException e ) {
producer.abortTransaction();
}
}
</Code>Key Exceptions of Kafka Producer APIs
The new exceptions in Producer APIs are listed below:
- ProducerFencedException: This exception is thrown if there is another active producer with the same TID in the system.
- OutOfOrderSequenceException: The producer will throw this exception if the broker detects a discrepancy in the data received. If it receives a greater SID than expected, it means that some messages have been lost whereas a lower SID means that the message is a duplicate.
How to Implement Kafka Exactly Once Semantics?
When a batch of data is consumed by a Kafka consumer from one cluster also known as the source then the Kafka producer immediately produces it to another cluster called target. The Kafka producer creates a new transaction via a coordinator to ensure that the protocol is Exactly Once delivered whenever the batch data is received by the consumer to point to the producer. With the help of the Exactly Once the protocol the coordinator present in the target cluster listens and points data to the producer.
How to Incorporate Exactly Once Semantics in Kafka Using Java?
The steps involved in this method are as follows:
- Step 1: To work with the Transaction API, you’ll need Kafka’s Java client in your pom:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.0.0</version> </dependency>- Step 2: For this particular instance, you’ll be consuming messages from an input topic, sentences. This will be followed by counting every word and then sending the individual word counts to an output topic. You can call it counts. You can move forward with the assumption that the sentence’s topic already has transactional data available.
- Step 3: You can add a producer in Kafka as follows:
Properties producerProps = new Properties(); producerProps.put("bootstrap.servers", "localhost:9092");You will also need to enable idempotence and mention a transactional.id with the help of the following snippet:
producerProps.put("enable.idempotence", "true"); producerProps.put("transactional.id", "prod-1"); KafkaProducer<String, String> producer = new KafkaProducer(producerProps);Now that you’ve enabled idempotence, Kafka will use the transaction id as a part of its algorithm. This is done to deduplicate any messages that this producer might send, ensuring idempotency.
- Step 4: In this step, you need to call initTransaction to prepare the producer to use transactions through the producer.initTransactions(); command. This connects the producer with the broker as one that can use transactions identified by its transactional.id and an epoch or sequence number. The broker will use these to write ahead all actions to a transaction log. The broker will also remove any actions from the log that belong to the same producer with the same transactional.id but a different epoch. It does so by assuming them to be from defunct transactions.
- Step 5: While consuming, you can generally read all the messages on a topic partition in order. You can also indicate with isolation.level that the system should be waiting to read transactional messages until the associated transaction has been carried out.
Properties consumerProps = new Properties(); consumerProps.put("bootstrap.servers", "localhost:9092"); consumerProps.put("group.id", "my-group-id"); consumerProps.put("enable.auto.commit", "false"); consumerProps.put("isolation.level", "read_committed"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps); consumer.subscribe(singleton(“sentences”));- Step 6: You have configured both the producer and the consumer to write and read transactionally, so you can consume records from your input topic and count each word in each record now with the following snippet:
ConsumerRecords<String, String> records = consumer.poll(ofSeconds(60)); Map<String, Integer> wordCountMap = records.records(new TopicPartition("input", 0)) .stream() .flatMap(record -> Stream.of(record.value().split(" "))) .map(word -> Tuple.of(word, 1)) .collect(Collectors.toMap(tuple -> tuple.getKey(), t1 -> t1.getValue(), (v1, v2) -> v1 + v2));Here the read_committed is used which means that no messages written to the input topic in the same transaction will be read by this consumer until they are all written.
- Step 7: To send the counts as new messages in the same transaction, you’ll be calling beginTransaction as the producer.beginTransaction(); command. Next, you can write each one to your “counts” topic with the key and the count being the word and the value respectively.
wordCountMap.forEach((key,value) -> producer.send(new ProducerRecord<String,String>("counts",key,value.toString())));- Step 8: You need to commit to the offsets that you just finished consuming. With transactions, you can commit the offsets back to the input topic you read them from. These are sent with the producer’s transactions. In the following snippet, you can do all this in a single call but you’ll first need to calculate the offsets for each topic partition:
Map<TopicPartition, OffsetAndMetadata> offsetsToCommit = new HashMap<>(); for (TopicPartition partition : records.partitions()) { List<ConsumerRecord<String, String>> partitionedRecords = records.records(partition); long offset = partitionedRecords.get(partitionedRecords.size() - 1).offset(); offsetsToCommit.put(partition, new OffsetAndMetadata(offset + 1)); }You can then send the calculated offsets to the transaction:
producer.sendOffsetsToTransaction(offsetsToCommit, "my-group-id");- Step 9: You can commit to the transaction as follows:
producer.commitTransaction();You can also catch an exception as follows:
try { // ... read from input topic // ... transform // ... write to output topic producer.commitTransaction(); } catch ( Exception e ) { producer.abortTransaction(); }The Kafka broker will abort if you don’t commit or abort before the broker-configured max.transaction.timeout.ms.
How does Apache Kafka Exactly Once Impact Consumers?
On the consumer side, the behavior of the consumer can be tuned by changing the isolation level. The isolation level is the setting that maintains the balance between performance and reliability, consistency and reproducibility in a massive concurrent transaction environment.
There are now two new isolation levels in Kafka consumers:
- Read_Committed: It reads both kinds of messages that are not part of a transaction and that are after the transaction committees. Read_committed consumer uses end offset of a partition, instead of client-side buffering. This offset is the first message in the partition belonging to an open transaction. It is also known as “Last Stable Offset” (LSO). A read_committed consumer will only read up to the LSO and filter out any transactional messages which have been aborted.
- Read_Uncommitted: Read all messages in offset order without waiting for transactions to committees. This option is similar to the current semantics of a Kafka consumer.
Apache Kafka Connect Exactly Once’s Impact on Performance
Kafka promises certain performance improvement over the previous release which includes, up to +20% producer throughput, up to +50% consumer throughput, and up to -20% disk utilization. The significant decrease in disk utilization is due to the change in the message format.
Message Format Change
The size of the older message format is fixed at 34 bytes. The new message format needed the addition of PID, Epoch, and a Sequence number which also added a significant overhead in the message size with 53 bytes. So, new message formats were introduced as MessageSet and Message, which is shown below:
MessageSet =>
FirstOffset => int64
Length => int32
PartitionLeaderEpoch => int32
Magic => int8
CRC => int32
Attributes => int16
LastOffsetDelta => int32 {NEW}
FirstTimestamp => int64 {NEW}
MaxTimestamp => int64 {NEW}
PID => int64 {NEW}
ProducerEpoch => int16 {NEW}
FirstSequence => int32 {NEW}
Messages => [Message]
Message => {ALL FIELDS ARE NEW}
Length => varint
Attributes => int8
TimestampDelta => varint
OffsetDelta => varint
KeyLen => varint
Key => data
ValueLen => varint
Value => data
Headers => [Header] /* Note: The array uses a varint for the number of headers. */
Header => HeaderKey HeaderVal
HeaderKeyLen => varint
HeaderKey => string
HeaderValueLen => varint
HeaderValue => dataMessageSet contains a list of Messages. I’ll not go into much detail about each item in the new message format. But, the total message size decreases on sending messages in a batch. The offset and timestamp delta, taking less space, is part of each message, whereas the initial timestamp and offset are part of messages. PID and epoch being the same for all messages in a batch is also a part of MessageSet. This elimination of redundancy decreases the overhead of the new format as the batch size increases.
For example (as taken from cwiki.apache.org ) Assume a fixed message size of 50 with 100-byte keys and close timestamps, the overhead increases by only 7 bytes for each additional batched msgs (2 bytes for the message size, 1 byte for attributes, 2 bytes for timestamp delta, 1 byte for offset delta, and 1 byte for key size)
| Batch Size | Old Format Overhead | New Format Overhead |
| 1 | 34*1 = 34 | 53 + 1*7 = 60 |
| 3 | 34*3 = 102 | 53 + 3*7 = 74 |
| 10 | 34*10 = 340 | 53 + 10*7 = 123 |
| 50 | 34*50 = 1700 | 53 + 50*7 = 403 |
Enhanced Error Handling
Apache Kafka’s Exactly Once Semantics provides users with robust recovery and an error-handling mechanism that allows both the producer and consumer to understand and determine if they can continue sending data in a way that doesn’t contradict the Exactly Once mechanism. It helps overcome the dreading issue of a fatal error that would result in the client having to create a new producer from scratch again.
For example, often a fatal error can arise when the producer fails to assign the sequence IDs or numbers to the records, thereby preventing the broker from accepting these records, which can only take place sequentially.
To overcome this issue, which would otherwise result in the producer making multiple re-attempts until it reaches the delivery timeout or succeeds in overcoming the errors, EOS provides an effective mechanism. It allows the broken to initialize the producer Id again by giving the InitProducerId parameter as well. The “broker” can now compare the producerId with the transactionalId to understand if the producer can continue to process data. In case, these match, the broken will start incrementing the epoch for the producer and send it back. This allows the producer to continue processing data and overcome the error resetting the sequence.

This is how Kafka Exactly Once Semantics support and provides a robust error-handling mechanism.
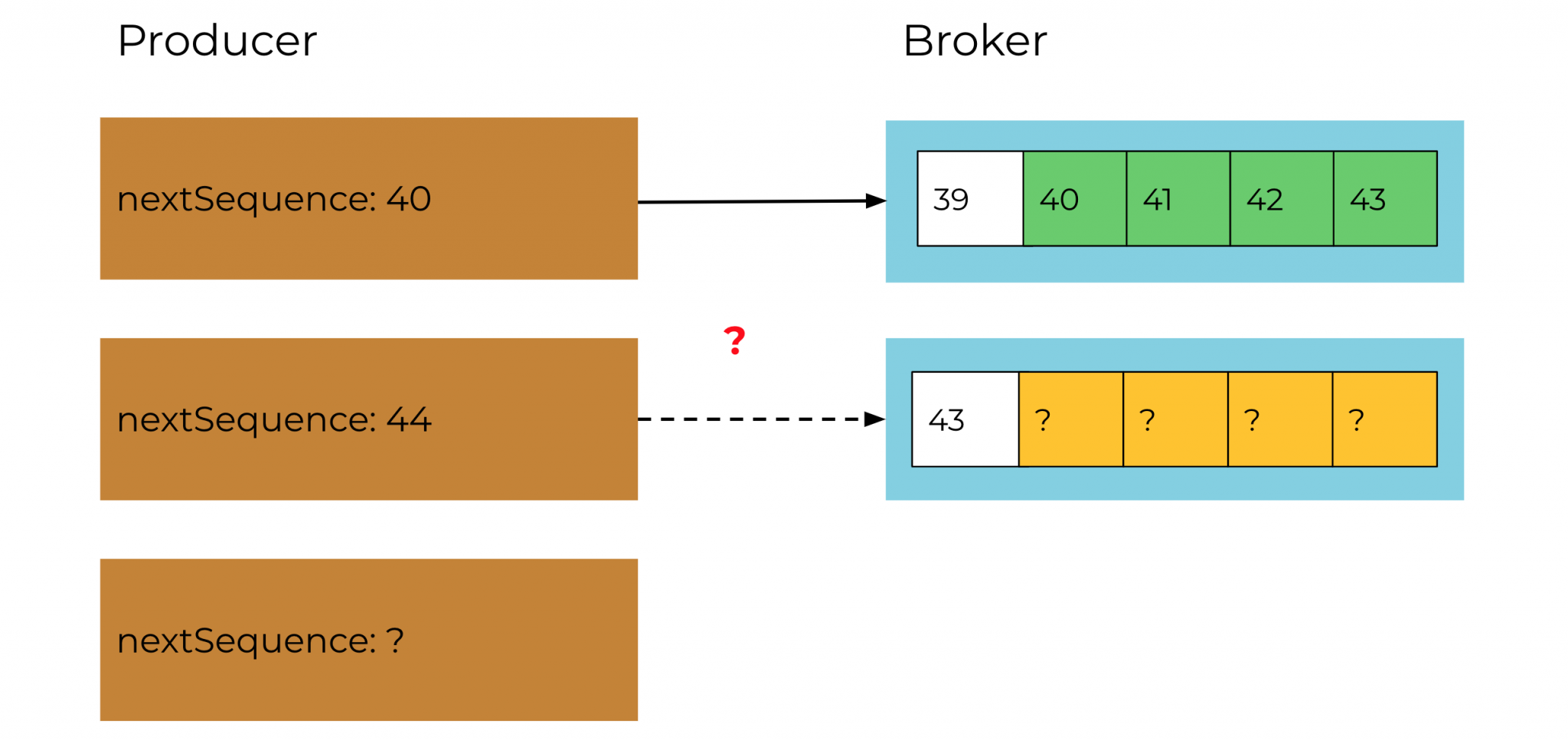
Records are written into the log in sequential order after a successful exactly-once produce call. Both the producer and the broker keep note of this sequence. If a record batch fails repeatedly until it is expired by the producer, the producer cannot be certain that records were written to the log. This means that the producer doesn’t know what sequence number to assign to the next record and is unable to continue processing.
Why Exactly Once Semantics across Multiple Instances is hard?
Let us take the example of MirrorMaker 2 for simplicity.
A batch of data is ingested by a Kafka consumer from one cluster (referred to as the “source“) and instantly produced in another cluster (referred to as the “target“) by a Kafka producer. To assure “Exactly-Once” delivery, the producer initiates a new transaction via a “coordinator” each time it receives a batch of data from the consumer. According to the “Exactly-once” protocol, the coordinator resides in the cluster (“target“) to which the producer refers.
If all goes well, the last step before the newly generated data are available on the target cluster for consumption is for the producer to commit the consumer offsets to an “offset” topic (often named _consumer_offsets), so the consumer knows where to consume in the next batch. The consumer offsets, on the other hand, are initialized by the consumer, and the offset topic must be in the source cluster. The producer pointing to the target cluster is unable to produce/write to the offset topic, which is located in another cluster.
How to support Exactly Once across multiple clusters?
KIP-656 is the entire proposal. In shorter words, the current Exactly-once framework designed for one cluster is still leveraged, but the above challenges are resolved while applying to multiple clusters.
The crucial aspect is that for consumer offsets and the offset topic, the producer manages, commits, and stores the single source of truth on the target cluster instead.
The consumer must still reside on the source cluster in order to retrieve data from it, but the “source-of-truth” consumer offsets are no longer held on the source cluster. We propose using the following notion to appropriately rewind the consumer when the data transmission task (in this case, MirrorMaker) restarts or rebalances, while the “source-of-truth” consumer offsets are kept in the target cluster:
- Consumer offsets are stored in the target cluster using a “fake” consumer group, which can be established programmatically if the name of the consumer group is known. The term “fake” refers to the fact that the group would consume no actual records, just offsets kept in the _consumer_offsets topic. However, the “source-of-truth” _consumer_offsets are controlled by the consumer offsets topic on the target cluster (managed by the “fake” consumer group).
- The consumer in MirrorMaker does not rely on Connect’s internal offsets tracking or consumer offsets on the source cluster when using the “fake” consumer group on the target cluster.
- The consumer offsets associated with the “fake” consumer group are only written by the producer to the target cluster.
- All records are written in a single transaction as if they were in a single cluster.
- When MirrorMaker begins or rebalances, it loads initial offsets from the target cluster’s _consumer_offsets topic.
The outcome of the above idea:
- If the transaction is successful, the _consumer_offsets topic on the target cluster is modified using the Exactly-once framework’s current protocol.
- If the transaction fails, all data records are lost, and the target cluster’s _consumer_offsets topic is not updated.
- MirrorMaker restarts/restarts at the last committed offsets as saved in the target cluster.
Conclusion
Kafka Exactly Once Semantics is a huge improvement over the previously weakest link in Kafka’s API: the Producer. However, it’s important to note that this can only provide you with Kafka Exactly Once semantics are provided that it stores the state/result/output of your consumer (as is the case with Kafka Streams). You can also consider Amazon Kinesis and have a look at this in-depth Kinesis vs Kafka guide.
Once you have a consumer that, for example, makes non-idempotent updates to a database, there’s the potential for duplication: if the consumer exists after updating the database, but before committing the Kafka offsets. Alternatively, transactions on the database lead to “message loss” and the application exits after the offsets were committed, but before the database transaction was committed.
Hevo is a No-code Data Pipeline. Hevo is building the most robust and comprehensive ETL solution in the industry. You can integrate with your in-house databases, cloud apps, flat files, clickstream, etc. at a reasonable price.
Want to take Hevo for a spin? Signup for a 14-day free trial and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Share your experience of using Kafka Exactly Once Semantics in the comment section below.
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



