




Data pipelines and workflows have become an inherent part of the advancements in data engineering, machine learning, and DevOps processes. With ever-increasing scales and complexity, the need to orchestrate these workflows efficiently arises.
That is where Apache Airflow steps in —an open-source platform designed to programmatically author, schedule, and monitor workflows. In this blog, we will explain Airflow architecture, including its main components and best practices for implementation. So let’s dive right in!
Table of Contents
A Deeper Understanding of Airflow
Apache Airflow is an open-source platform responsible for authoring, scheduling, and monitoring workflows. Airflow workflows are defined as Directed Acyclic Graphs(DAGs), implying that the tasks in a workflow should be executed in a specific order to ensure that one task is completed before starting the execution of the next.
It was designed by Airbnb to replace the need for a scalable platform to maintain workflows. It quickly became one of the most popular workflow orchestrators in the data engineering world and today is maintained by the Apache Software Foundation.
Key Features of Airflow
- Business Operations: Apache Airflow’s tool agnostic and extensible quality makes it a preferred solution for many business operations.
- ETL/ELT: Airflow allows you to schedule your DAGs in a data-driven way. It also uses Path API, simplifying interaction with storage systems such as Amazon S3, Google Cloud Storage, and Azure Blob Storage.
- Infrastructure Management: Setup/teardown tasks are a particular type of task that can be used to manage the infrastructure needed to run other tasks.
- MLOps: Airflow has built-in features that include simple features like automatic retries, complex dependencies, and branching logic, as well as the option to make pipelines dynamic.
Say goodbye to the complexities associated with Airflow by choosing a tool that provides the best features for your data migration needs- Hevo. With Hevo:
- Seamlessly pull data from over 150+ other sources with ease.
- Utilize drag-and-drop and custom Python script features to transform your data.
- Efficiently migrate data to a data warehouse, ensuring it’s ready for insightful analysis.
Try Hevo and discover why 2000+ customers like Ebury have chosen Hevo over tools like Fivetran and Stitch to upgrade to a modern data stack.Get Started with Hevo for Free
Get Started with Hevo for FreeOverview of Airflow Architecture
Apache Airflow architecture is crucial for handling and automating complex chains in data pipelines. Understanding key components and their interactions within Airflow will provide a better understanding of its inner workings. Let’s dive deep into Airflow’s architecture.
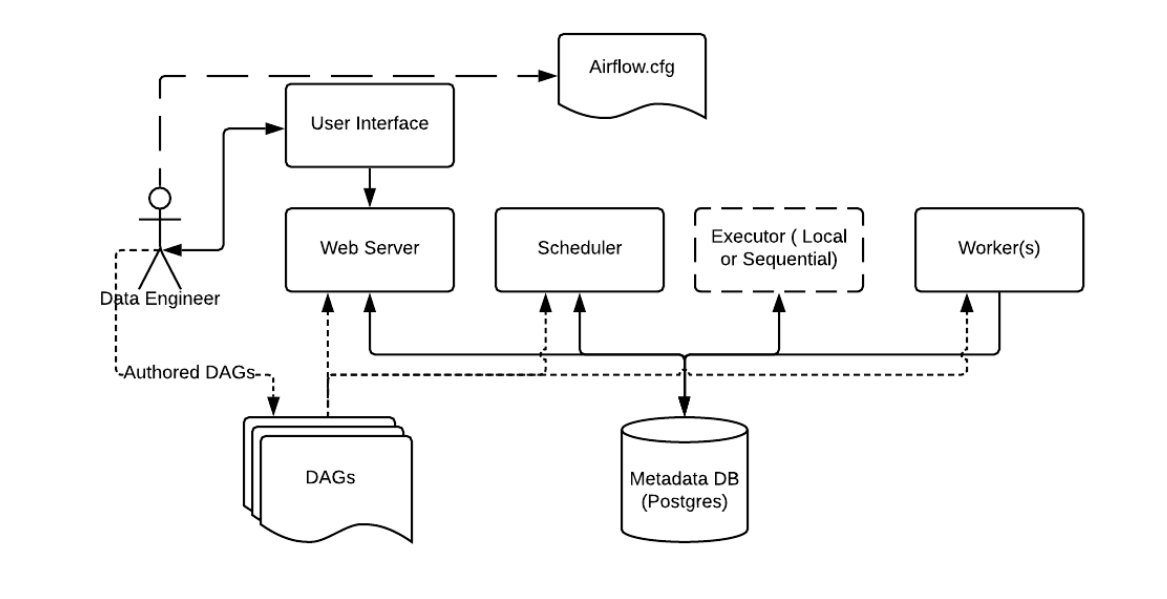
Airflow components are divided into core components essential for a minimum installation and optional components that help improve performance and efficiency. Let’s examine both in detail.
Core Components of Airflow Architecture
There are a few components to note:
- Metadata Database: Airflow leverages a SQL database to store metadata on the various pipelines being executed. Above this is Postgres, which is extremely popular with Airflow. Other databases supported with Airflow include MySQL.
- Web Server and Scheduler: The Airflow web server and Scheduler run as daemons, in this case, on the local machine, interacting with the database mentioned above.
- The Executor: It is a configuration property of the scheduler, not a separate component, and runs within the scheduler process. Several executors are available out of the box, and you can also write your own.
- Workers are different processes, but they also interact with the other Airflow architecture components and the metadata repository.
- airflow.cfg : Configuration file to Airflow, accessed by Web Server, Scheduler and Workers.
- DAGs: It is a collection of DAG files comprising Python code that contains data pipelines to be executed by Airflow. The location of the DAGs is specified inside the Airflow configuration file. However, they must also be accessible by the Web Server, Scheduler, and Workers.
Optional Components of Airflow Architecture
Some Airflow components are optional and can enable better extensibility, scalability, and performance in your Airflow:
- An optional worker executes the tasks given to it by the scheduler. The worker might be part of the scheduler in the basic installation, not a separate component.
- Optional triggerer, which executes deferred tasks in an asyncio event loop.
- Optional DAG processor: It parses DAG files and serializes them into the metadata database. By default, it’s part of the scheduler process, but it can run independently for scalability and security reasons.
- Optional plugins folder: Plugins extend Airflow’s functionality beyond what’s available in the core.
Deploying Airflow Components
Now, the question of who arises. Who is responsible for deploying all these complex components? Although a single person can manage and run airflow installation, airflow deployment is much more complex and involves various roles of users who can interact with different parts of the system. These roles include:
- Deployment Manager: A person who installs and configures Airflow and manages the deployment.
- DAG author: A person who writes DAGs and submits them to Airflow.
- Operations User: A person who triggers DAGs and tasks and monitors their execution.
Types of Airflow Architectures
All the components are Python applications that can be deployed using various deployment mechanisms, depending on the type of architecture.
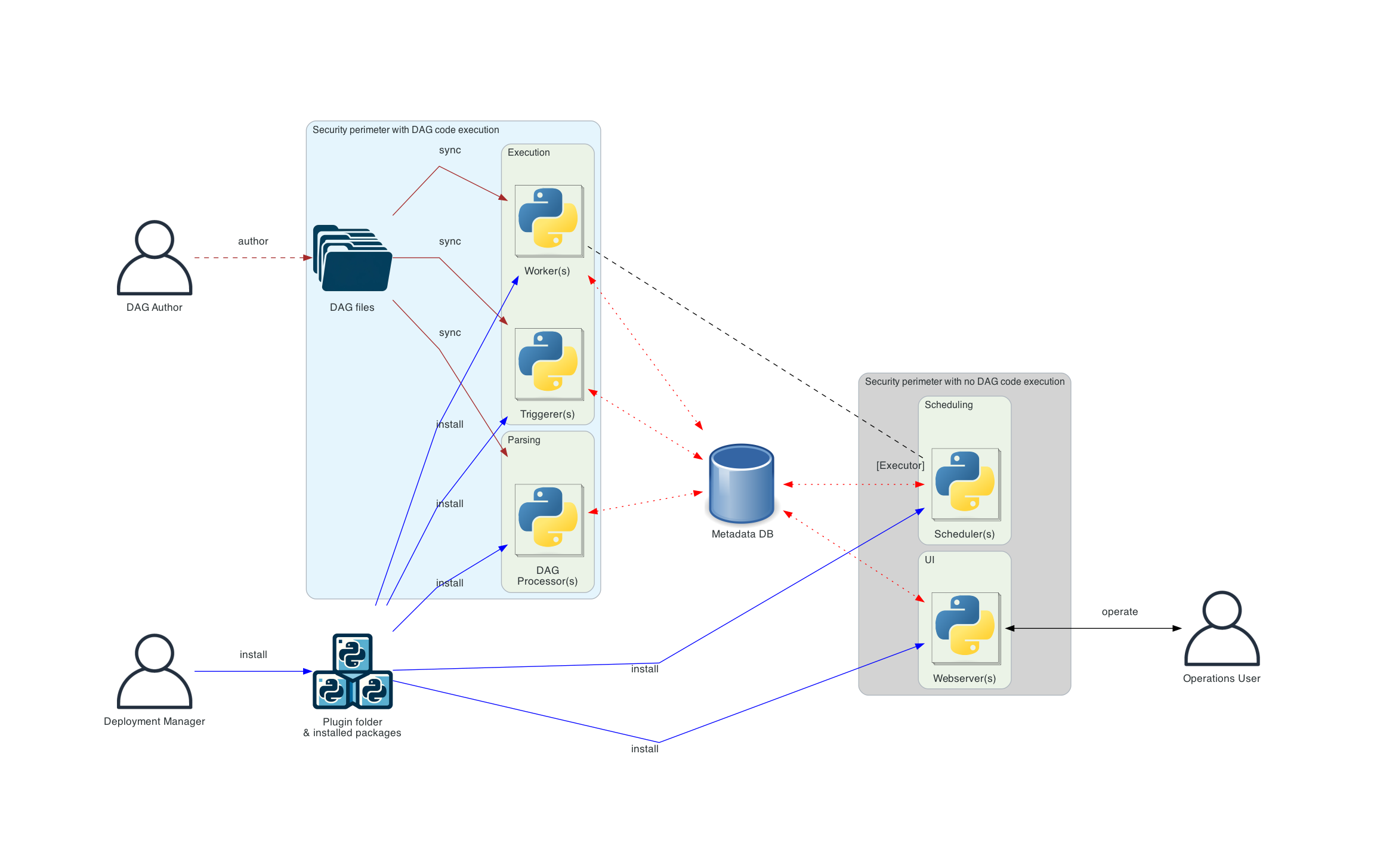
Before we discuss different types of Airflow architectures, let’s talk about architecture diagrams.
Architecture diagrams show different ways to deploy airflow and have different connections. The meaning of a few connections is given below:
- Brown solid lines: DAG files submission and synchronization
- Blue solid lines: Deploying and accessing installed packages and plugins
- Black dashed lines: Control flow of workers by the scheduler (via executor)
- Black solid lines: Accessing the UI to manage the execution of the workflows
- Red dashed lines: Accessing the metadata database by all components
Now that you know how to interpret an architecture diagram, let’s have a look at different architecture types for airflow deployment.
Basic Airflow Architecture
- This is the simplest form of Airflow Deployement and is operated and managed on a single machine.
- The scheduler and the workers use the same Python process, and the scheduler reads the DAG files directly from the local filesystem.
- It does not separate user roles—deployment, configuration, operation, authoring, and maintenance are all performed by the same person.

Distributed Airflow architecture
- In this architecture, components of Airflow are distributed among multiple machines, and various user roles are introduced.
- It is essential to take into account the security aspects of the components.
- The web server doesn’t have direct access to the DAG files and cannot read any code submitted by the DAG author.
- It can only execute code installed as an installed package or plugin by the Deployment Manager.
- The DAG files must be synchronized between all the components that use them – scheduler, triggerer, and workers.

Separate DAG processing architecture
- A standalone dag processor component that separates the scheduler from accessing DAG files.
- It is a more complex installation where security and isolation are important.
- While Airflow does not natively support full multi-tenancy features yet, it can be used in order to make sure that DAG author-provided code will never be executed in the context of the scheduler.
DAGs – Something We’ve Been Talking About Since the Beginning
So, what exactly are DAGs? In Airflow, a DAG, or a Directed Acyclic Graph, defines a series of tasks as a Python script. In this instance, a task is defined or represented through operators ranging from simple Python functions to more complex ones, such as running Spark jobs or firing queries against databases.
For example, a simple DAG could have three tasks: A, B, and C. Let’s say that B and C can run only after A has successfully completed execution. Or let’s say that task A times out after 10 minutes, and B can be restarted up to 3 times in case it fails. It might also say the workflow will run daily at noon but should not start until a specific date. To represent the first scenario, we can write:
A >> [B, C]This is known as a Dependency.
DAGs are stored in Airflow’s DAG_FOLDER, and Airflow runs each code dynamically to build the DAG objects.

Workloads
A DAG runs through a series of Tasks, all subclasses of Airflow’s BaseOperator. The three common types of tasks are:
- Operators: These are the predefined tasks that you can use to build most parts of your DAGs.
- Sensors: It’s a special subclass of Operators that are responsible for waiting for an external event to happen.
- TaskFlow-decorated @task: It is a custom Python function packaged up as a Task.
Control Flow
DAGs are designed in such a way that they can run parallelly multiple times. They always contain a parameter that specifies the interval they are “running for” (the data interval).
As we discussed earlier, Dependencies in tasks are responsible for knowing which task will be executed when by the Airflow.
By default, tasks have to wait for all previous tasks to execute before they can start their execution, but you can customize how tasks are executed with features like LatestOnly, Branching, and Trigger Rules.
Best Practices for Airflow Implementation
Although Airflow is an excellent data orchestration tool, it comes with its own set of challenges, such as the need for technical expertise, complexity, and difficulty scaling. To ensure the smooth working of your Workflows, it is imperative to follow a set of best practices.
- Organize Your Workflows: Since Airflow workflows are developed in Python, keeping a clean and organized codebase is important.
- Use Version Control: Segmenting different workflows into their respective folders is a good idea, and/or you can use Git for version control.
- Monitor DAGs continuously: Ensure that Airflow scales with your growing size and increasing complexity of workflows. The right executor(Celery or Kubernetes) and well-scaled resources like workers and schedulers would prevent bottlenecks in execution.
- Define SLAs: Airflow lets you define how quickly a task or workflow must be done. The exceeded time limit does notify the person in charge and logs an event in the database.
Discover how Airflow compares to NiFi for workflow orchestration, and gain insights into choosing the right tool in our comprehensive guide.
How is Hevo a better solution for Your Data Migration?
If you’re looking for an ETL tool that fits your business needs, Airflow has pros and cons. It’s a highly flexible and customizable open-source tool, but it can be complex and have a steep learning curve.
Meet Hevo, an automated data pipeline platform that provides the best of both tools. Hevo offers:
- A user-friendly interface.
- Robust data integration and seamless automation.
- It supports 150+ connectors, providing all popular sources and destinations for your data migrations.
- The drag-and-drop feature and custom Python code transformation allow users to make their data more usable for analysis.
- A transparent, tier-based pricing structure.
- Excellent 24/7 customer support.
These features combine to place Hevo at the forefront of the ELT market.
Considering workflow orchestration tools? Don’t miss our blog Hevo vs Airflow: The Better Tool? to see how Airflow stacks up against other options.
Conclusion
Apache Airflow is a powerful tool if you can understand its components, configuration, and implementation, but it can be difficult for people with no technical knowledge to implement.
For a hassle-free solution, Choose Hevo. Whether managing ETL pipelines or transforming data, Hevo is the ideal tool for managing your data-driven tasks. Sign up for Hevo’s 14-day trial and get started with Hevo for free!
Frequently Asked Questions
1. What is the difference between Kafka and Airflow?
Kafka is for real-time data streaming; Airflow is for orchestrating and scheduling data workflows.
2. Is Airflow the same as Jenkins?
Airflow manages data workflows; Jenkins automates software build and deployment processes.
3. Is Airflow an ETL?
Airflow is not an ETL tool but orchestrates ETL processes.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



