



Data Engineering Pipelines play a vital role in managing the flow of company business data. Organizations spend a significant amount of money on developing and managing Data Pipelines so they can get streamlined data to accomplish their daily activities with ease. Many tools in the market help companies manage their messaging and task distributions for scalability.
Apache Airflow is a workflow management platform that helps companies orchestrate their Data Pipeline tasks and save time. As data and the number of backend tasks grow, the need to scale up and make resources available for all the tasks becomes a necessity. Airflow Celery Executor makes it easier for developers to build a scalable application by distributing the tasks on multiple machines. With the help of Airflow Celery, companies can send multiple messages for execution without any lag.
Apache Airflow Celery Executor is easy to use as it uses Python scripts and DAGs for scheduling, monitoring, and executing tasks. In this article, you will learn about Airflow Celery Executor and how it helps scale out and distribute tasks efficiently. Also, you will read about the architecture of the Airflow Celery Executor and how its process executes the tasks.
Table of Contents
Prerequisites
- A brief overview of Apache Airflow.
Introduction to Apache Airflow

Apache Airflow is an open-source workflow management platform to programmatically author, schedule, and monitor workflows. In Airflow, workflows are the DAGs (Directed Acyclic Graphs) of tasks and are widely used to schedule and manage the Data Pipeline. Airflow is written in Python, and workflows are created in Python scripts. Airflow using Python allows developers to make use of libraries in creating workflows.
The Airflow workflow engine executes complex Data Pipeline jobs with ease. It ensures that each task is executed on time and in the correct order and gets the required resources. Airflow can run DAGs on the defined schedule and based on external event triggers.
Read more about the Airflow Scheduler and Installation of Airflow.
Leverage Hevo’s No-Code Data Pipeline to seamlessly integrate, transform, and sync data from 150+ sources. Hevo helps you ensure that:
- Your analytics and project management tools are always up-to-date and accurate.
- You get real-time notifications.
- Rely on Live Support with a 24/5 chat featuring real engineers, not bots!
Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines. With a 4.3 rating on G2, users appreciate its reliability and ease of use—making it worth trying to see if it fits your needs.
Get Started with Hevo for FreeIntroduction to the Airflow Celery Executor
Airflow Celery is a task queue that helps users scale and integrate with other languages. It comes with the tools and supports you need to run such a system in production.
Executors in Airflow are the mechanism by which users can run the task instances. Airflow comes with various executors, but the most widely used among those is Airflow Celery Executor used for scaling out by distributing the workload to multiple Celery workers that can run on different machines.
CeleryExecutor works with some workers it has to distribute the tasks with the help of messages. The deployment scheduler adds a message to the queue and the Airflow Celery broker delivers that message to the Airflow Celerty worker to execute the task. If due to any failure the assigned Airflow Celery worker on the job goes down then Airflow Celery quickly adapts to it and assigns the task to another worker.
Airflow Celery Executor Setup
To set up the Airflow Celery Executor, first, you need to set up an Airflow Celery backend using message broker services such as RabbitMQ, Redis, etc. After that, you need to change the airflow.cfg file to point the executor parameters to CeleryExecutor and enter all the required configurations for it.
The prerequisites for setting up the Airflow Celery Executor Setup are listed below:
- Airflow was installed on the local machine and properly configured.
- Airflow configuration should be homogeneous across the cluster.
- Before executing any Operators, the workers need to have their dependencies met in that context by importing the Python library.
- The workers should have access to the DAGs directory – DAGS_FOLDER.
Step 1: Starting and Stopping the Airflow Celery Worker
- To start the Airflow Celery worker, use the command below to get the service started and ready to receive tasks. As soon as a task is triggered in its direction, it will start its job.
airflow celery worker- To stop the worker, use the command given below.
airflow celery stopStep 2: Monitor the Celery Worker
- You can also use its GUI web application that allows users to monitor the workers. To install the flower Python library, use the following command given below in the terminal.
pip install 'apache-airflow[celery]'- You can start the Flower web server by using the command given below.
airflow celery flower
Airflow Celery Executor Architecture
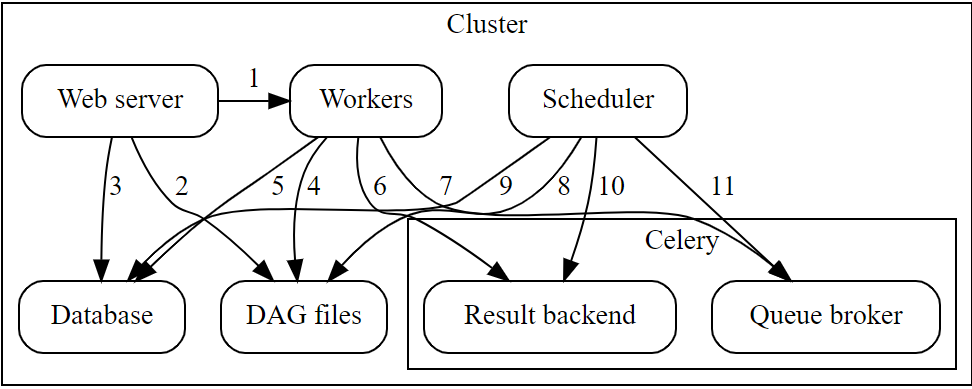
Components of the Architecture
The architecture of the Airflow Celery Executor consists of several components listed below:
- Workers: Its job is to execute the assigned tasks by Airflow Celery.
- Scheduler: It is responsible for adding the necessary tasks to the queue.
- Database: It contains all the information related to the status of tasks, DAGs, Variables, connections, etc.
- Web Server: The HTTP server provides access to information related to DAG and task status.
- Celery: Queue mechanism.
- Broker: This component of the Celery queue stores commands for execution.
- Result Backend: It stores the status of all completed commands.
Communication Flow Between Components
Now that you have understood the different components of the architecture of Airflow Celery Executor. Now, let’s understand how these components communicate with each other during the execution of any task.
- Web server –> Workers: It fetches all the task execution logs.
- Web server –> DAG files: It reveals the DAG structure.
- Web server –> Database: It fetches the status of the tasks.
- Workers –> DAG files: It reveals the DAG structure and executes the tasks.
- Workers –> Database: Workers get and store information about connection configuration, variables, and XCOM.
- Workers –> Celery’s result backend: It saves the status of tasks.
- Workers –> Celery’s broker: It stores all the commands for execution.
- Scheduler –> DAG files: It reveals the DAG structure and executes the tasks.
- Scheduler –> Database: It stores information on DAG runs and related tasks.
- Scheduler –> Celery’s result backend: It gets information about the status of completed tasks.
- Scheduler –> Celery’s broker: It puts the commands to be executed.
Task Execution Process of Airflow Celery

In this section, you will learn how the tasks are executed by Airflow Celery Executor. Initially when the task is begin to execute, mainly two processes are running at that time.
- SchedulerProcess: This processes the tasks and runs with the help of Airflow CeleryExecutor.
- WorkerProcess: It overserves that is waiting for new tasks to append in the queue. It also has WorkerChildProcess that waits for new tasks.
Databases Involved in Task Execution
Also, The two Databases are involved in the process while executing the task:
- ResultBackend
- QueueBroker
Along with the process, the two other processes are created. The processes are listed below:
- RawTaskProcess: It is the process with user code.
- LocalTaskJobProcess: The logic for this process is described by the LocalTaskJob. Its job is to monitor the status of RawTaskProcess. All the new processes are started from TaskRunner.
Task Execution Flow
The process of how tasks are executed using the above process and how the data and instructions flow are given below.
- SchedulerProcess processes the tasks and when it gets a task that needs to be executed, then it sends it to the QueueBroker to add the task to the queue.
- Simultaneously the QueueBroker starts querying the ResultBackend for the status of the task. And when the QueueBroker gets acquainted with the then it sends the information about it to one WorkerProcess.
- When WorkerProcess receives the information, it assigns a single task to one WorkerChildProcess.
- After receiving a task, WorkerChildProcess executes the handling function for the task i.e. execute_command(). This creates the new process LocalTaskJobProcess.
- LocalTaskJobProcess describes the logic for LocalTaskJobProcess. A new process is started using TaskRunner.
- Both the RawTaskProcess and LocalTaskJobProcess processes are stopped when they are finished.
- Then, WorkerChildProcess notifies this information about the completion of a task and the availability of subsequent tasks to the main process WorkerProcess.
- WorkerProcess then saves the status information back into the ResultBackend.
- Now, whenever SchedulerProcess requests the status from ResultBackend, it receives the task status information.
Conclusion
In this article, you learned about Apache Airflow, Airflow Celery Executor, and how it helps companies achieve scalability. Also, you read about the architecture of Airflow Celery Executor and its task execution process. Airflow Celery uses message brokers to receive tasks and distributes those on multiple machines for higher performance.
Companies need to analyze their business data stored in multiple data sources. The data needs to be loaded to the Data Warehouse to get a holistic view of the data. Hevo Data is a No-code Data Pipeline solution that helps to transfer data from 150+ sources to desired Data Warehouse. It fully automates the process of transforming and transferring data to a destination without writing a single line of code.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
Share your experience of learning about Airflow Celery Executor in the comments section below!
FAQs
1. What does Celery do in Airflow?
Celery is a distributed task queue used within Airflow to run and govern tasks in parallel across distributed nodes. It is one of the ways to scale Airflow by providing better performance and relying on several workers to get things done.
2. What is the difference between a Celery worker and an Airflow worker?
A Celery worker is a process that executes tasks from the Celery queue, whereas an Airflow worker is a more general term referring to any worker node that runs Airflow tasks. In a CeleryExecutor setup, the Airflow worker is specifically a Celery worker.
3. What is an alternative to Airflow?
Alternatives to Airflow include tools like Luigi, Prefect, and Dagster, which also handle task orchestration, workflow management, and data pipeline automation with varying features and deployment models.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





