



Unlock the full potential of your Amazon RDS data by integrating it seamlessly with Azure Synapse. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
In this article, we’ll be going over two methods you can use to load data from Amazon RDS to Azure Synapse Analytics: using Aurora Read Replica and a third-party, no-code data replication tool.
Note: We’ll be migrating data from SQL Server on Amazon RDS in the article. Amazon RDS for SQL Server simplifies the process of operating, configuring, and scaling SQL Server on the cloud.
Use Hevo’s no-code data pipeline platform, which can help you automate, simplify, and enrich your data replication process in a few clicks. You can extract and load data from 150+ Data Sources, including Amazon RDS straight into your Data Warehouse, such as Azure Synapse or any Database.
Why Choose Hevo?
- Offers real-time data integration which enables you to track your data in real time.
- Get 24/5 live chat support.
- Eliminate the need for manual mapping with the automapping feature.
Discover why Postman chose Hevo over Stitch and Fivetran for seamless data integration. Try out the 14-day free trial today to experience an entirely automated hassle-free Data Replication!
Get Started with Hevo for FreeTable of Contents
Methods to Replicate Data from Amazon RDS to Azure Synapse
Method 1: Using Azure Data Factory for Amazon RDS Azure Synapse Migration
This Amazon RDS for SQL Server connector can be used for:
- Copying data through Windows or SQL validation.
- SQL Server version 2005 and above.
- Extracting data by using a stored procedure or an SQL query.
Based on the location of your data store, you need to keep the following prerequisites in mind:
- You can use the Azure integration Runtime if your data store is a managed cloud data service. If the access is limited to IPs approved by firewall rules, you’ll have to grant access to the Azure Integration Runtime IPs.
- You need to set up a self-hosted integration runtime to connect to your data store if it is located in an on-premises network, an Amazon Virtual Private Cloud, or an Azure virtual network.
For this Amazon RDS to Azure Synapse ETL method, you’ll first need to create an Amazon RDS for SQL Server-linked service in the Azure portal UI.
- Go to the Manage tab in your Azure Synapse workspace, choose Linked Services, and click on the +New button.

- Look for the Amazon RDS for SQL Server connector and select it.

- Fill in the details, test the connection, and create the new linked service.

- Repeat the steps for Azure Synapse Analytics and enter the corresponding connection credentials. For Azure Synapse Analytics, managed identity, SQL authentication, and service principal are currently supported.
- Next, you’ll need to create a pipeline that contains a copy activity that will transfer data from Amazon RDS for SQL Server into a dedicated SQL pool.
- Navigate to the Integrate tab, select the plus icon next to the pipelines header, and click on Pipeline.
- Under Move and Transform in the activities pane, drag Copy data to the pipeline canvas.
- After selecting the copy activity, go to the Source tab and click on the New button to create a new source dataset.
- Select Amazon RDS for SQL Server as your data store and pick DelimitedText as your format.
- Within the set properties pane, choose Amazon RDS for SQL Server linked service you created. Mention the file path of your source data and mention whether the first row has a header. You can get the schema from a file or a sample. Click on OK when you’re done.
- Scroll to the Sink tab. Press the New button to make a new sink dataset. Choose Azure Synapse Analytics as your data store and click on Continue.
- Choose the Azure Synapse Analytics linked service you created in the set properties pane. If you’re writing to an existing table, pick it from the dropdown. Or, you can check the Edit option and enter a new table name. Click on OK when you’re done with your customizations.
- If you’re creating a table, you can enable the Auto create table option in the table option field.
After you’ve finished setting up your pipeline, you can perform a debug run before you publish your pipeline to make sure everything is correct.
- To debug the pipeline, choose Debug from the toolbar. You can view the status of the pipeline run in the Output tab at the bottom of the window.
- Once your pipeline has run successfully, you can select the Publish All option. This’ll publish all the components (pipelines and datasets) you created to the Synapse Analytics service.
- Wait for the Successfully Published message, and you’re good to go.
If you want to manually trigger the pipeline published in the previous step:
- Choose Add Trigger from the toolbar, and then select Trigger Now. On the Pipeline Run page, click on the Finish button.
- Scroll to the Monitor tab in the left sidebar to view pipeline runs triggered by manual triggers. You can use links in the Actions column to rerun the pipelines and look at activity details.
- If you want to view the activity runs related to the pipeline run, choose the View Activity Runs link in the Actions column. For this example, since you only have one activity, you’ll only see one entry in the list. For copy operation details, you can select the Details link from the Actions column. Choose Pipeline Runs at the top to return to the Pipeline Runs view. To refresh the view, click on the Refresh option.
- Verify if your data is correctly written in the dedicated SQL pool.
So, Azure Data Factory sounds like the perfect tool to replicate data from any source to Azure Synapse given that they belong to the same suite of products. But, here are a few scenarios where Azure Data Factory might not be the ideal candidate for your replication needs:
- Azure-based Integrations: Azure Data Factory wouldn’t be enough if you’re planning to replicate data from sources outside the Azure environment. Therefore, it works fine for Azure-based data sources, but for other sources, you might need to look for an alternative.
- Analysis Ready Raw Data: The Copy Data tool doesn’t have a lot of transformation capabilities. Therefore, if you’re planning on using it to replicate data, you’ll need to ensure the data is clean, and analysis-ready beforehand.
- One-Time Migration: Azure’s consumption-based pricing might seem like a great idea on paper, but a long-term data pipeline might be a little heavy on your pocket. So, for long-term and repetitive data replication you might want to invest in an alternative.
If you’re facing any or all of these challenges, you can use a no-code data replication solution that completely manages and maintains the data pipelines for you.
Method 2: Using a No-Code Data Replication Tool to Replicate Data from Amazon RDS to Azure Synapse
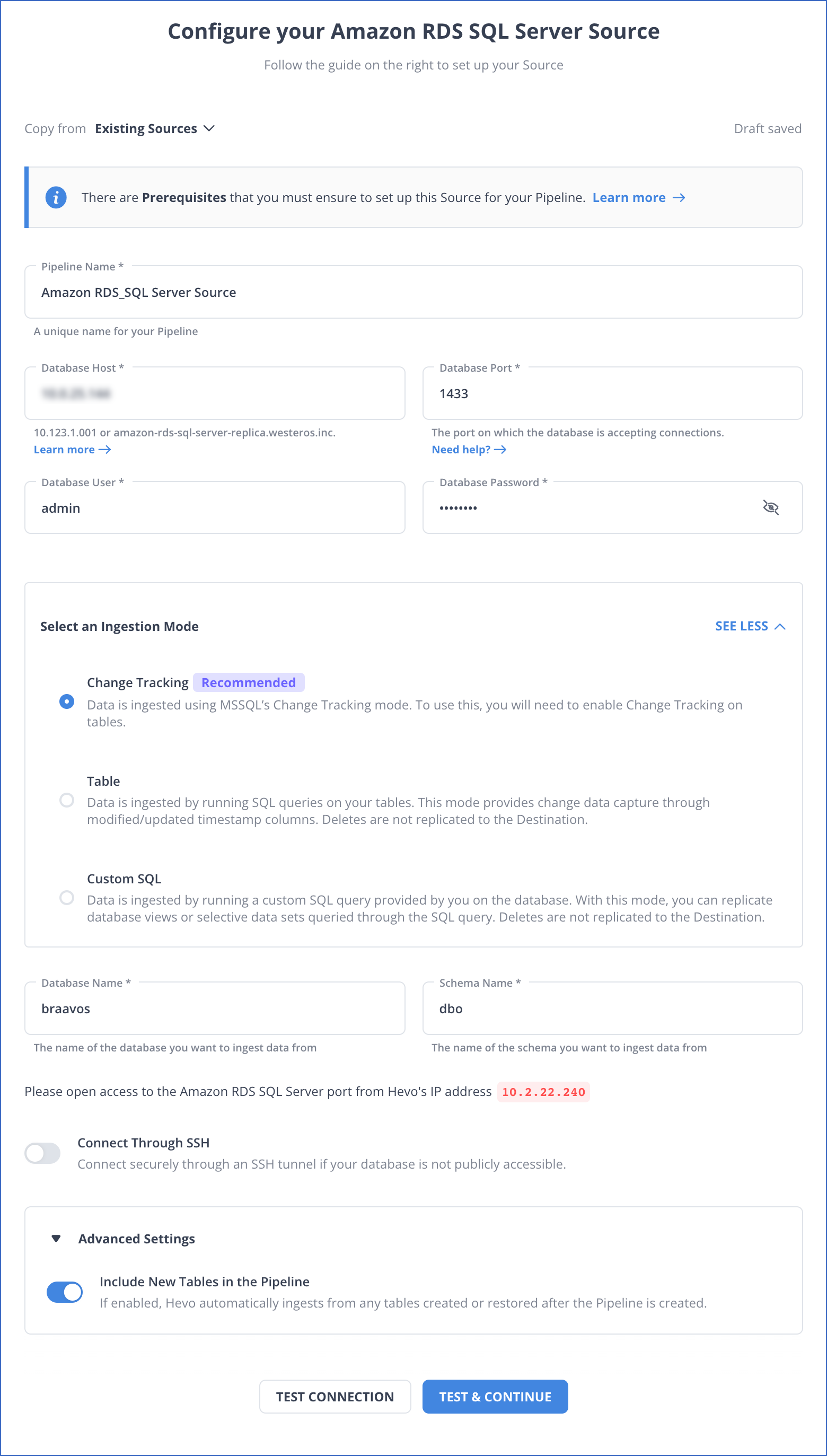
Step 1: Configure Amazon RDS SQL Server as a Source
Step 2: Configure Azure Synapse Analytics as a Destination
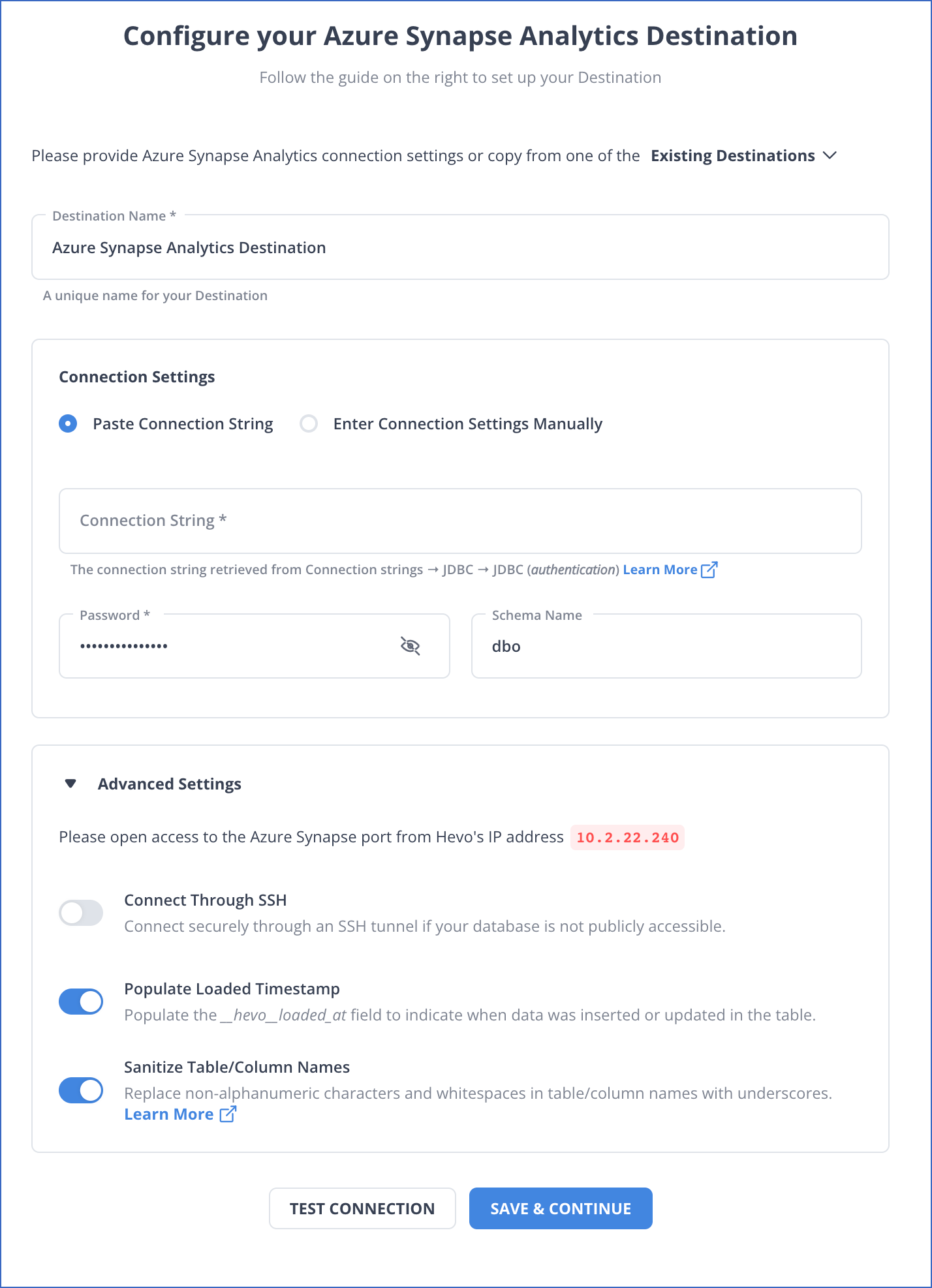
And that’s it! Based on your inputs, Hevo will start replicating data from Amazon RDS to Azure Synapse Analytics.
Point to note: Hevo doesn’t support replication of data to serverless SQL pools in Azure Synapse Analytics.
What can you achieve by replicating data from Amazon RDS to Azure Synapse?
By migrating your data from Amazon RDS to Azure Synapse, you will be able to help your business stakeholders with the following:
- Aggregate the data of individual interaction of the product for any event.
- Finding the customer journey within the product (website/application).
- Integrating transactional data from different functional groups (Sales, marketing, product, Human Resources) and finding answers. For example:
- Which Development features were responsible for an App Outage in a given duration?
- Which product categories on your website were most profitable?
- How does the Failure Rate in individual assembly units affect Inventory Turnover?

Learn More:
- MySQL on Amazon RDS to Azure Synapse
- PostgreSQL on Amazon RDS to Azure Synapse
- Amazon RDS to Azure Synapse
- Amazon S3 to Azure Synapse
Summary
In this article, we’ve talked about two ways that you can use to replicate data from Amazon RDS to Azure Synapse: via Azure Data Factory and through a no-code data replication tool, Hevo.
Hevo allows you to replicate data in near real-time from 150+ sources like Amazon RDS SQL Server to the destination of your choice including Azure Synapse Analytics, BigQuery, Snowflake, Redshift, Databricks, and Firebolt, without writing a single line of code. We’d suggest you use this data replication tool for real-time demands that require you to pull data from SaaS sources. This’ll free up your engineering bandwidth, allowing you to focus on more productive tasks.
Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
Frequently Asked Questions
1. What is the equivalent of AWS RDS in Azure?
The equivalent of AWS RDS (Relational Database Service) in Microsoft Azure is Azure SQL Database.
2. What is AWS equivalent of Azure Synapse?
The equivalent of Azure Synapse Analytics in AWS is Amazon Redshift.
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



