



We, as individual users or an organization, choose Relational Databases for our software system or application as per the requirements. What if the user wants to migrate their data from self-managed, open-source, and commercial Databases to fully managed Databases of the same engine?
Amazon offers a fully managed Amazon RDS and Amazon Aurora relational database service. Users can migrate to AWS databases of the same engine using third-party tools or AWS Database Migration Service (DMS) and AWS Schema Conversion Tool (SCT). We will use AWS DMS to connect widely used commercial and open-source databases, such as Microsoft SQL Server, to Amazon Aurora.
In this article, you will learn the steps to connect Microsoft SQL Server to Amazon Aurora. The source(SQL Server) and target(Aurora) databases must be on AWS services. So, read along to understand more about Amazon Aurora SQL Server Integration.
Table of Contents
What is SQL Server?

SQL Server is a popular Relational Database Management System(RDBMS). Microsoft develops SQL Server, so it is also called Microsoft SQL Server or sometimes MSSQL. SQL Server was initially released on April 24, 1989, and it is written in programming languages like C and C++. SQL Server is extensively used for Windows and launched for Linux systems in 2016.
SQL Server is a versatile database server used to store data and retrieve data by various software applications from local systems and different machines on the network. SQL Server is a relational database system storing data in tabular format, and the relationship between tables is maintained.
For smooth and reliable database transactions, SQL Server follows the principle of ACID properties: Atomicity, Consistency, Isolation, and Durability.
To install SQL Server, you need to go to Microsoft SQL Server Downloads. Further in this article, you will learn about Amazon Aurora SQL Server integration.
Hevo Data, a Fully-managed Data Pipeline platform, can help you automate, simplify & enrich your data replication process in a few clicks. With Hevo’s wide variety of connectors and blazing-fast Data Pipelines, you can extract & load data from 150+ Data Sources, such as SQL Server, Amazon Aurora, straight into your Data Warehouse or any Databases. To further streamline and prepare your data for analysis, you can process and enrich raw granular data using Hevo’s robust & built-in Transformation Layer without writing a single line of code!
Get Started with Hevo for FreeUnderstanding SQL Server Architecture
The architecture of SQL Server is illustrated in the below image:
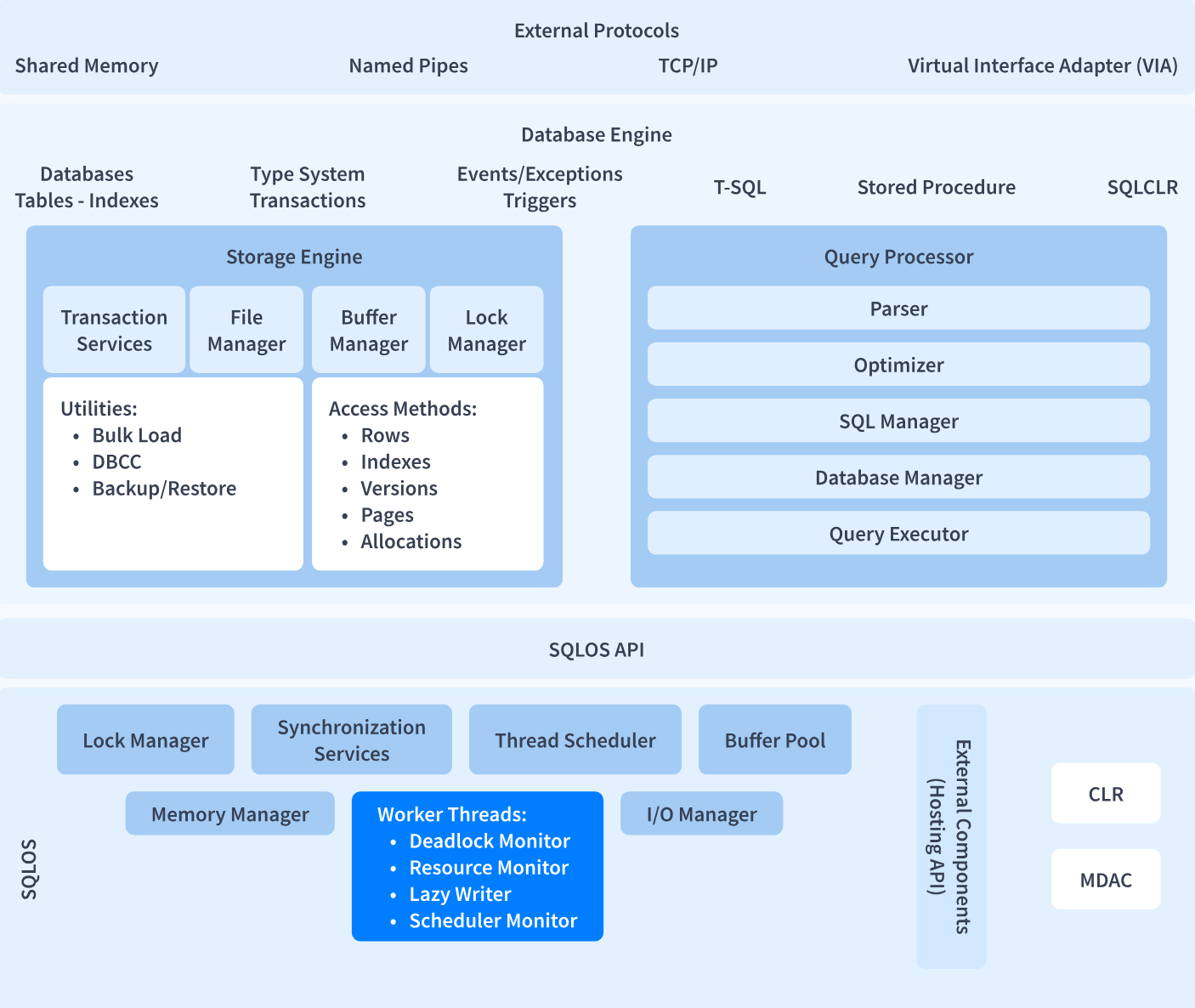
There are two core components of SQL Server:
1) SQL Server Database Engine
Database Engine is the core component of SQL Server which controls data storage, data processing, and data security. It consists of a relational engine that manages SQL commands, queries, and database file storage. It also creates and executes stored procedures, views, triggers, and other database objects.
2) SQLOS
SQLOS is the SQL Server Operating System sitting beneath the SQL Server database engine. SQLOS handles lower-level functions such as job scheduling, memory, I/O management, and data locking to avoid conflict.
A network interface layer sits above the Database Engine and uses external protocols to facilitate request and response interactions with database servers.
What is Amazon Aurora?

Amazon Aurora is a fully managed relational database engine developed by AWS in October 2014. In under a minute, it features built-in security, serverless computing, a high-performance storage subsystem, and cross-region disaster recovery. Designed for cloud-based commercial use, Aurora offers high scalability and durability at one-tenth the cost of traditional solutions.
Aurora is fully compatible with MySQL and PostgreSQL, allowing users to run existing code without modification and easily migrate between these databases. It can deliver up to five times the throughput of MySQL and three times that of PostgreSQL for specific workloads without affecting existing applications. Aurora automatically adjusts storage as needed and simplifies database configuration, automation, clustering, and replication.
Understanding Amazon Aurora Architecture
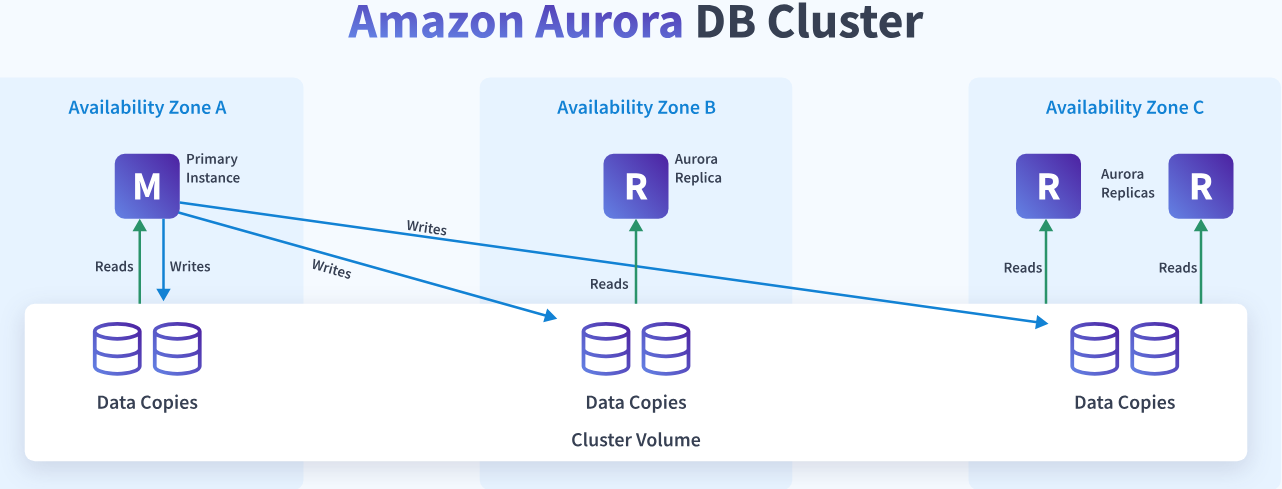
Key points of Amazon Aurora Architecture are
- Amazon Aurora decouples storage and query processing.
- Aurora focuses on reusing its components, making it work like query execution, transaction, and recovery efficient and faster.
- Amazon Aurora ensures safe backups with virtual storage and various data clones creation.
- Aurora prioritizes data access restrictions and stores changelog on the remote disk.
- Aurora uses a primary-replica setup.
Steps to Set Up Amazon Aurora SQL Server Integration

This section will discuss steps to set up Amazon Aurora SQL Server Integration.
Prerequisites
- Configure Your Microsoft SQL Server Source Database as per the instructions mentioned in the AWS documentation.
- Configure Your Aurora MySQL Target Database as per the instructions mentioned in the AWS documentation.
So, let’s get started with the Amazon Aurora SQL Server Integration.
Interested in the key differences between AWS Aurora and Snowflake? Read our comprehensive guide to discover how these platforms differ and which one is right for your use case.
Step 1: Install the JDBC Drivers and AWS Schema Conversion Tool
The first step is to install JDBC drivers for Microsoft SQL Server and Amazon Aurora MySQL and the AWS Schema Conversion Tool (AWS SCT) on your local computer. Do the following:
- Download the JDBC driver for Microsoft SQL Server (mssql-jdbc-7.2.2.jre11.jar) from the link.
- Download the JDBC driver for Aurora MySQL(mysql-connector-java-8.0.29.tar.gz) from here as Amazon Aurora MySQL uses the MySQL driver.
- Download and install AWS SCT based on your operating system.
- Set up AWS SCT. using the below steps:
- Start AWS SCT, choose Settings, and then Global Settings.
- In Global Settings, choose Drivers, and then Browse for Microsoft SQL Server Driver Path.
- Browse the JDBC driver for MySQL driver path, and choose OK.


Step 2: Use the AWS SCT to Connect the SQL Server to Aurora MySQL.
Launch the AWS Schema Conversion Tool(SCT) to connect SQL Server to Aurora MySQL.
- In the AWS SCT, choose File, then choose New Project. Create a new project named Connect SQL Server to Aurora MySQL, specify the project folder’s location, and click OK.
- Choose to add a source database to your project, choose Microsoft SQL Server, and then choose Next.
- Add the below information to connect to the Source Microsoft SQL Server database and choose Test Connection.
| Parameter | Description |
| Connection name | Enter Microsoft SQL Server in this field. |
| Server name | Enter the server name. |
| Server port | Enter the SQL Server port number. The default is 1433. |
| Instance name | Enter the SQL Server database instance name. |
| User name | Enter the SQL Server admin user name. |
| Password | Enter the password for the admin user. |

- Once the test connection is made, click OK to close the alert box and choose Connect for connection with the Microsoft SQL Server database instance. The left panel of AWS SCT displayed the Microsoft SQL Server database instance structure.
- Click on Add target and choose Amazon Aurora (MySQL compatible) to add it as a target database to your project and then click Next.
- Add the below information to connect to the target Amazon Aurora database and choose Test Connection.
| Parameter | Description |
| Connection name | Enter Aurora MySQL in the tree in the right panel. |
| Server name | Enter the server name. |
| Server port | Enter the SQL Server port number. The default is 3306. |
| User name | Enter the Aurora MySQL admin user name. |
| Password | Enter the password for the admin user. |
- Choose OK to close the alert box and then click on Connect connect to the Aurora MySQL database instance.
- Select the source schema in the left panel tree of AWS SCT. In the right panel tree, select your target Aurora MySQL database. And then choose to Create mapping.
- Successful mapping means a successful connection from Microsoft SQL Server to Amazon Aurora.
After a successful connection, we can migrate the SQL Server schema to Aurora and generate reports.
You can also read more about:
Conclusion
In this article, you learned about the Aurora SQL Server Integration. You also understood the detailed steps to set up Aurora SQL Server Integration.
Amazon Web services offer vast, flexible, and fully-managed database services. And also provide an option for schema and data migration to Amazon Aurora. Microsoft SQL Server can successfully connect to the Amazon Aurora database following the above steps.
Similarly, other relational databases can be connected to Amazon Aurora and smoothly migrate their schema and data to Aurora. Read Working with Amazon Aurora MySQL Simplified or Power BI Aurora Integration: 2 Easy Methods to explore more.
Hevo Data is a No-Code Data Pipeline that offers a faster way to move data from 150+ Data Sources including Amazon Aurora, SQL Server, 60+ Free Sources, into your Data Warehouse to be visualized in a BI tool. Hevo is fully automated and hence does not require you to code.
Want to take Hevo for a spin?
Explore Hevo’s 14-day free trial and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Share your experience with Amazon Aurora SQL Server Integration in the comments section below!
Frequently Asked Questions
1. What is Aurora SQL?
Amazon Aurora is a fully managed relational database engine that is part of Amazon Web Services (AWS). It is designed to be compatible with MySQL and PostgreSQL while providing the performance and availability of high-end commercial databases at a lower cost.
2. Which is better RDS or Aurora?
Whether Amazon RDS (Relational Database Service) or Aurora is better depends on specific requirements and use cases. Both are managed database services from AWS, but they have different features and benefits.
3. Is Aurora MySQL or PostgreSQL?
Yes, Amazon Aurora is compatible with both MySQL and PostgreSQL.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





