




Unlock the full potential of your AWS Aurora Postgres data by integrating it seamlessly with BigQuery. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
Replicating data from AWS Aurora Postgres to BigQuery allows organizations to consolidate operational data for advanced data analysis and decision-making.
By utilizing Aurora Postgres’s reliability and scalability with BigQuery’s analytics capabilities, you can derive relevant insights from the AWS Aurora Postgres databases and perform in-depth data analysis in BigQuery with the updated insights and trends. This simplified process empowers improved decision-making.
This article will explore two easy methods for setting up a data replication pipeline from AWS Aurora Postgres to BigQuery.
Table of Contents
AWS Aurora Postgres: A Brief Overview
AWS Aurora Postgres is a fully managed relational database engine compatible with PostgreSQL. It combines the speed, reliability, and manageability of AWS Aurora with the simplicity and cost-effectiveness of the open-source database.
AWS Aurora Postgres allows you to set up, operate, and scale new and existing deployments cost-effectively. You can easily manage routine database tasks, including setting up databases, installing updates, creating backups, recovering data, detecting failures, and fixing issues.
Additionally, you can utilize Aurora Postgres databases to develop HIPAA-compliant applications and store Protected Health Information (PHI) with just a signed Business Associate Agreement (BAA) from AWS.
Method 1: Using Hevo Data to Integrate AWS Aurora Postgres to BigQuery
Hevo Data, an Automated Data Pipeline, provides you with a hassle-free solution to connect GCP Postgre to BigQuery within minutes with an easy-to-use no-code interface. Hevo is fully managed and completely automates the process of loading data from AWS Aurora Postgres to BigQuery and enriching the data and transforming it into an analysis-ready form without having to write a single line of code.
Method 2: Using CSV file to Integrate Data from AWS Aurora Postgres to BigQuery
This method would be time-consuming and somewhat tedious to implement. Users will have to write custom codes to enable two processes, streaming data from AWS Aurora Postgres to BigQuery. This method is suitable for users with a technical background.
Get Started with Hevo for FreeBigQuery: A Brief Overview
BigQuery is a serverless, fully managed data warehouse platform introduced by Google Cloud. It supports Structured Query Language (SQL) for efficiently analyzing and processing large-scale data to uncover valuable insights.
BigQuery is known for its scalability and cost-effectiveness. It can handle terabytes to petabytes of data without complex infrastructure management; you only pay for the resources you utilize.
You can connect to BigQuery in multiple ways, such as through the GCP console, the BigQuery REST API, the bq command line tool, or client libraries such as Java or Python.
Method 1: AWS Aurora Postgres Replication to BigQuery Using Hevo Data
Step 1.1: Configure AWS Aurora Postgres as Your Source Connector
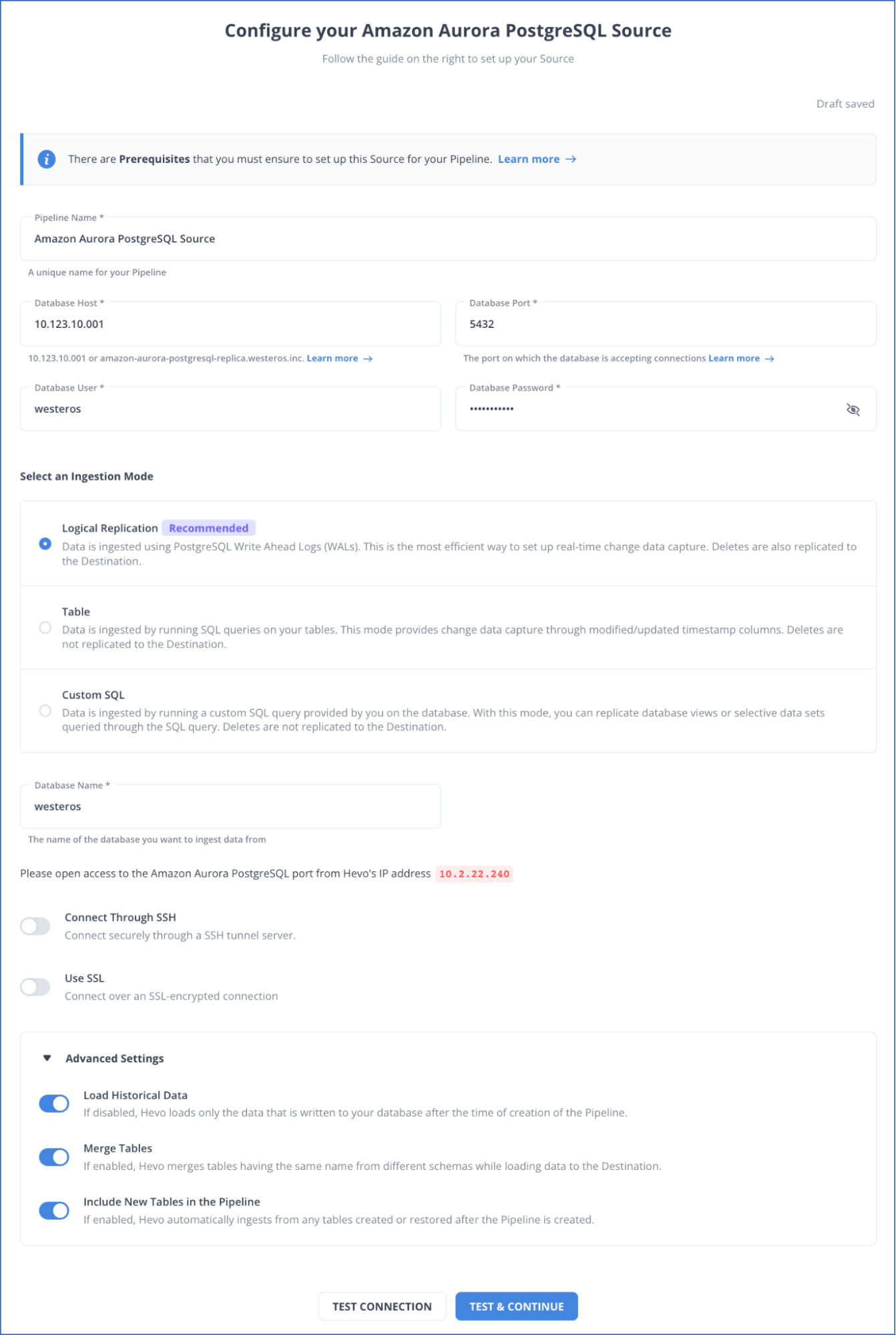
To know more about the source configuration, read Hevo’s Amazon Aurora PostgreSQL Source documentation.
Step 1.2: Configuring BigQuery as Your Destination Connector
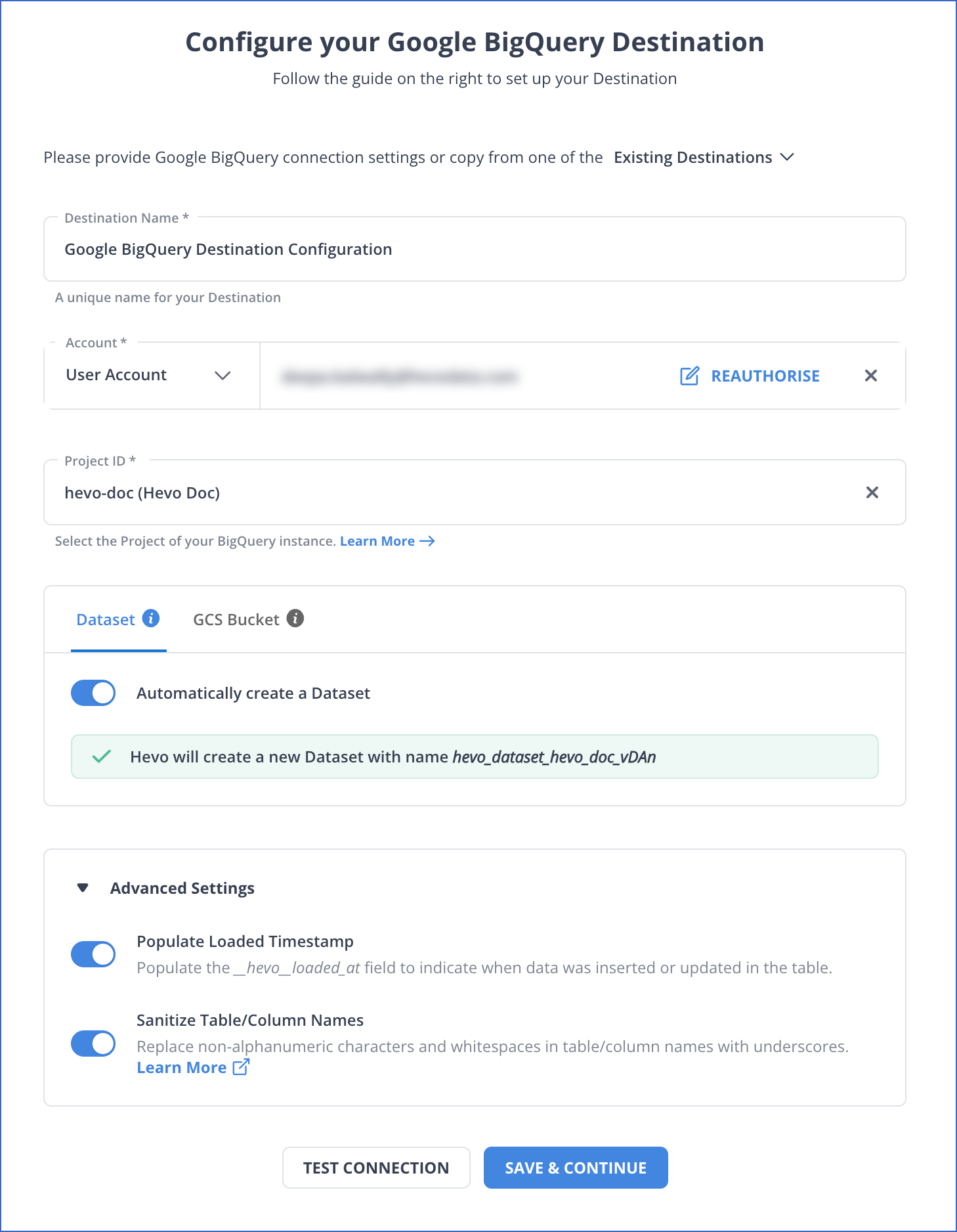
For more information, read Hevo’s Google BigQuery Destination Documentation.
Key Features of Hevo
- Data Transformation: Hevo Data makes data analysis more accessible by offering a user-friendly approach to data transformation. To enhance the quality of the data, you can create a Python-based Transformation script or utilize Drag-and-Drop Transformation blocks. These tools allow cleaning, preparing, and standardizing the data before importing it into the desired destination.
- Auto Schema Mapping: Hevo Data allows you to transfer recently updated data while optimizing bandwidth usage at the source and destination ends of a data pipeline.
- Incremental Data Load: The Auto Mapping feature in Hevo saves you from the difficulty of manually managing schemas. It automatically recognizes the format of incoming data and replicates it in the destination schema. Depending on your data replication needs, you can select between full or incremental mappings.

Method 2: AWS Aurora Postgres Replication to BigQuery Using CSV Export/Import Method
Let’s look into a custom method that demonstrates how to move data from AWS Aurora Postgres to BigQuery using CSV files.
Step 2.1: Export Data from AWS Aurora Postgres into a CSV File
You can use the PostgreSQL COPY command to export data directly from a PostgreSQL table on AWS Aurora to a CSV file.
Use the following command in PostgreSQL to export the data to a CSV file:
COPY tableName TO ‘/path_to/your_file.csv’, DELIMITER ‘,’, CSV HEADER;Let’s look at each element in the command:
- tableName: Provide the name of the table from which you wish to export data.
- /path_to/your_file.csv: Specify the correct location along with the name of the CSV file.
- DELIMITER ‘,’: It specifies a delimiter you wish to use in the CSV file.
- CSV: It denotes the output file should be in CSV format.
- HEADER: It denotes the first row in the CSV file that lists the column names.
Step 2.2: Build a Google Cloud Storage (GCS) Bucket and Upload the CSV File
- Sign into your Google Cloud Console.
- Go to the Storage section and click the Browser option in the left navigation pane.
- Click on the + CREATE BUCKET option to create a new GCS bucket.
- Specify a unique bucket name.
- Select the default storage class and location for your bucket.
- Select the GCS bucket that you have created in the previous step.
- Click UPLOAD FILES to attach the CSV files from your local computer to the GCS bucket.
- When you are redirecting to the file upload dialog box, choose the CSV files exported from AWS Aurora PostgreSQL and upload.

- After completing the CSV file upload, you can see the uploaded CSV files in your GCS bucket.
Step 2.3: Load Data into BigQuery
To load the data into BigQuery, you must use the BigQuery Web User Interface.
- In the top-left corner of Google Cloud Console, click on the Navigation menu.
- Choose BigQuery from the Analytics section.
- Navigate to your Dataset to create a new dataset or table.
- To create a new dataset, select your BigQuery project and choose the Create data set option from View actions (three vertical dots) next to your project name.
- Create a new table in your selected dataset by clicking Create table.
- For the Create table from, select Google Cloud Storage from the drop-down menu.
- Specify the path to the CSV files in the GCS bucket. Select File format as CSV.
- Provide a table name and specify a name, data type, and description for every column in the table.
- Finally, click CREATE TABLE to start the loading process.
Limitations of CSV Export/Import for AWS Aurora Postgres to BigQuery Replication
- Lack of Real-time Data Synchronization: The CSV file method requires manual intervention and doesn’t support automated real-time data syncing; you can only transfer historical data.
- Manual Export Process: Exporting data to CSV files and importing them into BigQuery is a manual task prone to human error. Each data transfer requires coordination and effort; manually handling large-sized CSV files raises the risk of data corruption. Additionally, it is time-consuming to transfer large-sized CSV files.
Use Cases of AWS Aurora Postgres to BigQuery Replication
- Scalability: Organizations with growing data volumes can load large-scale datasets from AWS Aurora Postgres to BigQuery. Both platforms are highly scalable and require minimal upfront investment, helping cost-effectively consolidate data for efficient analysis and reporting.
- Real-time Analytics: Replicating data from AWS Aurora Postgres to BigQuery enables real-time data analytics. With this replication, you can access relevant insights timely to make better decisions.
Also, check out how to move data from Google Analytics to Amazon Aurora and make working with AWS Aurora Postgres even more seamless.
Conclusion
When replicating AWS Aurora Postgres to Google BigQuery, you can efficiently manage and analyze your organization’s operational data.
Instead of relying on a time-consuming CSV export/import method, you can utilize the Hevo Data platform, especially for applications that require real-time synchronization.
Hevo’s readily available connectors help streamline the AWS Aurora Postgres to BigQuery replication process. The platform eliminates manual intervention, saves time, and reduces the possibility of data loss.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions (FAQs)
1. Should I opt to load the data directly into BigQuery from AWS Aurora Postgres, or would it be more advantageous to export it to CSV format first?
Loading the data directly into the BigQuery destination saves you time and effort. Hevo Data provides readily available source and destination connectors to effortlessly migrate the data from AWS Aurora Postgres to BigQuery.
However, exporting to CSV files is more suitable when the datasets are small or when there are infrequent data migrations.
2. How to transfer data from Postgres to BigQuery?
You can use Hevo to transfer data from Postgres to BigQuery seamlessly without coding, ensuring real-time sync. Other methods include using Google Cloud’s Data Transfer Service or writing ETL scripts.
3. Can I use PostgreSQL in BigQuery?
No, you can’t directly use PostgreSQL in BigQuery, but you can load and analyze PostgreSQL data in BigQuery.
4. Is AWS Aurora compatible with Postgres?
Yes, AWS Aurora is fully compatible with PostgreSQL, allowing you to use Aurora as a drop-in replacement for PostgreSQL.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



