

AWS Glue is a powerful data integration service that prepares your data for analytics, application development, and machine learning using an efficient extract, transform, and load (ETL) process.
The AWS Glue service is rapidly gaining traction, with more than 6,248 businesses worldwide utilizing it as a big data tool. With1 3,139 customers (59.97%) in the United States, US-based businesses are the majority of those leveraging AWS Glue for big data. India and the United Kingdom follow, with 533 (10.18%) and 470 (8.98%) users, respectively.
This blog will dive deep into AWS Glue Services, exploring its core components, how it operates, and real-world use cases. We’ll also discuss scenarios where AWS Glue excels and when you might want to consider alternative ETL tools. Read on to discover why many organizations trust AWS Glue for their data integration needs.
Table of Contents
Introduction to AWS Glue Service
AWS Glue is a cloud-based, fully managed serverless data integration tool that makes it easier to extract, convert, and load data from several sources into a target data store. Launched by Amazon Web Services in August 2017, AWS Glue was designed to streamline data preparation tasks, enabling organizations to focus on their ETL operations without worrying about server deployment or software installation.
AWS Glue’s serverless data integration services handle all of the underlying infrastructure. It reduces the overhead associated with provisioning and managing resources, enabling faster development cycles. You can find and connect to more than 70 different data sources, manage your data in a single data catalog, and graphically develop, run, and monitor ETL pipelines to load data into your data lakes.
Looking for the best ETL tools to connect your data sources? Rest assured, Hevo’s no-code platform helps streamline your ETL process. Try Hevo and equip your team to:
- Integrate data from 150+ sources(60+ free sources).
- Eliminate the need for manual schema mapping with the auto-mapping feature.
- Instantly load and sync your transformed data into your desired destination.
Don’t just take our word for it—try Hevo and experience why industry leaders like Whatfix say,” We’re extremely happy to have Hevo on our side.”
Get Started with Hevo for FreeHow does AWS Glue Stand Out Among ETL Tools?
Glue is different from other ETL products in 3 different ways.
First, Glue is serverless. You simply point Glue to all your ETL jobs and hit run. You don’t have to set up, provision, or spin up computers. Also, you don’t have to manage their lifecycle.
Second, Glue provides crawlers with automatic schema inference for your semi-structured and structured data sets. Crawlers find all of your data sets, file types, and schemas instantly. They then store all of this information in a central metadata catalog so that it can be queried and analyzed later.
Third, Glue automatically generates the scripts that you need to extract, transform, and load your data from source to Target, so you don’t have to start from scratch.
How AWS Glue Works?
AWS Glue coordinates and manages ETL activities to create data lakes, warehouses, and output streams using other AWS services. AWS Glue makes API requests to process data, generate runtime logs, store job logic, and provide notifications to assist you in keeping track of your task runs.
You don’t have to worry about infrastructure creation for ETL; the services do it. When resources are needed, AWS Glue runs your workload on an instance from its warm pool of instances to save startup time. The data is cataloged using crawlers, ETL scripts are generated automatically, and jobs and scripts are scheduled to handle data with minimal human input.
The AWS Glue console manages administration and job development. You can concentrate on developing and overseeing your ETL work by connecting these services into a managed application using the AWS Glue console. You just have to provide credentials and attributes for AWS Glue to access and publish your data sources and targets.
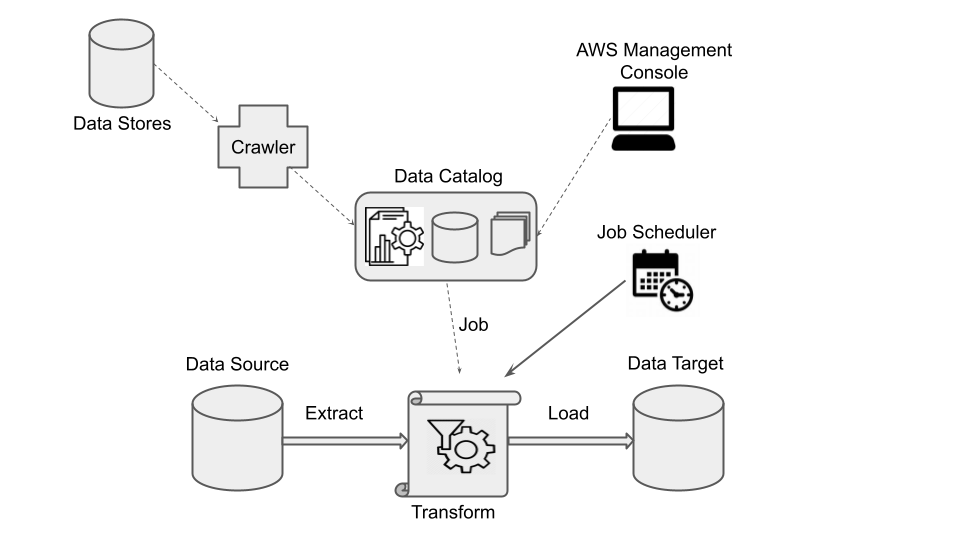
The figure shows AWS Glue’s environment and operation. The top left indicates data sources. Data crawlers retrieve information from data sources and targets. This metadata is then stored in the data catalog. The AWS management console allows users to interact with the system.
AWS Glue jobs are created from Data Catalog table definitions. Jobs consist of scripts that include the programming logic to transform from sources to targets. ETL Jobs are triggered by the job scheduler either automatically or in response to predefined events. Eventually, the ETL pipeline takes data from sources, transforms it as needed, and loads it into data destinations.
Key Features of AWS Glue
1. Data Integration Engine Options
AWS Glue provides serverless scalable data integration service with automatic scaling and pay-as-you-go pricing. It offers many data integration engines to help customers and their work. Depending on the workload’s structure and what your developers and analysts want, you can use the right engine for any task.
- AWS Glue for Apache Spark- Provides a performance-optimized, serverless infrastructure for running Apache Spark for data integration and extracting, transforming, and loading (ETL) jobs.
- AWS Glue for Ray- Allows data engineers and developers to scale up Python workloads on large datasets using Ray (Ray.io), an open-source unified compute framework.
- AWS Glue for Python Shell- Allows users to write complex data integration and analytics jobs in Python.
- Amazon Q data integration in AWS Glue: It allows you to use natural language to build data integration workflows. You can use a chat interface to explain what you want, and Amazon Q data integration in AWS Glue will generate a full job.
2. Event-driven ETL
It supports event-driven triggers for ETL jobs, such as when new data arrives in data sources. This allows maintaining up-to-date data and supports real-time processing without the need for manual intervention.
3. AWS Glue Data Catalog
The Data Catalog is a persistent metadata store that brings together the structure and metadata of your data from different sources like Amazon S3 and Amazon DynamoDB. This tool lets you quickly find and look through many AWS datasets without having to move the data. Once the data is cataloged, Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum can be used right away to look for and query it. How do you fill out the metadata in the catalog? Data crawlers and classifiers are in charge of this. They look at data from different sources and choose the suitable schema for that data. After that, the meta-data is saved in the data catalog.
4. No-code ETL Jobs
AWS Glue Studio makes visually creating, running, and monitoring AWS Glue ETL jobs easier. You can build ETL jobs that move and transform data using a drag-and-drop editor, and AWS Glue automatically generates the code.
5. Manage and monitor data quality
AWS Glue Data Quality automates the creation, management, and monitoring of data quality rules. Setting up these checks manually is time-consuming and prone to errors. AWS Glue Data Quality streamlines this process, reducing the time needed from days to hours. It automatically computes statistics, recommends quality rules, monitors data, and alerts you to any issues. It uses ML algorithms to solve hidden and complex problems. AWS Glue Data Quality is built on DeeQu, an open-source tool developed at Amazon, which only needs users to describe how their data should look rather than implement complex algorithms.
6. Data Preparation
AWS Glue DataBrew helps you prepare data for AWS Glue. It lets you explore and play with data straight from your data lake, data warehouses, and databases. You can profile data, see patterns in it, and pick from more than 250 pre-built transformations to automate jobs like filtering out anomalies, standardizing formats, and fixing invalid ones. AWS Glue Studio also has a data preparation tool that lets you get data ready with a visual, interactive dashboard that you can use without writing code.
Use Cases of AWS Glue
1. ETL Pipeline Development
AWS Glue is ideal for ETL pipeline development, supporting complex transformations and integration from over 70 data sources. It simplifies ETL processes with tools to build, execute, and monitor jobs. It removes infrastructure management with automatic provisioning and worker management and consolidates all your data integration needs into a single service.
2. Data Processing and Transformation
Using AWS Glue interactive sessions, data engineers can interactively explore and prepare data using their chosen integrated development environment (IDE) or notebook. It also provides over 250 prebuilt transformations to automate data preparation tasks such as filtering anomalies, standardizing formats, and correcting invalid values.
3. Data Cataloging and Management
The data catalog service facilitates effective data discovery and management. It quickly identifies data across AWS, on-premises, and other clouds and then makes it instantly available for querying and transforming.
4. Supports various Processing Frameworks and Workloads
More easily support various data processing frameworks, such as ETL and ELT, and various workloads, including batch, micro-batch, and streaming.
AWS Glue vs. Other Services
1. AWS Glue vs. AWS Lambda
AWS Lambda: Designed to run code in response to events. Ideal for event-driven applications (e.g., data changes in S3, DynamoDB)
AWS Glue: Fully managed ETL service designed for data integration. Ideal for automating ETL processes, including data discovery, cleansing, transformation, and loading.
2. AWS Glue vs. Amazon EMR
Amazon EMR(Elastic MapReduce): A cloud big data platform with a managed Hadoop framework. Supports a range of big data applications (e.g., Hadoop, Spark, HBase, and Presto). And is more suitable for customized, complex big-data processing
AWS Glue: Focuses on simplifying and automating ETL tasks. It is more suitable for automatic data management and ETL
3. AWS Glue vs. Apache Spark
Apache Spark: Open-source data processing engine. Used for big data analytics and machine learning. Provides extensive control and flexibility for data processing
AWS Glue: A managed ETL service that utilizes Spark for data processing but abstracts away cluster management, simplifying the ETL process and reducing infrastructure concerns.
Benefits of Using AWS Glue
1. Orchestration
You don’t need to set up or maintain infrastructure for ETL task execution. Amazon takes care of all the lower-level details. AWS Glue also automates many things. You can quickly determine the data schema, generate code, and customize it. AWS Glue simplifies logging, monitoring, alerting, and restarting in failure cases as well.
2. Scalability and Flexibility
It is very scalable and flexible. The platform can scale on demand to accommodate gigabyte to petabyte data sizes without significant performance degradation. It is flexible and provides support for all workloads—ETL, ELT, batch, streaming, and more.
3. Work well with other AWS tools.
Data sources and targets such as Amazon Kinesis, Amazon Redshift, Amazon S3, and Amazon MSK are very easy to integrate with AWS Glue. Additionally, other popular data storages that can be deployed on Amazon EC2 instances, such as PostgreSQL and MongoDB, are also compatible with AWS Glue.
4. Only pay for the Resources you use
Glue can be cost-effective because users only pay for the resources consumed. If your ETL jobs occasionally require more computing power but generally consume fewer resources, you don’t need to pay for the peak-time resources outside of this time.
5. Ease of Use
User-friendly interface and tools. All in one-Complete data integration capabilities in one serverless service
Limitations and Challenges of AWS Glue
1. Learning Curve
Setting up and configuring AWS Glue can be complex for users who are new to AWS or ETL processes. While Glue provides many built-in transformations, highly customized ETL processes may require additional coding and fine-tuning. Since Glue runs on Apache Spark, understanding Spark concepts is often necessary for more advanced use cases.
2. Performance Considerations
Job start times can be late, particularly for large jobs or when many jobs are queued. Performance may be impacted by the shared nature of the underlying infrastructure, which can sometimes lead to resource contention. Debugging ETL jobs in Glue can be challenging due to the distributed nature of Spark jobs and the complexity of the Glue job scripts.
3. Schema Management
Handling schema changes can be complex and may require manual intervention to update the Glue Data Catalog or ETL scripts. Automatic schema detection may not always correctly interpret complex or nested data structures, requiring manual adjustments.
4. Batch-Oriented
AWS Glue is primarily designed for batch ETL processes and may not be the best choice for real-time or near-real-time streaming data integration, although it does support some streaming capabilities.
5. Integration Challenges
Using AWS Glue ties your data processing and ETL workflows to the AWS ecosystem. While Glue is optimized for working with other AWS services, this lack of integrations to products outside the AWS ecosystem would limit your choices when building an open lake architecture. Also, Users have limited control over the underlying infrastructure, which can be a drawback for specific performance-tuning requirements.
6. Complex Pricing structure
The pay-as-you-go pricing model can lead to unpredictable costs, especially with large-scale data processing tasks. Also, costs can accumulate from additional AWS services with which Glue interacts.
Conclusion
AWS Glue is a robust choice for data integration tasks, particularly if you’re looking for a fully managed, scalable, and cost-effective solution. It streamlines ETL processes, integrates well with the broader AWS ecosystem, and offers powerful data cataloging features. However, the decision to use AWS Glue should also consider factors like specific use case requirements, integration with existing tools, and potential learning curves.
Transform your data effortlessly with AWS Glue DataBrew. Clean and prepare your data with a no-code interface.
If your concern is real-time data integration with minimal effort and ease of use for non-technical users, then Hevo is an ideal platform. Hevo is popular for its low-code data integration, user-friendly interface, and reliable data pipelines. Its pre-built connectors, automated schema management, and support for post(ELT) and pre(ETL) load transformations provide significant advantages, making it a strong competitor among modern ETL tools.
Frequently Asked Questions
1. What is AWS Glue and what can it do?
AWS Glue is a serverless data integration service that helps you discover, prepare, move, and integrate data from various sources. It can clean, categorize, and enrich data, while allowing you to move it across data stores and streams. You only pay for the resources used, and it can scale up or down as needed.
2. What are the main features of AWS Glue?
AWS Glue offers several key features, including the Glue Data Catalog for organizing data metadata, DataBrew for no-code data preparation, a scalable data integration engine, and a centralized system for monitoring jobs and troubleshooting issues.
3. When is AWS Glue a good choice to use?
AWS Glue is ideal for users who need a simpler, cohesive data pipeline, especially when working with raw data that requires ETL. It’s also great for users relying on a variety of tools for extended periods.
References
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




