
When designing Data Movement Workflows, it is also important to design how these Data Movement Workflows will be executed. Azure Pipeline Triggers play an important role while building your software applications. They determine when a particular pipeline should be run and automate the process of deploying the latest changes to your environments without requiring manual intervention from a DevOps engineer.
One of the best advantages of Azure Pipelines is that you can combine Continuous Integration (CI) and Continuous Delivery (CD) to test and build your code and ship it to any target. Azure Pipelines come with multiple options to configure pipelines: upon a push to a repository, at scheduled times, or upon the completion of another build.
This article provides information about the various types of Azure DevOps Pipeline Triggers and the general schema for using those triggers. We will discuss Azure Pipeline YAML Triggers for continuous integration and pull requests. We will also explore Build Completion Trigger, an Azure Pipeline Trigger another pipeline in classic build pipelines that start a pipeline when another one finishes. Finally, we’ll wrap off the article with filters for your Azure Pipelines like Branch, Tag, Stage, and Path.
Table of Contents
What Is Microsoft Azure?

Microsoft Azure is a Cloud Computing Platform that offers businesses computing, analytics, storage, and networking services on the cloud. With Microsoft Azure, your company engages in a much more reliable and quality-driven process of storing and transforming your data, based on your requirements. With Azure Data Factory triggers, you can efficiently schedule and automate data pipelines, ensuring timely data transformation and movement across services.
Since the launch of AWS Cloud Computing Services, Microsoft Azure has positioned itself as the second biggest cloud alternative. It comes in three modes- Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS), and offers a surplus of tools that can propel your business to new heights of success. Microsoft Azure is trusted and used by Fortune 500 Companies, so you can be sure of their power-packed services.
What Is Azure Pipeline?
DevOps brings developers and operations teams together for continuous delivery of value to your end consumers. Implementing the DevOps approach for a faster application or service delivery using the Microsoft Azure Cloud is called Azure DevOps.
Azure Pipeline is one of the services included in Azure DevOps that allows developers and operations teams to create pipelines on the Azure Cloud Platform. A pipeline is a set of automated processes that allow developers, DevOps teams, and others to build and deploy their code reliably and efficiently. Using Azure Pipelines, developers can automatically run builds, perform tests, and deploy code (release) to Azure Cloud and other supported platforms.
Azure Pipeline is similar to open-source Jenkins or Codeship. It provides Continuous Integration and Continuous Deployment (CI/CD) processes with the freedom to work with containers and support for Kubernetes. Azure Pipeline is also platform and language independent. You can use Azure Pipelines to build an app written in any language, on multiple platforms at the same time.
Hevo Data is a No-code Data Pipeline. With the help of Hevo, you can get data into Azure to simplify the process of data analysis and visualization. It supports 150+ data sources and loads the data onto the desired Data Warehouse, enriches the data, and transforms it into an analysis-ready form without writing a single line of code.
Let’s see some unbeatable features of Hevo Data:
- Fully Managed: Hevo Data is a fully managed service and is straightforward to set up.
- Schema Management: Hevo Data automatically maps the source schema to perform analysis without worrying about the changing schema.
- Real-Time: Hevo Data works on the batch as well as real-time data transfer so that your data is analysis-ready always.
- Live Support: With 24/5 support, Hevo provides customer-centric solutions to the business use case.
What Is Azure Pipeline Trigger?
Azure Pipeline Triggers are automated ways to execute Azure Pipelines at the correct time. Relying on manual intervention to execute a specific pipeline might not serve well, especially if you want to deploy a pipeline during the night or on holidays. With Azure Pipeline Triggers, your users can configure a pipeline to work against some internal/external event, or at scheduled time intervals and at the right time.
When automated builds are configured to run on an Azure Pipeline Trigger or a frequent schedule, it is often referred to as Continuous Integration (CI) or Continuous Build (CB). Using Azure Pipeline Triggers, users get to orchestrate their DevOps process in an efficient manner and automate their CI/CD.
Broadly speaking, there are three types of Azure Pipeline Triggers:
Resource Triggers
Resource Triggers are triggered by the resources defined in your pipeline. These resources can be pipelines, builds, repositories, containers, packages, or webhooks sources.
Resource Triggers allow you to fully track the services utilized in your pipeline, including the version, artifacts, associated changes, and work items. When a resource is defined, it can be consumed anywhere in your Azure Pipeline. Furthermore, by subscribing to trigger events on your resources, you may fully automate your Azure DevOps Workflow.
Here is a generic schema for Resource Triggers:
resources:
pipelines:
- pipeline: string
source: string
trigger: # Optional; Triggers are enabled by default.
branches: # branch conditions to filter the events, optional; Defaults to all branches.
include: [ string ] # branches to consider the trigger events, optional; Defaults to all branches.
exclude: [ string ] # branches to discard the trigger events, optional; Defaults to none.
stages: [ string ] # trigger after completion of given stage, optional; Defaults to all stage completion. stages are OR'd
tags: [ string ] # tags on which the trigger events are considered, optional; Defaults to any tag or no tag. tags are OR'dWebhook Triggers
Webhooks are basic HTTP callback requests, triggered by an event in a source system and sent to a destination system. Webhook Triggers allow users to subscribe to external events and enable Azure Pipelines YAML Triggers as part of their pipeline YAML design.
You can establish a Webhook Event based on any HTTP event and provide the destination to receive the event via the payload URL. Your Webhook Triggers can be initiated by a repository commit, PR remark, registry update, or a simple HTTP post request.
Webhook Azure Pipeline Triggers differ from Resource Triggers in a few ways. There is no traceability since there is no downloadable artifact component or version connected with each event. Still, you can utilize Webhook Event which provides a JSON payload for basic event analysis.
The schema for Webhook Triggers is as follows:
resources:
webhooks:
- webhook: string # identifier for the webhook
connection: string # incoming webhook service connection
filters: # JSON paths to filter the payload and define the target value.
variables: # Define the variable and assign the JSON path so that the payload data can be passed to the jobs.Schedule Triggers
Schedule Triggers operate at scheduled intervals specified by the user and are helpful for cases when you want to run long-running builds or repeated tasks on a schedule.
These Azure Pipeline Triggers offer customizable scheduling options ranging from minutes to hours, days, and weeks. You can even run Schedule Azure Pipeline Triggers for a fixed time span, by specifying the start date and end date of your program.
To define and run Schedule Triggers, you can either use the Pipeline Settings UI or configure it to run on a scheduled basis using a CRON syntax. Most users who work with Azure Pipeline Triggers find Pipeline Settings UI to be a simpler option. You just need to enter your schedule frequency along with Branch Filters, and your Schedule Triggers are live.

Another way to define and run Azure Pipelines YAML Triggers is by using CRON syntax. These Azure DevOps YAML Triggers are defined as follows:
schedules:
- cron: string # cron syntax defining a schedule
displayName: string # friendly name given to a specific schedule
branches:
include: [ string ] # which branches the schedule applies to
exclude: [ string ] # which branches to exclude from the schedule
always: boolean # whether to always run the pipeline or only if there have been source code changes since the last successful scheduled run. The default is false.Quick Note: If you schedule your Azure DevOps YAML Triggers using both the UI settings and the CRON syntax, the UI settings will be given precedence over your syntax. To define Azure DevOps YAML Triggers using CRON, you must remove Scheduled Triggers defined in your Pipeline Settings UI.
To view your upcoming scheduled runs for a specific pipeline, you can visit the Kebab Menu (three dots) and click the option “Scheduled runs”. You can also check your completed Scheduled Triggers from the option Trigger Runs > Schedule.
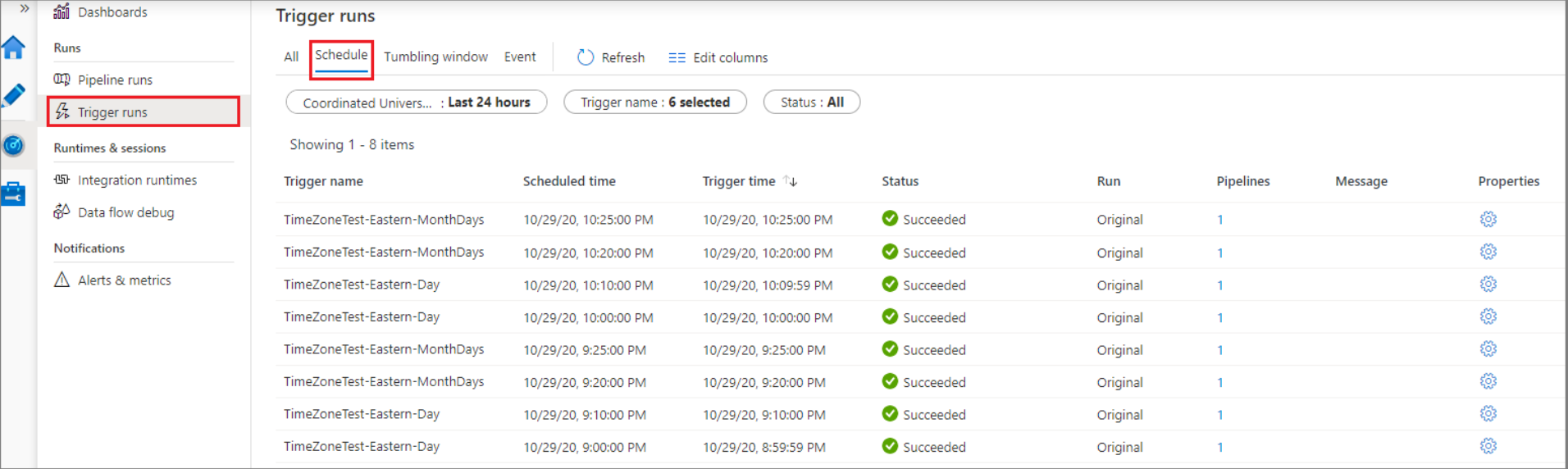
Azure Pipelines Triggers For Classic Build Pipelines & YAML Pipelines
Another set of Azure Pipeline Triggers that you can use to trigger a build pipeline for continuous integration and pull requests come through the use of Azure DevOps Build Pipeline Trigger. Based on your pipeline type and requirements, you can select the appropriate ones as provided below:
Continuous Integration (CI) Triggers
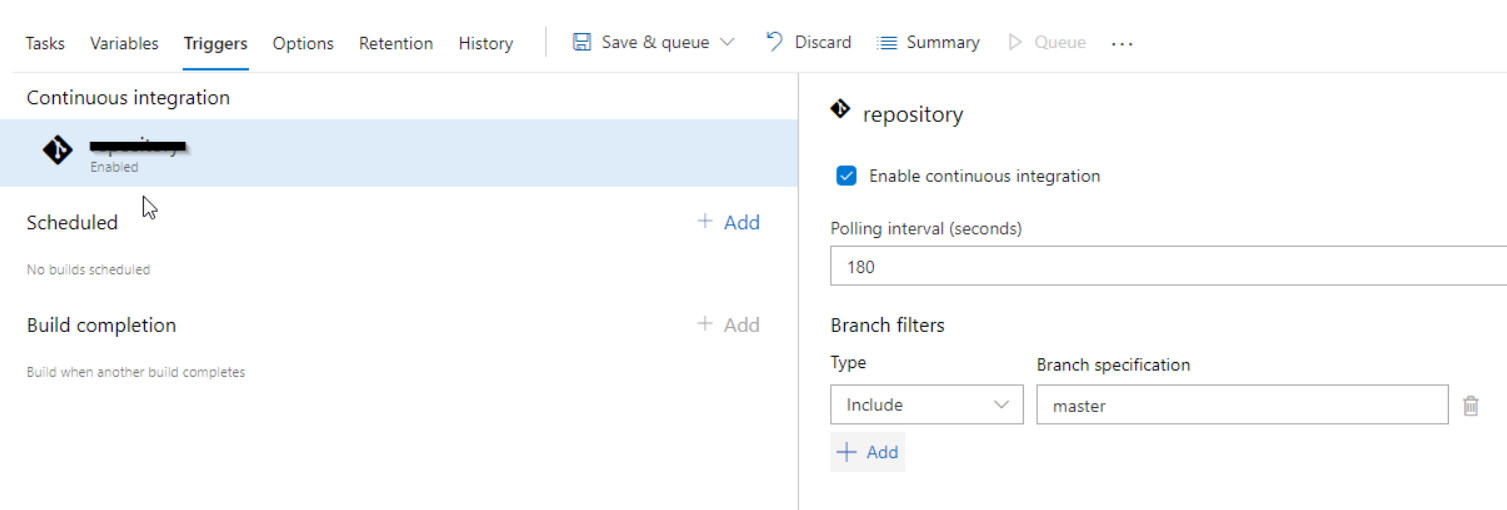
Continuous Integration (CI) Triggers start a pipeline every time you push an update to the specified branches or tags. By default, builds are configured with a CI Trigger on all branches. For a granular control on which branches and file paths should get triggered, you can use the following syntax to specify your requirements:
# specific path build
trigger:
branches:
include:
- master
- releases/*
paths:
include:
- docs
exclude:
- docs/README.mdHere, you can include the branches/file paths you want to trigger by specifying them under “include:”, and exclude the branches you don’t want to trigger by specifying them under “exclude:”. You can also configure triggers based on refs/tags by using the following syntax:
# specific tag
trigger:
tags:
include:
- v2.*
exclude:
- v2.0In case you would like to disable the CI Triggers on your builds, you can specify the same using the option “trigger: none”.
# A pipeline with no CI trigger
trigger: nonePull Request Validation (PR) Triggers
Pull Request Validation (PR) Triggers start a pipeline when you open a pull request or make modifications to it. A pull request, also known as a merge request, is when a contributor/developer has reviewed the code changes and is ready to merge the code into the master branch.
Azure Pipeline Triggers enable this functionality using branch policies. You can navigate to the branch policies for the selected branch and configure the build validation policy for that branch to allow PR validation.
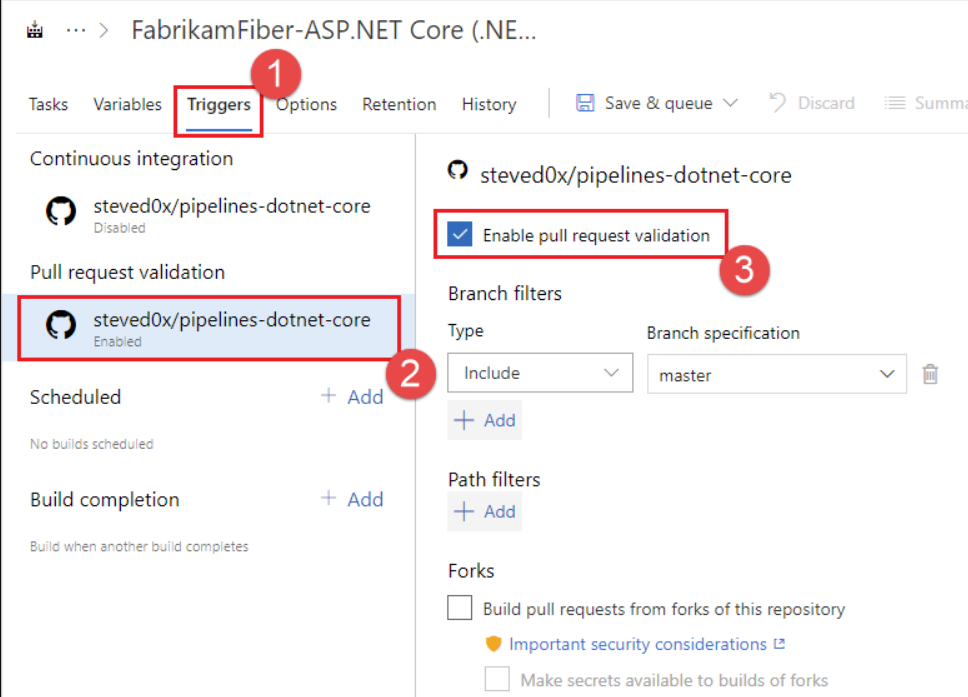
When you have an open pull request, and you submit modifications to its source branch, multiple pipelines can run. The pipeline provided by the target branch’s policy will execute on the commit corresponding to the merged pull request regardless of whether there are pushed commits whose messages or descriptions contain “[skip ci]”.
If there are pushed commits with [skip ci] (or any of its variants) in their messages or descriptions, the pipelines triggered by changes to the pull request’s source branch will not execute. And for cases when you merge the pull request, even if any of the merged commits’ messages or descriptions include [skip ci], the pipelines triggered by changes to the target branch’s policy will execute.
pr:
branches:
include:
- master
- rel/*
paths:
include:
- *
exclude:
- README.mdBuild Completion Triggers
Any changes to the upstream services must be matched by changes to the downstream services. These new changes may need to be recreated or re-validated at times. In software companies, multiple products or components are produced independently, yet they all rely on each other. Seamless creation of such products requires you to use Build Completion Triggers, in which a CI build triggers a build upon the successful completion of another build.
You can add the Build Completion option by clicking the Add button and selecting Triggering build from the dropdown.
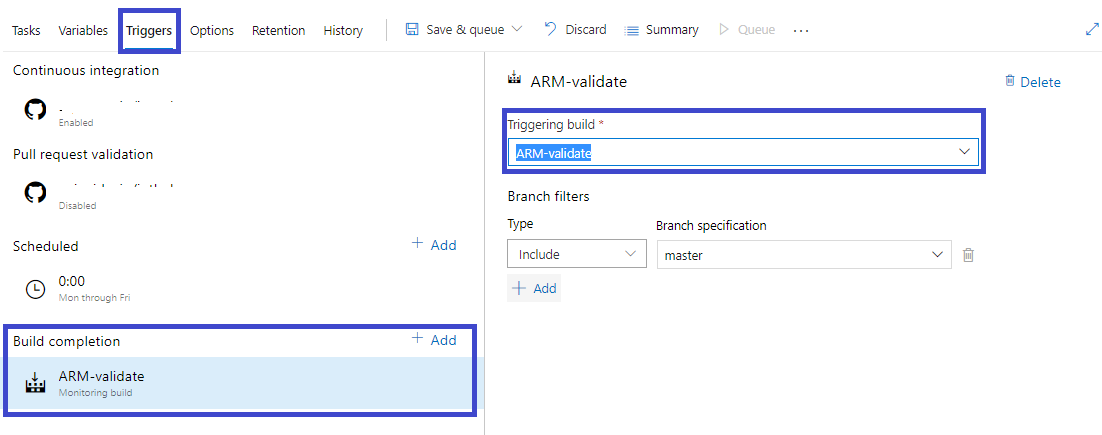
Azure Pipelines Trigger Filters
Branch Filters
Branch Filters allow you to trigger the build only when specified criteria are matched. When setting the Azure Pipeline Trigger, you may define which branches to include or exclude.
When Branch Filters are specified, a new pipeline is started whenever a Source Pipeline run that matches the Branch Filters is successfully finished. Branch filters also allow wildcard characters like “features/modules/*” while configuring a branch specification. To use them, you can type the branch specification and then press Enter.
# sample YAML pipeline
resources:
pipelines:
- pipeline: masterlib
source: master-lib-ci
trigger:
branches:
include:
- feature/*
- releases/*
exclude:
- releases/old*Tag Filters
Tags are labels on work items in Azure DevOps. They are critical since they serve as metadata to help you sort, organize, and find records. Tag Filters allow you to specify and find which pipeline creation events can trigger your pipeline. If the triggering pipeline matches all of the tags in your tags list, the pipeline gets executed.
resources:
pipelines:
- pipeline: masterlib
source: master-lib-ci
trigger:
tags:
- tag1 # Tags are AND'ed
- tag2Stage Filters
Stage Filters allow Azure Pipeline trigger another pipeline when one or more stages of the Triggering Pipeline are complete. If configured for multiple stages, the Stage Filter will check for completion of all the stages and then initiate your pipeline.
resources:
pipelines:
- pipeline: masterlib
source: master-lib-ci
trigger:
stages:
- stage1
- stage2 Path Filters
Path Filters provide the option of triggering a build based on the paths of updated files in a particular commit. The sequence in which Path Filters are applied doesn’t matter, and paths are case-sensitive. As a result, if the route does not match a certain path, the build will not be triggered.
Learn More:
Conclusion
This guide demonstrated how you can set up and configure Azure Pipeline Triggers with different options – Resource, Webhook, and Schedule Triggers along with Continuous Integration Triggers, Pull Request Triggers and Build Completion Triggers. These were accompanied by Azure Pipeline Filters like Branch, Tag, Stage, and Path. Using Azure Pipelines, you get to combine continuous integration (CI) and continuous delivery (CD) to test and build your code and ship it to any target.
Unlock powerful automation by integrating Azure with webhooks. Improve data handling and process automation. Hevo Data, a No-code Data Pipeline Platform, provides you with a consistent and reliable solution to manage data transfer from 150+ Data Sources (40+ Free Sources) like MS SQL Server, and Azure SQL Database to your desired destination like a Data Warehouse or Database in a hassle-free format.
Why not take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. You may also have a look at the unbeatable pricing, which will assist you in selecting the best plan for your requirements.
Thank you for your time. If you have any queries concerning Azure Pipelines YAML Triggers, please leave them in the comments section below.
FAQs
1. How do you trigger a pipeline in Azure DevOps?
A pipeline can be triggered manually, through a push to a repository, or on a schedule, based on your YAML or classic pipeline settings.
2. Can you schedule a pipeline in Azure DevOps?
Yes, you can schedule pipelines to run at specific times or intervals using Azure DevOps’ built-in scheduler.
3. How do you define triggers in Azure Pipelines YAML?
You define triggers in the YAML file using the trigger or pr keyword, specifying the branch or event to initiate the pipeline.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




