




Nowadays, the question of whether to host business data in the Cloud has become easier and easier, which has a lot to do with Microsoft’s investment in Microsoft Azure. Your infrastructure strategy, such as Microsoft Azure SQL Database, which can handle large amounts of data (up to petabytes), can work no matter what the result is.
This blog will let you carry out Azure SQL Replication easily. It will explain 3 methods using which you can Replicate your Azure data. Read along to learn more about these methods and decide which one suits for your azure SQL data replication the most!
Table of Contents
What is Azure SQL?

Azure SQL is a Relational Database that is provided as a completely managed service by Microsoft. Built on top of SQL Server, Azure SQL boasts of a very well-equipped querying layer and rock-solid stability.
The managed instance relieves customers of the effort involved in maintaining an on-premise server. Since SQL Server has traditionally been sold in a license-based model, Azure SQL also needs customers to pay for a subscription license making it slightly more expensive than open-source counterparts like MariaDB and PostgreSQL. Pricing of Azure SQL is in terms of required processor core and memory. It starts at approximately .5 $ per hour for a 2 core and 10 GB instance.
Some of the key features of Azure SQL Database are:
- Updates, provisioning, and backups are all automated in a fully managed Azure SQL Database, allowing you to focus on application development.
- Serverless computing and Hyperscale storage are flexible and agile, adapting quickly to your evolving needs. Azure SQL Database Hyperscale can scale storage up to 100 TB.
- Your data is safe thanks to many layers of protection, built-in controls, and sophisticated threat detection. With Azure SQL Database ledger, you can provide tamper-evident cryptographic verification for your centralized data repositories from within your database. There is no need to migrate data or make modifications to the application.
- With SLA of up to 99.995%, built-in AI and high availability maintain optimal performance and durability.
Why is Azure SQL Replication needed?
The need for an Azure SQl replica is explained in detail in this article,
Migration to the Cloud is a wise choice because of its possibilities and the advantage it gives customers regardless of their company demands, locations, or scalability. It’s no surprise that Cloud adoption is accelerating, and Microsoft Azure continues to climb the popularity ladder, as we continue to work remotely.
Since SQL Server is a favorite on-premise database among enterprises, Azure SQL server finds itself as a top choice while these companies move to a pure-cloud or hybrid model. In most such cases, there will be a need to perform Azure SQL Replication. The simplest of such a use case involves just a source and target Database, but it is typical to find replication configuration involving 3 or 4 Databases in enterprises. This is mostly used while trying to separate the transactional Databases from the ones that take ETL workloads.
Azure SQL db replication supports various replication options designed to address specific reasons.
Some of the significant reasons why Azure SQL Replication is needed are listed below:
- To synchronize distributed applications, workloads, and globally distributed data.
- To ensure disaster recovery and business continuity.
- To scale out read-only workloads.
- To keep data synchronized when migrating.
To learn why you need to perform Data Replication, refer to Data Replication: Key Advantages & Disadvantages. Read along the next section, to understand the methods that can be used to set up Azure SQL Replication.
Types of Replication
| Replication Type | Azure SQL Database | Azure SQL Managed Instance |
| Standard Transactional | Yes (only as a subscriber) | Yes |
| Snapshot | Yes (only as a subscriber) | Yes |
| Merge Replication | No | No |
| Peer-to-peer | No | No |
| Bidirectional | No | Yes |
| Updatable Subscriptions | No | No |
Replication Architecture
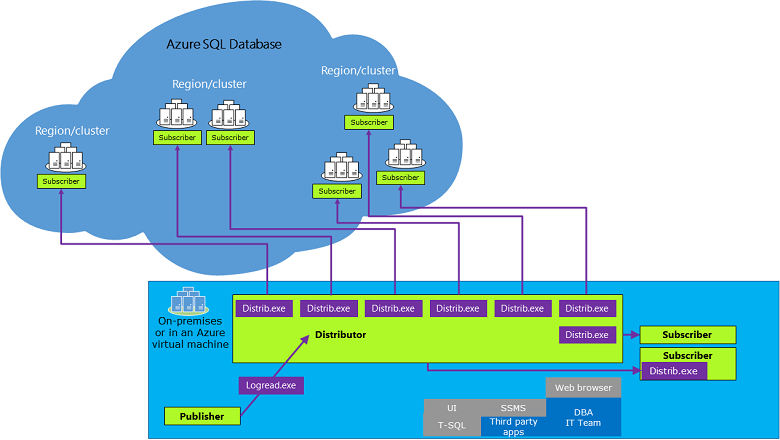
Procedures
Common Replication Procedure:
- Initiate a transactional replication publication within a SQL Server database.
- You can create a push subscription to Azure SQL Database with the help of the New subscription wizard or Transact-SQL statements on SQL Server.
- The initial dataset is a snapshot generated by the Snapshot Agent and subsequently distributed and applied by the Distribution Agent in case of single and pooled databases within Azure SQL Database. You can use a database backup for SQL Managed Instance publishers to seed the Azure SQL Database subscriber.
Data Migration Procedure:
- Implement transactional replication for replicating data from an SQL Server database to an Azure SQL Database.
- Redirect client or middle-tier applications to interact with the replicated database copy.
- Cease updates on the SQL Server version of the table and proceed to eliminate the associated publication.
Method 1: Using Azure Data Sync for Azure SQL Replication
Azure SQL Data Sync allows one-way or two-way data synchronization between multiple Azure Databases and SQL Server instances. This requires a central Database, a member Database, and a metadata Database located in the same region as the central Database.
Method 2: Using Transaction Replication Feature for Azure SQL Replication
The Azure Transactional Replication feature requires creating a source Database, connecting it to a distributor, and initiating the replication process, which the user must custom-code.
Method 3: Using Hevo Data for Azure SQL Replication
Hevo Data provides an automated, no-code solution for Azure SQL Replication. It not only replicates data from Azure SQL effortlessly but also enriches and transforms it into an analysis-ready form without any coding required.
Get Started with Hevo for FreeMethods to Set Up Azure SQL Replication
Method 1: Using Azure Data Sync for Azure SQL Replication
In this method, we will discuss in detail Azure SQL server replication using Azure Data Sync.
Azure SQL Data Sync is a service that helps in syncing data unidirectionally or bidirectionally between multiple Azure Databases and SQL server instances. It involves a hub Database and member Databases. A metadata Database in the same region as that of the hub Database is also needed. You will now start configuring Data Sync through the Azure portal.
- Step 1: Log in to the Azure portal and select SQL Databases.
- Step 2: Select the Database you will be using as the master or the hub Database.
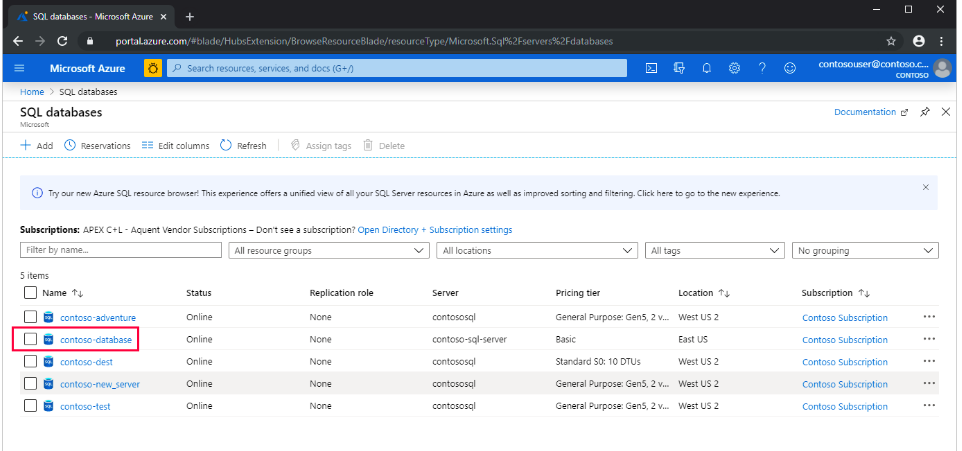
- Step 3: From the left-hand side menu, select Sync to other Databases.
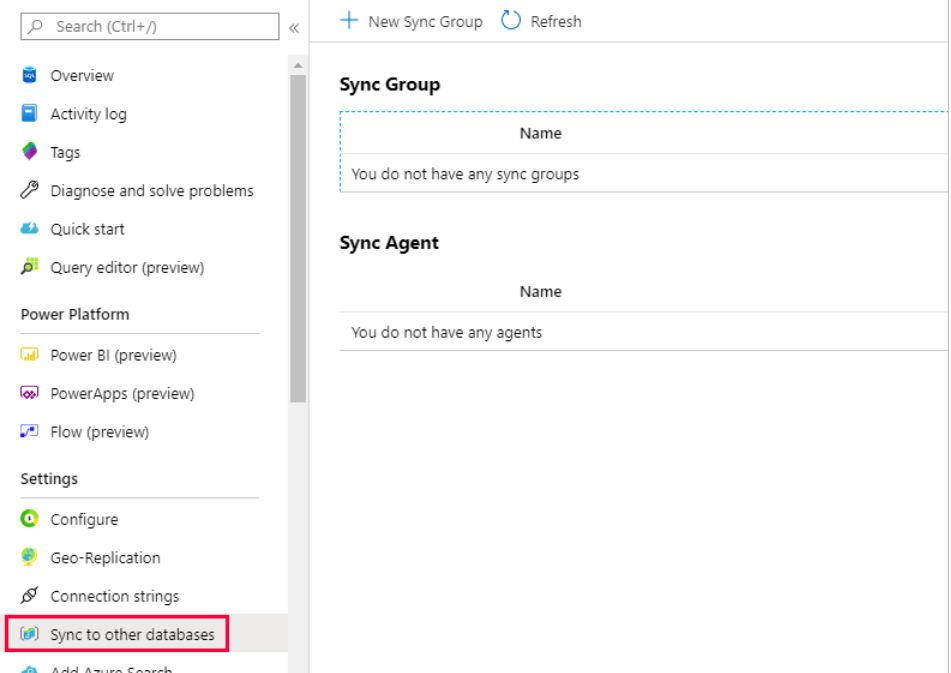
- Step 4: Select ‘New Sync group’ and add the details. Select automatic sync as ON for scheduling sync and enter your preferred schedule. In case of conflict resolution, select ‘Hub win’.
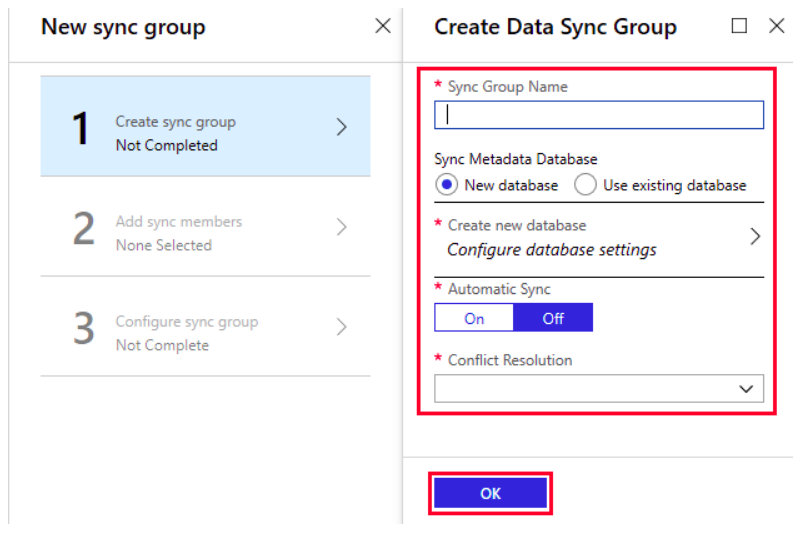
- Step 5: In the next section, add the configuration details for the member Databases.
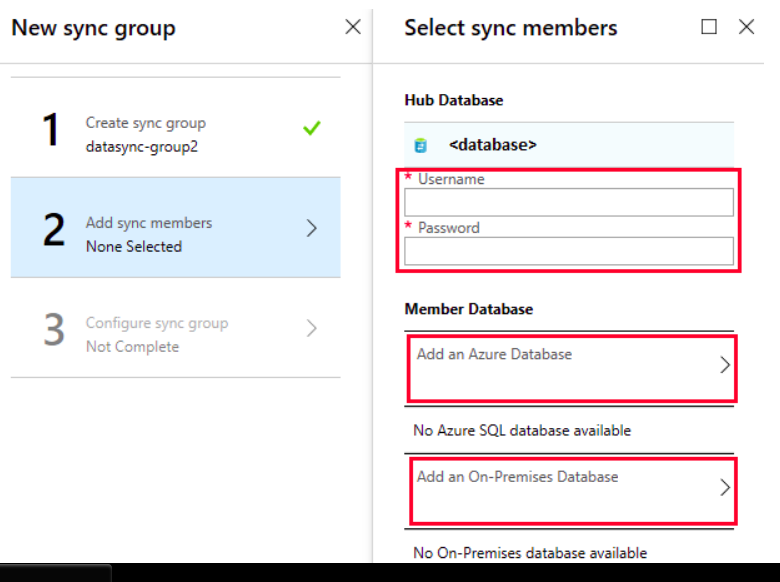
If you do not already have a destination Database, you can create one from this interface itself. Otherwise, add the details of your destination Database. It can take a managed instance or an SQL Server instance.
- Step 6: In the next screen, select the tables that you want to sync from the source database and click ‘Save’. If you have configured a schedule in the second step, your sync will be executed at that time. Otherwise, you can start the Sync manually by clicking the Sync button.
Drawbacks of Using Azure Data Sync for Azure SQL Database Replication Step By Step
Azure Data Sync is an intuitive service that can schedule sync between SQL Server or managed SQL instances in a few clicks. But it comes with the following drawbacks that make it non-ideal in certain situations:
- The sync interval can only be set to 5 minutes at a minimum. So you should expect more than 5 minutes of latency in syncing your data.
- It is very performance-intensive and comes with a restriction on the number of member Databases.
- Transactional consistency is not maintained. So there will be intervals of time where your destination is not up to date or reflect a diverged state concerning your source Database. This makes it a less than perfect solution for backups as well.
Method 2: Using Transaction Replication Feature for Azure SQL Replication
Azure Transactional Replication feature eliminates most of the drawbacks mentioned in the case of Data Sync. It is a bit more involved to set up and makes you use the command line. For the sake of simplicity, let us assume, there is a table called ReplicationTest with two columns – ID and name. You will start the process by first setting up a destination Database in your managed instance.
- Step 1: Connect to your instance and execute the below T-SQL to create a destination Database.
USE [master]
GO
CREATE DATABASE [ReplTran_SUB]
GO
USE [ReplTran_SUB]
GO
CREATE TABLE ReplicationTest (
ID INT NOT NULL PRIMARY KEY,
NAME VARCHAR(100) NOT NULL,
dt1 DATETIME NOT NULL DEFAULT getdate()
)
GO- Step 2: Connect to the Source Database and execute the below statements to configure a distributor. This process takes the transactions from the source and feeds them to the destination Databases.
USE [master]
GO
EXEC sp_adddistributor @distributor = @@ServerName;
EXEC sp_adddistributiondb @database = N'distribution';
GO - Step 3: We will now configure the source Database to use the distributor. For this, you need to change the query mode to the SQLCMD mode. You can do this by going to the query menu and clicking the SQL CMD mode. Execute the following commands to configure the source Database.
:setvar username <your_user_name>
:setvar password <your_passsword>
:setvar file_storage "<file_share_folder_name>"
:setvar file_storage_key "DefaultEndpointsProtocol=https;AccountName=<Accountname>;AccountKey=<Account_key>;EndpointSuffix=core.windows.net"
USE [master]
EXEC sp_adddistpublisher
@publisher = @@ServerName,
@distribution_db = N'distribution',
@security_mode = 0,
@login = N'$(username)',
@password = N'$(password)',
@working_directory = N'$(file_storage)',
@storage_connection_string = N'$(file_storage_key)'; - Step 4: Use the below command to enable replication and configure logs in the source Database.
USE [<source_db_name>]
EXEC sp_replicationdboption
@dbname = N'<source_db_name>',
@optname = N'publish',
@value = N'true';
-- Create your publication
EXEC sp_addpublication
@publication = N'publish_test',
@status = N'active';
-- Configure your log reader agent
EXEC sp_changelogreader_agent
@publisher_security_mode = 0,
@publisher_login = N'<your_user_name>',
@publisher_password = N'<your_password>',
@job_login = N'<your_username>',
@job_password = N'<your_password>';
-- Add the publication snapshot
EXEC sp_addpublication_snapshot
@publication = N'publish_data',
@frequency_type = 1,
@publisher_security_mode = 0,
@publisher_login = N'<your_username>',
@publisher_password = N'<your_password>',
@job_login = N'<your_username>',
@job_password = N'<your_password>';- Step 5: Configure the Replication Database to use the publisher and initialize the snapshot.
-- Adds the ReplTest table to the source table publication
EXEC sp_addarticle
@publication = N'publish_data',
@type = N'logbased',
@article = N'ReplicationTest',
@source_object = N'ReplicationTest',
@source_owner = N'<your_schema>';
-- COnfigures and adds the subscriber
EXEC sp_addsubscription
@publication = N'publish_data',
@subscriber = N'<destination_server_url>',
@destination_db = N'<destination_database_name>',
@subscription_type = N'Push';
-- Configures an agent for data push and subscription.
EXEC sp_addpushsubscription_agent
@publication = N'publish_data'',
@subscriber = N'estination_server_url',
@subscriber_db = N'destination_database_name',
@subscriber_security_mode = 0,
@subscriber_login = N'<destination_username>',
@subscriber_password = N'<destination_password>',
@job_login = N'<your_username>',
@job_password = N’<your_password>';
-- Initializing the publishing snapshot.
EXEC sp_startpublication_snapshot
@publication = N'publish_data';The last command should get the Replication started. You can test this by adding a row to the source database and verifying that the row has been Replicated. In case you face errors, you may need to increase the connection timeout values of your source Database.
When to use Transactional Replication
Transactional replication is beneficial in the following circumstances:
- Sharing updates made on one or multiple tables within a database and distributing them to one or multiple databases within an SQL Server instance or Azure SQL Database subscribed to receive these changes.
- Maintaining synchronization across multiple distributed databases, ensuring a harmonized state of data.
- Ensuring the migration of databases from one Azure SQL Managed Instance or SQL Server instance to another by consistently publishing the ongoing changes.
Drawbacks of Using Transactional Replication
The biggest advantage of this approach is the low latency and transactional consistency. Such capability comes with the following drawbacks:
- The biggest downside is that this is not for the faint-hearted and requires you to meddle with a lot of configurations and commands. This needs database administration skills to set up along with developer skills.
- This approach is best suited in the case of replication to SQL Server-based destination. In many use cases, the replication has to be done to other databases or warehouses.
- There is no option for transforming data in this method. Many ETL workflows need data transformation before moving data.
Method 3: Using Hevo Data for Azure SQL Replication
Hevo Data, a No-code Data Pipeline, helps you replicate data from Azure SQL to Data Warehouses, Business Intelligence Tools, or any other destination of your choice in a completely hassle-free & automated manner. Hevo’s end-to-end Data Management service automates the process of not only loading data from Azure SQL but also transforming and enriching it into an analysis-ready form when it reaches the destination. Hevo’s Data Mapping feature works continuously to replicate your Azure SQL data to the desired Warehouse and builds a single source of truth for your business.
You can automate your Azure SQL Replication with the following steps:
- Whitelist Hevo’s IP Addresses: You need to whitelist the Hevo IP addresses for your region to enable Hevo to connect to your Azure SQL database. You can do this by creating firewall rules in your Microsoft Azure database settings. Access your Azure MS SQL instance and under Resources, select the Database you want to synchronize with Hevo as shown in the below image.

In the right pane, click the Set server firewall tab to open the Firewall settings. Then create a firewall rule by specifying a Rule name. Specify Hevo’s IP addresses in the Start IP and End IP fields as per your region. This is shown in the below image.

- Enable Change Tracking: To enable change tracking, connect your Azure SQL Database in your SQL Client tool, and enter these commands:
ALTER DATABASE [<database>] ;
SET CHANGE_TRACKING = ON;
ALTER TABLE [<schema>].[<table>] ;
ENABLE CHANGE_TRACKING;- Grant Privileges: The Database user specified in the Hevo Pipeline must have global privileges. Assign those and set the configuration according to your needs. Your Azure Replication will start automatically!
To learn more about using Hevo Data for Azure SQL Replication, visit here.

Check out what makes Hevo amazing:
- Secure: Hevo has a fault-tolerant architecture that ensures that the data is handled in a secure, consistent manner with zero data loss.
- Auto Schema Mapping: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data from Azure SQL and replicates it to the destination schema.
- One-place Solution: Hevo Data along with Azure SQL also caters to Azure MySQL, Azure PostgreSQL, and Azure MariaDB replication.
- Transformations: Hevo provides preload transformations through Python code. It also allows you to run transformation code for each event in the Data Pipelines you set up. You need to edit the event object’s properties received in the transform method as a parameter to carry out the transformation. Hevo also offers drag and drop transformations like Date and Control Functions, JSON, and Event Manipulation to name a few. These can be configured and tested before putting them to use for aggregation.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
For a data pipeline tool, we expect to be able to seamlessly integrate our data sources with custom scheduling, logging, and alerts. Hevo provides all these features and allows us to get access to data when we critically need it.
– Chris Lockhart, Data Science Manager, Scratchpay
With continuous real-time data movement, Hevo allows you to replicate your Azure SQL data along with your other data sources and seamlessly load it to the destination of your choice with a no-code, easy-to-set-up interface. Try our 14-day full-feature access free trial!
Learn More:
Conclusion
The blog discussed Azure SQL Replication and provided 3 different methods of achieving it. The first 2 methods, although feasible, have certain drawbacks which were also discussed in the blog. Such solutions will require skilled engineers and regular data updates. Furthermore, you will have to build an in-house solution from scratch if you wish to replicate your data from Azure SQL to a Data Warehouse for analysis.
Hevo Data provides an Automated No-code Data Pipeline that empowers you to overcome the above-mentioned limitations. You can leverage Hevo to seamlessly replicate Azure SQL data in real-time without writing a single line of code. Hevo’s Data Pipeline enriches your data and manages the transfer process in a fully automated and secure manner.
Want to take Hevo for a spin? Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. Check out Hevo pricing to choose the best plan for your organization.
FAQ
What is Azure SQL replication?
Azure SQL replication is the process of duplicating data from one Azure SQL Database to another for high availability, disaster recovery, or distributed database workloads. It supports Active Geo-Replication for business continuity across different regions.
How to replicate a database in Azure?
To replicate a database in Azure, use Active Geo-Replication in the Azure portal. You can enable replication by selecting a database, configuring a secondary region, and setting the database to replicate data automatically.
What are the three types of replication in SQL Server?
The three types of replication in SQL Server are:
1. Transactional Replication
2. Merge Replication
3. Snapshot Replication.
Each serves different use cases for distributing and synchronizing data.



