




Pivot and Unpivot are Relational Operators used to transform one table into another in order to obtain a more simplified view of the data.
Conventionally, the Pivot operator converts the table’s row data into column data. The Unpivot operator does the inverse, transforming column-based data into rows.
Google BigQuery offers operators like Pivot and Unpivot that can be used to BigQuery transpose columns to rows or vice versa.
This article will introduce you to the Pivot and Unpivot operators along with their syntax and example queries. Read along to learn more about transforming BigQuery columns to rows and vice versa!
Table of Contents
What is Google BigQuery?
- Google BigQuery is a robust Cloud-based Data Warehouse and Analytics platform. It is a serverless platform that does not require the installation of any software or maintenance and management of large infrastructure..
Google BigQuery Pivot Overview
Google BigQuery’s PIVOT feature helps transform rows into columns, making it easier to analyze and visualize data in a tabular format. By using the PIVOT operator in SQL queries, you can dynamically aggregate values based on specified columns. For instance, you can pivot sales data by year to display totals for each product category as separate columns. This is particularly useful for summarizing and comparing datasets efficiently. To create a pivot table in BigQuery, use the WITH clause followed by the PIVOT keyword and specify the columns and aggregation function required for your analysis.
How to use the Google BigQuery Pivot Operator?
- At times, you might want to reformat a table result so that each unique value has its own column. This is known as a Pivot Table, and it is normally only a display function supported by BI tools. However, it can be occasionally useful to create the Pivot Table in Google BigQuery. Here’s how to make a pivot table in Google BigQuery using the Pivot Operator:
A) Syntax
FROM from_item[, ...] pivot_operator
pivot_operator:
PIVOT(
aggregate_function_call [as_alias][, ...]
FOR input_column
IN ( pivot_column [as_alias][, ...] )
) [AS alias]
as_alias:
[AS] alias
B) Usage Parameters
The arguments/parameters associated with the Google BigQuery Pivot operator are as follows:
- from_item represents the table or subquery on which you need to perform the Pivot operation.
- alias represents a name used for an item in the query.
Pro Tip: With your Data Warehouse, Google BigQuery live and running, you’ll need to extract data from multiple platforms to carry out your analysis.
C) Rules
Following are the rules for the from_item argument passed to a Pivot operation:
- from_item might constitute any table or result subquery.
- It is possible that it might not generate a value table.
Following the rules for the aggregate_function_call argument:
- You can refer to columns in a table passed to the Pivot operator as well as correlated columns, but you can’t access columns defined by the Pivot Clause.
- If an alias is provided, a table passed to the Pivot operator can be accessed via its alias.
- An Aggregate Function with a single argument can be used only once.
- You can only use Aggregate Functions that ignore NULL inputs, with the exception of the COUNT Function.
Following are the rules for the input_column argument:
- The input column is evaluated against each row in the input table.
- If an alias is provided, the input table can be accessed via its alias.
Following are the rules for pivot_column:
- A Pivot column must be a constant.
- If a name is required for a named constant or query parameter, use an alias to specify it explicitly.
- There are some cases where different Pivot columns can end up with the same default column names. For example, an input column could have a NULL value as well as the string literal “NULL”. When this happens, multiple Pivot columns with the same name are created. You can use aliases for Pivot column names to avoid this situation.
D) Conceptual Example: Transforming BigQuery Rows to Columns
The Pivot operation in Google BigQuery changes rows into columns by using Aggregation. Let’s understand the working of the Pivot operator with the help of a table containing information about Products and their Sales per Quarter. The following examples reference a table called Produce that looks like this before applying the Pivot operation:
WITH Produce AS (
SELECT 'Win' as product, 51 as sales, 'Q1' as quarter UNION ALL
SELECT 'Win', 23, 'Q2' UNION ALL
SELECT 'Win', 45, 'Q3' UNION ALL
SELECT 'Win', 3, 'Q4' UNION ALL
SELECT 'Linux', 77, 'Q1' UNION ALL
SELECT 'Linux', 0, 'Q2' UNION ALL
SELECT 'Linux', 25, 'Q3' UNION ALL
SELECT 'Linux', 2, 'Q4')
SELECT * FROM Produce
+---------+-------+---------+
| product | sales | quarter |
+---------+-------+---------+
| Win | 51 | Q1 |
| Win | 23 | Q2 |
| Win | 45 | Q3 |
| Win | 3 | Q4 |
| Linux | 77 | Q1 |
| Linux | 0 | Q2 |
| Linux | 25 | Q3 |
| Linux | 2 | Q4 |
+---------+-------+---------+After applying the Pivot operator, you can rotate the Sales and Quarter into Q1, Q2, Q3, and Q4 columns. This will make the table much more readable. The query for the same would look something like this:
SELECT * FROM
(SELECT * FROM Produce)
PIVOT(SUM(sales) FOR quarter IN ('Q1', 'Q2', 'Q3', 'Q4'))
+---------+----+----+----+----+
| product | Q1 | Q2 | Q3 | Q4 |
+---------+----+----+----+----+
| Win | 77 | 0 | 25 | 2 |
| Linux | 51 | 23 | 45 | 3 |
+---------+----+----+----+----+Hevo simplifies data transfers into BigQuery with its no-code, real-time platform.
- Effortlessly move data from 150+ sources to BigQuery.
- Transform data on-the-fly with zero manual intervention.
- Fault tolerant architecture ensures no data is ever lost.
Hevo is the only real-time ELT no-code Data Pipeline platform that cost-effectively automates data pipelines, tailored to your needs.
Get Started with Hevo for FreeHow to Use the Google BigQuery Unpivot Operator?
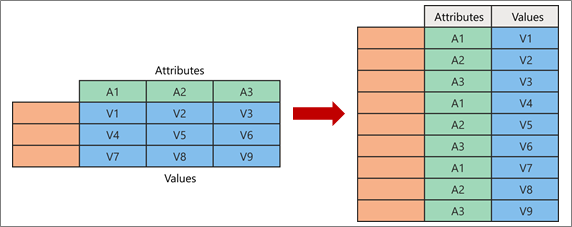
The Unpivot Operator is used to transpose the BigQuery columns to rows. Here is the syntax that you can use to transform BigQuery columns to rows:
A) Syntax
FROM from_item[, ...] unpivot_operator
unpivot_operator:
UNPIVOT [ { INCLUDE NULLS | EXCLUDE NULLS } ] (
{ single_column_unpivot | multi_column_unpivot }
) [unpivot_alias]
single_column_unpivot:
values_column
FOR name_column
IN (columns_to_unpivot)
multi_column_unpivot:
values_column_set
FOR name_column
IN (column_sets_to_unpivot)
values_column_set:
(values_column[, ...])
columns_to_unpivot:
unpivot_column [row_value_alias][, ...]
column_sets_to_unpivot:
(unpivot_column [row_value_alias][, ...])
unpivot_alias and row_value_alias:
[AS] aliasB) Usage Parameters
The arguments/parameters associated with the Google BigQuery Unpivot operator in order to transform BigQuery columns to rows are as follows:
- from_item represents a table or subquery on which you need to apply the Unpivot operation.
- The argument INCLUDE NULLS adds rows with NULL values to the result.
- EXCLUDE NULLS is the opposite of the INCLUDE NULLS argument. It does not add rows with NULL values to the result.
- single_column_unpivot splits a column into two values columns and one name column.
- multi_column_unpivot splits columns into several values columns and one name column.
- unpivot_alias represents an alias for the UNPIVOT operation’s results.
- values_column represents a column containing the row values from columns_to_unpivot.
- Name_column represents a column containing the column names from columns_to_unpivot.
- values_column_set represents a set of columns containing the row values from columns_to_unpivot.
C) Conceptual Example: Transforming BigQuery Columns to Rows
To understand the working of the UNPIVOT operator and transforming BigQuery columns to rows, let us consider the output table you used to understand the Pivot operation.
SELECT * FROM Produce
UNPIVOT(sales FOR quarter IN (Q1, Q2, Q3, Q4))
+---------+-------+---------+
| product | sales | quarter |
+---------+-------+---------+
| Win | 51 | Q1 |
| Win | 23 | Q2 |
| Win | 45 | Q3 |
| Win | 3 | Q4 |
| Linux | 77 | Q1 |
| Linux | 0 | Q2 |
| Linux | 25 | Q3 |
| Linux | 2 | Q4 |
+---------+-------+---------+After applying the UNPIVOT operator, the columns Q1, Q2, Q3, and Q4 are rotated. These columns’ values now populate a new column called Sales, and their names populate a new column called Quarter. This is a single-column unpivot procedure.
Conclusion
- This article introduced you to the steps required to transpose the BigQuery Columns to Rows. It discussed the PIVOT and UNPIVOT operators in great detail.
- However, integrating and analyzing your data from a diverse set of data sources can be challenging. BigQuery transpose and BigQuery pivot operations, such as BigQuery pivot columns to rows, can simplify this process.
- Discover the techniques for BigQuery UNION queries and enhance your data analysis with our comprehensive SQL guide.
FAQ on BigQuery Columns to Rows
How to convert column into row in BigQuery?
In BigQuery, you can convert columns into rows using the UNPIVOT operator.
How do I get data from columns to rows in SQL?
To convert data from columns to rows in SQL, also known as unpivoting, you can use different approaches depending on the SQL dialect you’re working with. You can use UNION ALL for common SQL Databases.
How do you power query from a column to a row?
In Power Query, you can transform data from columns to rows using the “Unpivot Columns” feature.
How do I convert an ARRAY to rows in BigQuery?
To convert an ARRAY to rows in BigQuery, you can use the UNNEST function. The UNNEST function takes an array and returns a table with a single column containing the values of the array, effectively converting the array elements into rows.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



