




Unlock the full potential of your BigQuery data by integrating it seamlessly with Redshift. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
Many organizations use both Google BigQuery and Amazon Redshift for better data analysis BigQuery is known for its serverless data analysis while Amazon Redshift provides seamless data integration. In this blog, we will learn about the steps of integrating data from BigQuery to Redshift.
That said, cloud-based data warehouses like Redshift and Bigquery have become industry-standard in almost every facet of the business intelligence process. Their architecture performs complex analytical queries faster, leveraging innovative data storage, processing, and compiling techniques.
And, when sometimes, there exist workflow challenges that could hamper productivity, the need for diversification also comes into existence. Hence, this tutorial article is for the folks who would want to migrate data from BigQuery to Redshift. Keep reading to know-how.
Use Hevo’s no-code data pipeline platform, which can help you automate, simplify, and enrich your data replication process in a few clicks. You can extract and load data from 150+ Data Sources, including BigQuery, straight into your data warehouse, such as Redshift.
Why Choose Hevo?
- Offers real-time data integration which enables you to track your data in real time.
- Get 24/5 live chat support.
- Eliminate the need for manual mapping with the automapping feature.
Discover why Edapp chose Hevo over Stitch and Fivetran for seamless data integration. Try out the 14-day full access free trial today to experience an entirely automated hassle-free Data Replication!
Get Started with Hevo for FreeTable of Contents
What is Google BigQuery?

Google BigQuery, a giant in the cloud data warehousing industry, helps enterprises of all sizes manage and analyze data seamlessly. BigQuery can be termed as an all-in-one solution for all your business needs — here’s why. Using BigQuery’s built-in features to manage data for machine learning, geospatial analysis, and business intelligence, enterprises can leverage structured information to build upon previous use cases.
Google claims it can query terabytes in seconds and petabytes in minutes. Google BigQuery has three core components: BigQuery Storage, BigQuery Analytics, and BigQuery Administration designed to handle data analysis efficiently.
What is Amazon Redshift?

A cleverly named product, Amazon’s Redshift signifies a shift from the “Big Red,” better known as the Oracle. Redshift is a petabyte-scale data warehouse solution built and designed for data scientists, data analysts, data administrators, and software developers.
Its parallel processing and compression algorithms allow users to perform operations on billions of rows, reducing command execution time significantly. Redshift is perfect for analyzing large quantities of data with today’s business intelligence tools in multiple data warehouses.
BigQuery vs Redshift: Use Case Comparison
Here’s a brief overview of how you can leverage BigQuery and Redshift.
Redshift is best for round-the-clock computational needs — like NASDAQ daily reporting, automated ad-bidding, and live dashboards. Redshift’s users pay for an hourly rate — depending on the instance type and the number of nodes deployed. Check out the pricing information for a more detailed analysis.
BigQuery is best for sporadic workloads — occasionally idle but sometimes running millions of queries. It is best for e-commerce applications, Ad-hoc reporting, and gaining insights into consumer behaviour using Machine learning. BigQuery provides its users with two pricing models: Query-based pricing and Storage pricing. For more detailed analysis check out the pricing information.
How to migrate data from BigQuery to Redshift?
Method 1: Migrate Data From BigQuery to Redshift (Using Hevo Data)
The steps to import data from BigQuery to Redshift using Hevo Data are as follows:
Step 1: Connect your Google BigQuery account to Hevo.

Step 2: Select Amazon Redshift as your destination and begin data transfer.

Hence the data will be transferred successfully to your destination.

Method 2: Migrate Data From BigQuery to Redshift Manually
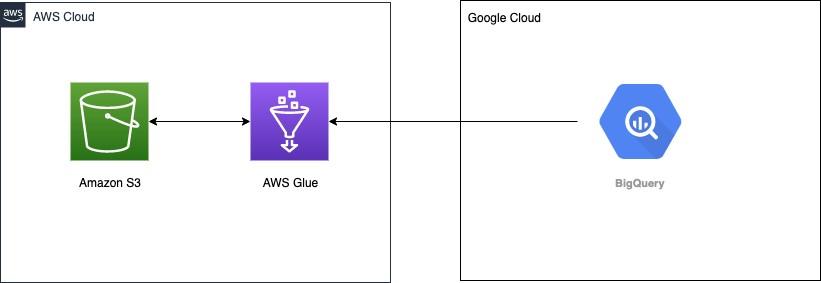
The figure below depicts how AWS Glue links to Google BigQuery for data intake. This section will provide a brief about the approach we will follow to migrate data from BigQuery to Redshift.
Step 1: Configure Google Account
Step 1.1: Download the JSON file containing the service account credentials from Google Cloud.
Step 1.2: Select Store a new secret from the Secrets Manager panel.
Step 1.3: Select Other sorts of secret for Secret type.
Step 1.4: As for credentials, enter your key and the value as a base64-encoded string.
Step 1.5: The remainder of the options should be left alone.
Step 1.6: Select Next.

Step 1.7: Give the secret bigquery credentials a name.
Step 1.8: Complete the remaining steps to save the secret.
Step 2: Adding an IAM role to AWS Glue
The next step is to create an IAM role with the AWS Glue job’s required permissions. Attach the AWS-managed policies listed below to the role:
Create and connect a policy that allows Secrets Manager to read the secret and S3 bucket write access.
As part of this tutorial, the following sample policy displays the AWS Glue task. Always scope down policies before utilizing them in a production setting. Provide your secret ARN for the bigquery credentials secret you established previously, as well as the S3 bucket where you want to save BigQuery data:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GetDescribeSecret",
"Effect": "Allow",
"Action": [
"secretsmanager:GetResourcePolicy",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"secretsmanager:ListSecretVersionIds"
],
"Resource": "arn:aws:secretsmanager::<<account_id>>:secret:<<your_secret_id>>"
},
{
"Sid": "S3Policy",
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:GetBucketAcl",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<<your_s3_bucket>>",
"arn:aws:s3:::<<your_s3_bucket>>/*"
]
}
]
}Step 3: Subscribing to the BigQuery Glue Connector
To subscribe to the connection, take these steps:
Step 3.1: Go to AWS Marketplace and look for the AWS Glue Connector for Google BigQuery.
Step 3.2: Select Continue to Subscribe.

Step 3.3: Examine the terms and conditions, price, and other information.
Step 3.4: Continue to Configuration is the option.
Step 3.5: Select your delivery method under Delivery Method.
Step 3.6: Select your software version under Software Version.
Step 3.7: Select Continue to Launch.

Step 3.8: Select Activate the Glue connector in AWS Glue Studio under Usage instructions.

Step 3.9: Enter a name for your connection in the Name field (for example, bigquery).

Step 3.10: Select a VPC, subnet, and security group if desired.
Step 3.11: Choose bigquery credentials for AWS Secret.
Step 3.12: Select Create connection.
Step 4: Creating the ETL job in AWS Glue Studio
Step 4.1: In Glue Studio, select jobs and set BigQuery as the source
Step 4.2: Select S3 as a target and then create.

Step 4.3: Select and delete ApplyMapping and choose BigQuery as the source.
Step 4.4: Select the Add New option and extend your connection possibilities.

Step 4.5: Add the following Key/Value.
- Key: parentProject, Value: <<google_project_id>>
- Key: table, Value: bigquery-public-data.covid19_open_data.covid19_open_data

Step 4.6: Select the S3 bucket where format and compression types can be selected. S3 target location must be specified.

Step 4.7: Select Bigquery S3 as the job name and choose the IAM role.
Step 4.8: Select Spark as the type and choose Glue 2.0 — Supports Spark 2.4, Scala 2, and Python3.
Step 4.9: Select Save.

Step 4.10: To run the job, choose the Run Job button.

Step 4.11: Once the job run succeeds, check the S3 bucket for data.

We utilize the connection in this task to read data from the Big Query public dataset for COVID-19. More details may be found on GitHub at Apache Spark SQL connector for Google BigQuery (Beta).
Step 5: Querying the Data
You may now crawl the data in an S3 bucket using the Glue Crawlers. It will generate a table called covid. You may now query this data in Athena. The screenshot below depicts the results of our query.

Conclusion
In this article, we waded through two methods of migrating data from BigQuery to Redshift.
- Manual Migration: This includes the manual way of transforming data. This approach requires users to have a sound understanding of Redshift and BigQuery, and their migration customs — leaving the door open for a new user to make mistakes.
- Using Hevo Data: We discussed using Hevo Data. Through Hevo, the BigQuery to Redshift Data Migration process was much faster, fully automated, and required no code. It also provides a pre-built Native REST API Connector that helps in data integration.
Moreover, Hevo lets you directly load data to the destination of your choice. Try a 14-day free trial to explore all features, and check out our unbeatable pricing for the best plan for your needs.
Let us know what you think about the ways discussed to migrate data from BigQuery to Redshift in the comments section below, and if you have anything to add, please do so.
Frequently Asked Questions
1. Which is better BigQuery or Redshift?
In general, however, Redshift is more economical about running regular queries or calls to APIs used for day-to-day marketing reports whereas BigQuery seems better for processing low-frequency workloads that involve more complex schemas and resource-intensive queries made up of multiple joins or aggregates.
2. What is the equivalent of BigQuery in AWS?
Amazon Redshift is the equivalent service of BigQuery in AWS. It is also another cloud-based data warehousing solution that lets you analyze huge data sets using SQL queries.
3. What is BigQuery migration?
BigQuery Migration Service provides in-depth service for moving your data warehouse to BigQuery.
4. Is Amazon Redshift serverless?
Amazon Redshift Serverless has all data warehouse capacity automatically provisioned and intelligently scales the underlying resources. In other words, Amazon Redshift Serverless scales capacity in seconds to deliver consistently high performance and simplified operations for even the most demanding and volatile workloads.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



