
Are you looking to supercharge your data analytics capabilities? This BigQuery tutorial explores how Google BigQuery revolutionizes data processing with its serverless, scalable, and high-performance design. From setting up your first project to mastering its real-time data ingestion and advanced querying capabilities, this guide is packed with actionable insights. Whether you’re a beginner or an experienced data professional, this tutorial will help you discover the full potential of BigQuery for managing and analyzing large-scale datasets seamlessly.
Table of Contents
What is Google BigQuery?

Google BigQuery is the Google Cloud Platform’s enterprise data warehouse for analytics. It performs exceptionally well even while analyzing huge amounts of data and quickly meets your big data processing requirements with offerings such as exabyte-scale storage and petabyte-scale SQL queries. It is a serverless Software as a Service (SaaS) application that supports querying using ANSI SQL and houses machine learning capabilities.
Hevo Data, a no-code data pipeline platform, helps load data from any data source, such as databases, SaaS applications, and cloud storage, to data warehouses, such as BigQuery, simplifying the ETL process. Check out some Key features of Hevo:
- Integrate data from 150+ sources(60+ free sources).
- Simplify data mapping and transformations using features like drag-and-drop.
- Easily migrate different data types like CSV, JSON, etc., with the auto-mapping feature.
Join 2000+ happy customers like Whatfix and Thoughtspot, who’ve streamlined their data operations. See why Hevo is the #1 choice for building modern data stacks.
Get Started with Hevo for FreeKey Features of Google BigQuery
Some of the key features of Google BigQuery are as follows:
1) Scalable Architecture
BigQuery has a scalable architecture and offers a petabyte scalable system that users can scale up and down as per load.
2) Faster Processing
Being a scalable architecture, BigQuery executes petabytes of data within the stipulated time and is more rapid than many conventional systems. BigQuery allows users to run analysis over millions of rows without worrying about scalability.
3) Fully-Managed
BigQuery is a product of the Google Cloud Platform, and thus it offers fully managed and serverless systems.
4) Security
BigQuery has the utmost security level that protects the data at rest and in flight.
5) Real-time Data Ingestion
BigQuery can perform real-time data analysis, thereby making it famous across all the IoT and Transaction platforms.
6) Fault Tolerance
BigQuery offers replication that replicates data across multiple zones or regions. It ensures consistent data availability when the region/zones go down.
7) Pricing Models
The Google BigQuery platform is available in both on-demand and flat-rate subscription models. Although data storage and querying are charged, exporting, loading, and copying data are free. The platform has separated computational resources from storage resources. You are only charged when you run queries, and the quantity of data processed during searches is billed.
Why Use BigQuery?
The primary reason to use BigQuery is for analytical querying. BigQuery enables you to run complex analytical queries on large data sets. Queries are data requests that can include calculation, modification, merging, and other data manipulations. BigQuery is aimed at making analytical queries that go beyond simple CRUD operations and has a high throughput.
Understanding the BigQuery Architecture
Google’s BigQuery service follows a four-layer structure, and this BigQuery tutorial helps you understand BigQuery’s architecture in detail.
- The first layer projects are a top-level container for the data you want to store in the Google Cloud Platform.
- Datasets make up the second layer of Google BigQuery. You can have a single or multiple datasets for a particular project.
- The third layer is known as the tables, which store data in the form of rows and columns. Like datasets, you can have a single or multiple tables in a dataset.
- The final layer of BigQuery is jobs, which involve executing SQL queries to fetch, insert, and modify data.
Also, read Bigquery Array to optimize performance and storage in Bigquery.

You can learn more about the four layers of BigQuery in the following sections:
1) BigQuery Projects
- BigQuery projects function as the top-level container for your data. Each project has a unique name and ID, making storing, accessing, and removing data from BigQuery easy.
- BigQuery projects follow a particular naming convention. Although users can name their projects, they must start with a lowercase character and can only contain digits, hyphens, and ASCII values.
- To create a project in BigQuery, you can use the create command as follows:
gcloud projects create PROJECT_ID2) BigQuery Datasets
- BigQuery datasets act as containers for your tables and views. Each dataset contains multiple tables that store your data.
- You can manage, control, and access data from tables and views with datasets.
- You can also set permissions at the organization, project, and dataset level.
- You can create a dataset in BigQuery using the bq command as follows:
bq mk test_dataset3) BigQuery Tables
BigQuery stores your data in the form of rows and columns in numerous tables. Each BigQuery table follows a particular schema that describes the columns, their name and datatypes.
BigQuery allows users to create three different types of tables:
- Native Tables: These tables make use of the BigQuery storage to store your data.
- External Tables: These tables make use of external storage facilities such as Google Drive, Google Cloud Platform, etc. to store your data.
- Views: These are the virtual tables that a user can define using SQL queries, usually done to control the column level access.
To create a native table in BigQuery, you can use the following command:
bq mk
--table
--expiration 36000
--description "test table"
bigquery_project_id:test_dataset.test_table
sr_no:INT64,name:STRING,DOB:DATE4) BigQuery Jobs
- BigQuery jobs refer to the operations you perform on your data.
- With BigQuery, you can perform four different operations/tasks: load, query, export, and copy the data you’ve stored in the BigQuery.
- When you execute one of these tasks, it automatically creates a job. BigQuery allows users to fetch information about the jobs they’ve created using the
lscommand. - You can use the
lscommand as follows:
ls -j project_idGetting Started with BigQuery
Setting Up a BigQuery Project
To start using BigQuery, follow these steps:
Step 1: Create a Project on the Google Cloud Platform (GCP)
- Log in to your Google Cloud Console.
- Navigate to the Projects section and click on Create Project.
- Provide a Project Name, select a Billing Account, and click Create.

Step 2: Enable the BigQuery API
- In the Google Cloud Console, go to the API & Services section.
- Search for BigQuery API in the library and click Enable.
- This allows your project to interact with BigQuery services.

Creating a Dataset
A dataset in BigQuery is a logical container for tables, views, and routines. To create a dataset:
- Open the BigQuery console at BigQuery UI.
- In the explorer panel, select your project and click the ‘Create dataset’ button.

- Fill in the following details:
- Dataset ID: Provide a unique name for your dataset.
- Data Location: Choose the region where your data will be stored.
- Default Table Expiration: Optionally set a default expiration for tables created in the dataset.
- Encryption: Select a Google-managed key or provide a customer-managed encryption key (CMEK).
- Click ‘Create dataset’ to save your settings.
Understanding the BigQuery Sandbox
The BigQuery Sandbox is a free-tier environment for learning and exploring BigQuery features. Key details include:
Features
- Up to 1 TB of query processing and 10 GB of monthly storage free.
- No need to enable billing or link a credit card.
Limitations
- Storage is limited to 10 GB, and only public datasets are accessible.
- Queries are capped at 1 TB per month.
How to Use
- Go to the BigQuery Sandbox and start querying public datasets, or upload your own within the limits.
Loading Data into BigQuery
BigQuery provides multiple options to ingest data, making it highly flexible:
1. Batch Loading
- Ideal for large datasets stored in formats like CSV, JSON, Avro, or Parquet.
- Use the BigQuery console, bq command-line tool, or REST API to load data.
2. Streaming Inserts
- Enables real-time data ingestion by inserting rows into BigQuery tables via the API.
- Commonly used for analytics on real-time events, such as logs or transactions.



Supported Data Formats
BigQuery supports a wide range of data formats, allowing flexibility in data ingestion:
- CSV (Comma-Separated Values): Commonly used for structured data; requires schema definition.
- JSON (JavaScript Object Notation): Suitable for semi-structured or hierarchical data.
- Avro: Ideal for large-scale data with schema evolution support.
- Parquet: Columnar storage format optimized for analytics and performance.
- ORC (Optimized Row Columnar): Another columnar format for high-performance analytics.
Accessing BigQuery Data
BigQuery allows users to access their data using various SQL commands in a way similar to how they access their data stored in traditional SQL-based databases such as SQL, Oracle, Netezza, etc. It also allows users to access their BigQuery data using various other ways such as using the bq command, BigQuery service APIs, using a visualization tool such as Google Data Studio, Looker, etc.
To access the data using the select statement, you can make use of the following syntax:
select columns_names from table_name where condition group by column_name order by column_name For example, if you want to fetch data from the “bigquery-public-data” table, you can use the select statement as follows:
SELECT title, count(1) as count FROM `bigquery-public-data.wikipedia.pageviews_2019`
WHERE date(datehour ) between '2019-01-01' and '2019-12-31' and lower(title) like '%bigquery%'
group by title
order by count desc;This query will display the number of times the term “bigquery” featured as the title of a Wikipedia page in 2019, and it will generate the following output:

1) Save Query
In BigQuery, you can save queries that you want to use later. The steps are as follows:
- Step 1: Click on the “Save” button. Then, click on “Save Query“.

- Step 2: Give a name to your query and choose its visibility as per your need.
- Step 3: Click on the “Save” button.

Your saved queries are visible in the respective popup tab.
2) Schedule Query
The steps to schedule a query in BigQuery are as follows:
- Step 1: Click on the “Schedule” button. You will be notified that you must first enable the BigQuery Data Transfer API.

- Step 2: Click on the “Enable API” button and wait for a while.

- Step 3: Now, you’ll be able to create scheduled queries when you click on the “Schedule” button.

- Step 4: Click the “Create new scheduled query” option and define the parameters accordingly. Optionally, you can set up advanced and notification options.
- Step 5: Click the “Schedule” button when the setup is complete.

3) Export Query
To export your query results, the steps are as follows:
- Step 1: Click on the “Save Results” button and select one of the available options:
- CSV file
- Download to your device (up to 16K rows)
- Download to Google Drive (up to 1GB)
- JSON file
- Download to your device (up to 16K rows)
- Download to Google Drive (up to 1GB)
- BigQuery table
- Google Sheets (up to 16K rows)
- Copy to clipboard (up to 16K rows)
- CSV file

- Step 2: Suppose, you select the “BigQuery table” option.
- Step 3: Now, you need to set the Project name, Dataset name and table name.
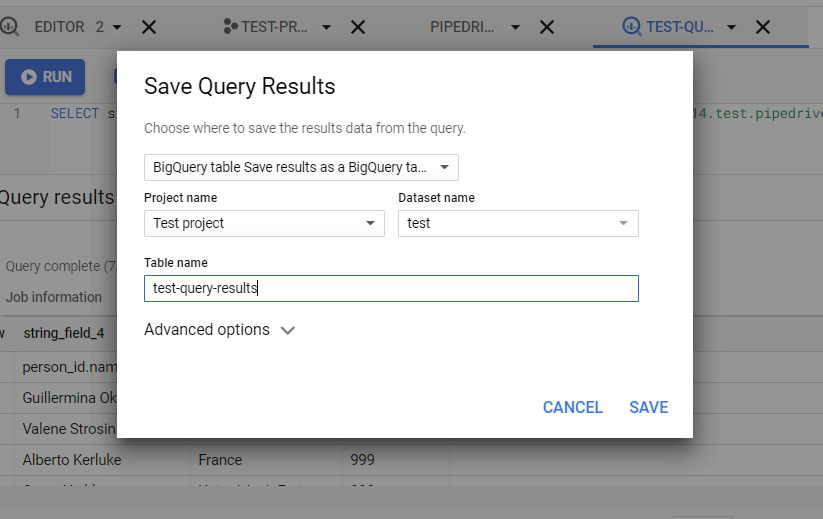
- Step 4: Now, click on the “Save” button.
How Does Google BigQuery Store Data?
Columnar Storage
BigQuery uses columnar storage, storing each column in separate file blocks, making BigQuery an excellent choice for Online Analytical Processing (OLAP) applications. You can easily:
- Stream (append) data to BigQuery tables.
- Update or delete existing values.
- Perform unlimited mutations (INSERT, UPDATE, MERGE, DELETE).
Capacitor Format
BigQuery employs a columnar format known as Capacitor to store data. Each field of a BigQuery table, i.e., each column, is stored in its own Capacitor file. This design allows BigQuery to:
- Achieve extremely high compression ratios.
- Maximize scan throughput.
Colossus: Distributed File System
BigQuery uses Capacitor to store data in Colossus, Google’s next-generation distributed file system and the successor to GFS (Google File System). Colossus handles:
- Cluster-wide replication, recovery, and distributed management.
- Durability through redundant data chunks stored on multiple physical disks with erasure encoding.
- Client-driven replication and encoding.
Sharding and Geo-Replication
When writing data to Colossus, BigQuery determines a sharding strategy that evolves based on query and access patterns. After data is written, BigQuery:
- Initiates geo-replication across multiple data centers to ensure maximum availability.
Separation of Storage and Compute
BigQuery separates storage and computing, enabling:
- Significant cost savings.
- Scaling to petabytes of storage without additional compute resources.
Conclusion
This BigQuery tutorial covered the fundamentals and advanced features of Google BigQuery. With its ability to handle massive datasets, real-time analytics, and integration with various tools, BigQuery simplifies data management for businesses of all sizes. By leveraging its power, you can easily make data-driven decisions.
Consider Hevo Data, a no-code data pipeline platform that seamlessly integrates with BigQuery to further streamline your workflows.
Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
FAQ
1. How do you get started with BigQuery?
To get started with BigQuery, sign in to Google Cloud, create a project, and enable the BigQuery API. You can then use the BigQuery web UI, the command line, or client libraries to run SQL queries and manage data.
2. What are the key features of BigQuery?
BigQuery offers serverless architecture, real-time analytics, automatic scaling, SQL querying, machine learning integration (BigQuery ML), and cost-effective storage with pay-as-you-go pricing.
3. How do you load data into BigQuery?
Data can be loaded into BigQuery via the web UI, command-line tool, or API by uploading files (CSV, JSON, etc.), connecting external data sources (e.g., Google Cloud Storage), or streaming data in real time.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





