




Google BigQuery is a serverless, cost-effective, multi-cloud data warehousing solution that simplifies data access and analysis with optimized performance and availability. It enables users to run SQL-like queries, making it user-friendly for both beginners and experienced users.
Since 2016, Google has supported Standard SQL, introducing new data types like BigQuery Arrays and BigQuery Structs. Arrays are useful for handling multiple values associated with a single record, while BigQuery Structs are ideal for organizing sub-types of information.
Understanding these concepts can enhance your ability to analyze large datasets efficiently. This article will delve into BigQuery Arrays and Structs, exploring key functions like ARRAY_LENGTH(), ARRAY_CONCAT(), and GENERATE_ARRAY, with examples to solidify your knowledge.
Table of Contents
What is Google BigQuery?

- It’s fully managed and entirely Serverless – you focus on nothing but your queries.
- It’s incredibly fast – BigQuery relies on Columnar Storage, so data can be accessed at rapid speeds.
- The UI is incredibly advanced and modernized – everything runs straight from the browser so you don’t need to install any heavy application.

A fully managed No-code Data Pipeline platform like Hevo Data helps you integrate and load data from 150+ different sources (including 60+ free sources) to a Data Warehouse such as Google BigQuery or Destination of your choice in real-time in an effortless manner.
Let’s see some unbeatable features of Hevo Data:
- Fully Managed: Hevo Data is a fully managed service and is straightforward to set up.
- Schema Management: Hevo Data automatically maps the source schema to perform analysis without worrying about the changing schema.
- Real-Time: Hevo Data works on the batch as well as real-time data transfer so that your data is analysis-ready always.
- Live Support: With 24/5 support, Hevo provides customer-centric solutions to the business use case.
Why do Data Analysts and Engineers Love BigQuery?
- It’s fully managed and entirely Serverless – you focus on nothing but your queries.
- It’s incredibly fast – BigQuery relies on Columnar Storage, so data can be accessed at rapid speeds.
- The UI is incredibly advanced and modernized – everything runs straight from the browser so you don’t need to install any heavy application.
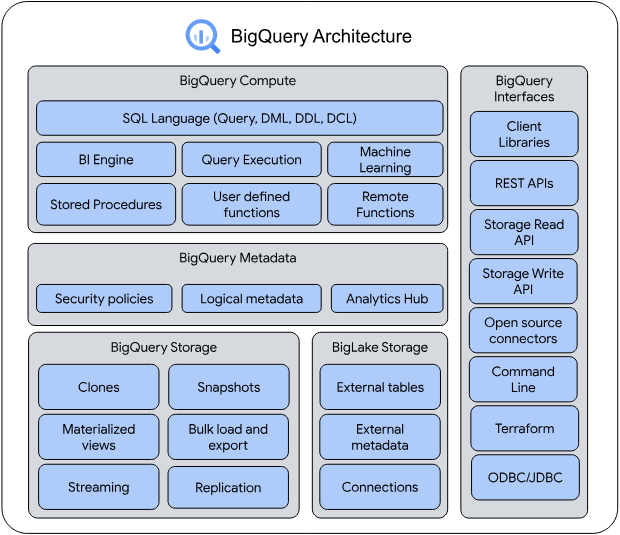
Learn more about the Google BigQuery Architecture, Projects, Datasets, Tables, and Jobs.
What is BigQuery Array?
An array is simply an ordered list in BigQuery. Once you understand how to use them properly, BigQuery Arrays can help you sift through large chunks of data within a matter of seconds. Arrays can be quite helpful in:
- Optimizing Performance and Storage
- Comprehensive String Manipulation
- Transforming data that is not normalized (such as responses from a survey)
A BigQuery Array usually has its own data type within BigQuery. It’s essentially a collection of elements of a similar type of data. To create a BigQuery Array, you can use Literals. Both Literals and Brackets can be used to build an array. Here’s an example:
SELECT [1, 2, 3] as numbers;
SELECT ["apple", "pear", "orange"] as fruit;
SELECT [true, false, true] as booleans;You can also generate arrays with the help of the BigQuery GENERATE function. Literals are great for creating a few arrays, but if you are working with a larger number of elements or rows, you might want to focus on creating Scalable BigQuery Arrays. That’s where the BigQuery GENERATE function comes into play.
GENERATE_DATE_ARRAY(start_date, end_date[, INTERVAL INT64_expr date_part])The GENERATE_DATE_ARRAY function accepts the following Data Types as inputs:
- start_date must be a DATE
- end_date must be a DATE
- INT64_expr must be an INT64
- date_part must be either DAY, WEEK, MONTH, QUARTER, or YEAR.
For example:
SELECT GENERATE_DATE_ARRAY('2016-10-05', '2016-10-05', INTERVAL 8 DAY) AS example;
+--------------+
| example |
+--------------+
| [2016-10-05] |
+--------------+If you run an address_history array, you might get the following response:
Id: “1”
Name: “xyz”
Age: “25”
Address_history: [“current”,”previous”,”birth”]The function simply returns an array with a single element for each row. If a SQL table is produced, it must have precisely one column. However, when using arrays, it’s important to understand the constraints associated with them.
BigQuery Array: Constraints for Consideration
Some of the associated constraints which can be understood prior to using BigQuery Arrays are:
- Each subquery is typically not ordered. As a result, the outputs are unlikely to be ordered. But a clause for “Order by” can be added, which will return the function with the ordered result.
- If more than one column is returned by the subquery, an error will be shown by the BigQuery Array function.
- If the subquery shows zero rows, an empty array will be returned. You won’t get a NULL ARRAY.
By now, we have talked about constructing BigQuery Arrays using Literals and the GENERATE function. You can also access other functions, such as finding the length of an array.
BigQuery ARRAY_LENGTH(): Finding the Length of a BigQuery Array
You can use the ARRAY_LENGTH ( ) function in order to determine the length of an array. Here’s how to do it:
WITH sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS few_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS few_numbers
UNION ALL SELECT [5, 10] AS few_numbers)
SELECT few_numbers,
ARRAY_LENGTH(few_numbers) AS mult
FROM sequences;| Few_numbers | Mult |
| [0, 1, 2, 3, 4, 5] | 6 |
| [2, 4, 8, 16, 32] | 5 |
| [5, 10, 15] | 3 |
BigQuery Array UNNEST: Converting Elements from a Row to a Table
This BigQuery Array function is also quite useful for converting elements in sets of rows into tables. You will have to use the UNNEST operator for this, as it returns a table with each row set up for one specific element.
However, UNNEST does not honour the order of the elements, so you will have to use the WITH OFFSET clause in order to create a sequence for the table. Once done, you can then use the ORDER BY clause to further optimize the table and get all the entries in order. Here’s an example:
SELECT *
FROM UNNEST ([‘alex’,’howard’,’few’,’blip’,’pristine’,’twin’,’cheers’])
AS element
WITH OFFSET AS offset
ORDER BY offset;| Element | Offset |
| alex | 0 |
| howard | 1 |
| few | 2 |
| blip | 3 |
| pristine | 4 |
| twin | 5 |
| cheers | 6 |
Scanning BigQuery Arrays Using UNNEST
In order to determine whether a specific BigQuery Array contains one particular value, you can use the IN Operator along with the UNNEST Operator. With UNNEST, you can use EXISTS to find a value that matches a specific condition.
For instance, if you want to check whether an array contains the number 3, you can run the following command:
SELECT 3 IN UNNEST ([0, 2, 2, 3, 4, 6, 7)] AS contains_value;| contains_value |
| true |
In the results, you can see that it returns “true,” which means it does contain the number 3.
Scanning Specific Values that Satisfy Conditions
If you want to scan for specific values that satisfy a given condition, you must use the UNNEST operator. This will return a full table of elements, and you can then use WHERE to filter the table and then apply EXISTS to check whether the table has the rows that specify the condition or not. Here’s a brief example:
WITH sequences AS
(SELECT [0, 1, 2, 3, 3, 5] AS few_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS few_numbers
UNION ALL SELECT [5, 10] AS few_numbers)
SELECT id AS matching_rows FROM sequences
WHERE EXISTS (SELECT *
FROM UNNEST (few_numbers) AS x
WHERE x > 5| matching_rows |
| 2 |
| 3 |



Understanding BigQuery Structs
A Struct is another important Data Type that you should know when working with BigQuery. It has attributes in Key-value Pairs. Multiple attributes generally have discrete values of their own in each record. However, Structs can also have several attributes; they are all related to one key.
For example, in the table below, the first row is assigned three attributes (“region”, “status”, “zipcode”) for a single address_history Struct.
| Row | address_history.region | address_history.status | address_history.zipcode |
| 1 | Hull | active | 0001 |
| London | previous | 0002 | |
| Dublin | birth | 0003 |
In order to store multiple Structs against specific keys, the best way to do that is to create an Array of Structs. However, in order to select partial Struct keys, you must use the UNNEST function to flatten the contents into several rows. Otherwise, BigQuery will return an error:
Cannot access field status on a value with type ARRAY<STRUCT<status
STRING, address STRING, postcode STRING>>BigQuery ARRAY_CONCAT(): Finding the Length of a BigQuery Array
You can also merge several arrays into a single one with the help of the ARRAY_CONCAT() function. To do this, just use the following:
ARRAY_CONCAT (array_expression_1 [,array_expression_n])For example,
WITH aggregate_example AS
(SELECT [1,2] AS numbers
UNION ALL SELECT [3,4] AS numbers
UNION ALL SELECT [5, 6] AS numbers)
SELECT ARRAY_CONCAT_AGG(numbers) AS count_to_six_agg
FROM aggregate_example;
+--------------------------------------------------+
| count_to_six_agg |
+--------------------------------------------------+
| [1, 2, 3, 4, 5, 6] |
+--------------------------------------------------+You can also convert BigQuery Arrays into Strings, using the ARRAY_TO_STRING() function.
If you would like to learn more about Google BigQuery CONCAT Commands, check out our other insightful guide on Google BigQuery CONCAT Command.
BigQuery ARRAY_TO_STRING(): Converting an Array to a String
You can use the ARRAY_TO_STRING() function to convert a single ARRAY<STRING> to a single STRING value.
Here’s an example:
WITH greeting AS
(SELECT [“Whats”, “up”] AS greeting)
SELECT ARRAY_TO_STRING(greeting, “ “) AS greeting
FROM greeting;| Greeting |
| Whats up |
BigQuery GENERATE_ARRAY
The GENERATE_ARRAY will return an array of values. The parameters must be defined for the start_expression and end_expression.
The following types of data can be input into the array:
- INT64
- BIGNUMERIC
- NUMERIC
- FLOAT64
For example,
The following BigQuery GENERATE_ARRAY generates an array of values in descending order by giving a negative step value:
SELECT GENERATE_ARRAY(21, 14, -1) AS countdown;
+----------------------------------+
| countdown |
+----------------------------------+
| [21, 20, 19, 18, 17, 16, 15, 14] |
+----------------------------------+By now, you should have a pretty fundamental understanding of BigQuery Arrays, BigQuery Structs, some basic functions, and key elements. You should also know the importance of Nested and Repeated fields.
Explore our detailed guide on ARRAY_AGG BigQuery functions to learn how to perform powerful array aggregations in BigQuery.
Conclusion
- There are several important things that you should know by now. For starters, an array is simply a data type that is supported by SQL.
- It works outside of BigQuery as well. Each element within the array is required to have a similar data type, and the order of values is honored.
- BigQuery Structs, on the other hand, can contain several kinds of data. These functions and arrays can be used by Data Analysts and Administrators to gain better control over their data.
- Suppose you are using BigQuery as your Data Warehouse. In that case, you should consider opting for a No-code Data Pipeline, Hevo, that can help you pull your data into a centralized location.
- This will give you better visibility over your data and allow you to gain a better understanding of your company’s performance. You can set up a Hevo trial account to gain a better understanding of the platform and figure out how it works.
Hevo allows you to pull data through multiple Pipelines. It also has more than 150 built-in integrations that you can use in order to pull data from multiple sources. The best part about Hevo is that you aren’t just restricted to using Google BigQuery as your primary Data Warehouse; it works just as well with other Data Warehouses like RedShift and Snowflake too.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. What is an array in BigQuery?
An array in BigQuery is a collection of values grouped together in a single field. It allows you to store multiple values of the same data type in one column, making it easier to manage related data within a single record.
2. What is the difference between array and STRUCT in BigQuery?
The main difference is that an array stores multiple values of the same type (like
numbers or strings), while a STRUCT can hold different types of data in a single field. An array is like a list, while a STRUCT is like a record containing various fields.
3. How do you create an array from rows in BigQuery?
You can create an array from rows in BigQuery using the ARRAY_AGG() function. This function combines values from multiple rows into a single array.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



