




BigQuery datasets are a powerful feature of Google Cloud’s fully managed, serverless, and scalable data warehouse. They allow users to organize and manage large-scale data across different regions, perform lightning-fast SQL queries, and optimize performance. With robust security, resource-sharing capabilities, and support for multi-regional storage, BigQuery datasets enable efficient data analysis for various industries.
In this blog, explore how to create, manage, and optimize BigQuery datasets, highlighting best practices and key considerations for efficient data management in cloud environments.
Table of Contents
What is BigQuery?

BigQuery is an enterprise data warehouse, provided as a SAAS offering by Google, that allows storing and querying huge volumes of data.
Google BigQuery is a Google Cloud Datawarehouse. It can analyze gigabytes of data in a matter of seconds. You already know how to query SQL if you know how to write SQL Queries. In fact, BigQuery contains a wealth of intriguing public data sets that are waiting to be queried. You can use the GCP console or the standard web UI to access BigQuery, or you can use a command-line tool or make calls to the BigQuery Rest API using a choice of Client Libraries such as Java,.Net, or Python.
You can also interact with BigQuery using a range of third-party applications, such as displaying the data or loading the data. It is primarily used to analyze petabytes of data using ANSI SQL at blazing-fast speeds.
Key Features
Why did Google introduce BigQuery, and why would you choose it over a more well-known data warehouse solution?
- Ease of Use: Creating your own is costly, time-consuming, and difficult to scale. BigQuery requires you to load data first and only pay for what you need.
- Speed: Process billions of rows in seconds and analyze streaming data in real time.
- Google BigQuery ML: Google BigQuery comes with a Google BigQuery ML feature that allows users to create, train, and execute Machine Learning models in a Data Warehouse using standard SQL.
- Integrations: Google BigQuery offers easy integrations with other Google products and its partnered apps. Moreover, developers can easily create integration with its API.
- Fault-tolerant Structure: It delivers a fault-tolerant structure to prevent data loss and provide real-time logs for any error in an ETL process.
Are you having trouble migrating your data into BigQuery? With our no-code platform and competitive pricing, Hevo makes the process seamless and cost-effective.
- Easy Integration: Connect and migrate data into BigQuery without any coding.
- Auto-Schema Mapping: Automatically map schemas to ensure smooth data transfer.
- In-Built Transformations: Transform your data on the fly with Hevo’s powerful transformation capabilities.
- 150+ Data Sources: Access data from over 150 sources, including 60+ free sources.
You can see it for yourselves by looking at our 2000+ happy customers, such as Airmeet, Cure.Fit, and Pelago.
Get Started with Hevo for FreeWhat is a BigQuery Dataset?
Just like a database contains your data tables/views/procedures, on the Google Cloud platform, there is the concept of a BigQuery Dataset to hold your tables and views.
Any data that you wish to use, any table or view, must belong to a BigQuery dataset. Data is first loaded into Bigquery from locations like Cloud Storage bucket or other datasets, and then queries are run on it.
How to Create Dataset in BigQuery?
- Expand the Actions option and click Create dataset.
- Open the BigQuery page in the Google Cloud console.
- In the Explorer panel, select the project where you want to create the dataset.
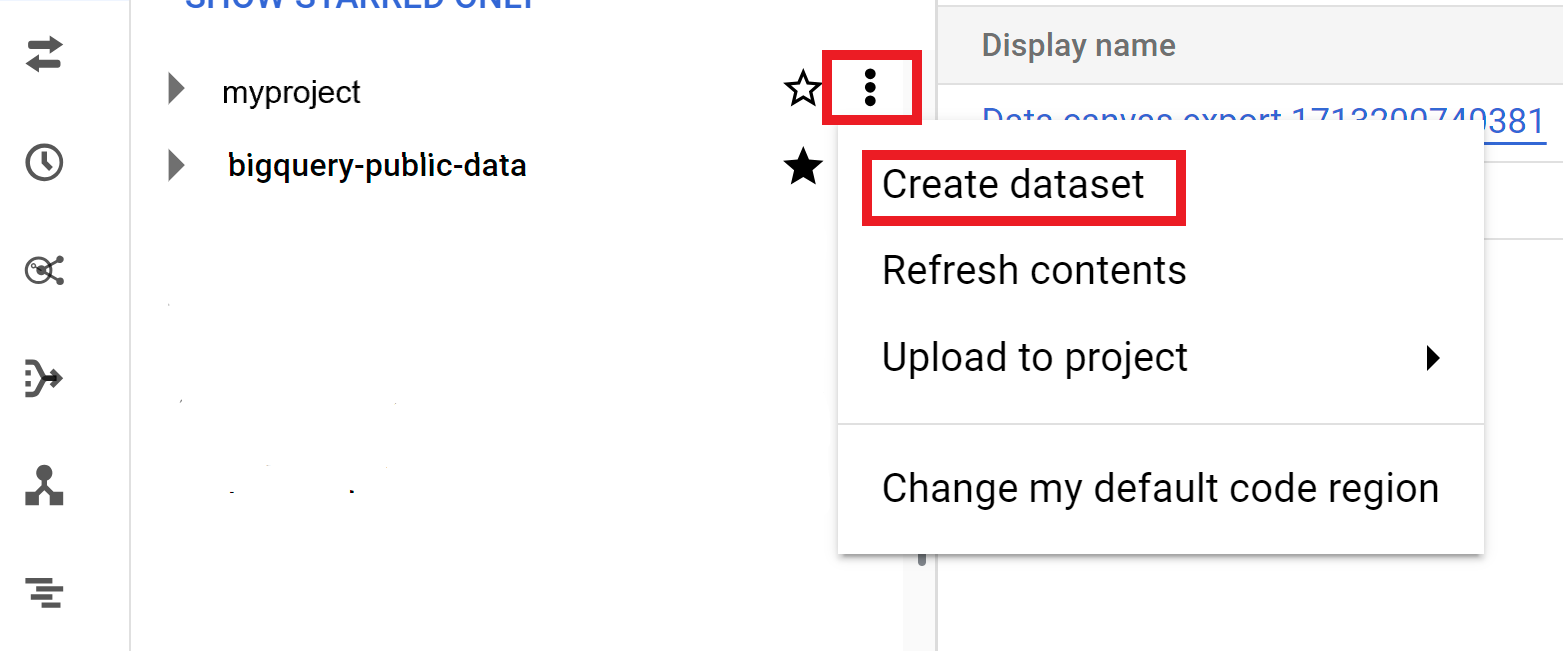
- On the Create dataset page, enter the relevant information and select Create dataset.
Read about creating tables in BigQuery in detail.
Location and billing nuances for BigQuery Datasets
Region and Multi-Region
At the core of BigQuery’s locational concepts are these two visualizations:-
- Region – a region is a specific geographic location, like New York, where the bare metal of the BigQuery infrastructure is placed.
- Multi-Region – a collection of two or more regions. A multi-region may sometimes allow the sharing of resources.
Location Rules for Queries
- The thumb rule to follow is that your Cloud Storage bucket containing the data you wish to load into BigQuery must be in a regional or multi-regional bucket in the same location as your Bigquery dataset.
- A dataset is created in a geographical location and always exists there only; you can only create a copy in another location.
- All queries running in a geographical location will use the datasets stored in its location only. In other words, if your dataset resides in location A, all queries that reference this dataset will run on location A only.
Hence, the location of your BigQuery datasets being read or written must be the same as the location where the query is being run.
Exception: If and only if your dataset is in the US multi-regional location, you can load as well as export data from a Cloud Storage bucket in any regional or multi-regional location.



How to Set Query Location
You can choose the location where you want your query to run by doing one of the following:-
- Using the Cloud Console, click More > Query settings, and for Processing Location, click Auto-select and choose your data’s location.
- Using the QB command-line tool, supply the –location global flag and set the value to your desired location.
- Using the API, go to job-resources, in the job reference section specify your region in the location property.
The above information is useful in minimizing your costs while keeping your queries optimal.
Usage Quotas and Limits in BigQuery Datasets
BigQuery runs on Google Cloud infrastructure and uses bare metal hardware like CPU cycles/RAM, software like OS/Schedulers, etc., and network resources.
There are certain limits and Quotas on how much/many resources your cloud project can use. This is done to ensure fair sharing of resources and reduce spikes in usage, which in turn, can cause your and others’ queries to fail or get stuck.
The good thing is that Google cloud has a fair Quota replenishment policy to ensure smoother operations and avoid long disruptions. Daily quotas are replenished regularly throughout a 24-hour period, intermittent refresh is also done when your quotas get exhausted.
Datasets, Exporting and Copying
| Parameters | Limit |
| Maximum number of tables in the source dataset | 20,000 tables |
| Maximum number of tables that can be copied per run in the same region | 20,000 tables |
| Maximum number of tables that can be copied per run in a different region | 1000 tables |
| Number of authorized views in a dataset’s access control list | 2,500 authorized views |
| Number of dataset update operations per dataset per 10 seconds | 5 operations |
| Maximum row size(based on the internal representation of row data) | 100 MB |
| Maximum columns in a table, query result, or view definition | 10,000 columns |
DML(Data Manipulation Language) statements
Though there can be Unlimited DML(Data Manipulation Language) statements per day, some limits are imposed by statement type/actions. To avoid disruptions and surprises due to quota violations, one should keep the following in mind.
| Parameters | Limit |
| Concurrent mutating DML (UPDATE, DELETE, and MERGE) statements per table | 2 statements |
| Queued mutating DML statements per table | 20 statements |
| Query usage per user/per day | Unlimited |
| Cloud SQL federated query cross-region bytes per day | 1 TB |
| The rate limit for concurrent interactive queries | 100 queries |
| The concurrent rate limit for interactive queries against Cloud Bigtable external data sources | 4 queries |
| Query/script execution-time limit | 6 hours |
| Maximum number of resources referenced per query | 1,000 resources |
| Maximum number of Standard SQL query parameters | 10,000 parameters |
| Maximum number of row access policies per table/per query | 100 policies |
Partitioned tables and BigQuery APIs
If the program uses partitioned tables and BigQuery APIs, some important quotas are mentioned below.
| Parameters | Limit |
| Maximum number of modifications per partition per day ( appends or truncates) | 1,500 operations |
| Maximum number of partitions per partitioned table | 4,000 partitions |
| Maximum number of API requests per second per user | 100 requests |
| Maximum number of concurrent API requests per user | 300 requests |
| Maximum jobs.get requests per second | 1,000 requests |
| Maximum jobs.query response size | 10BM |
| Maximum number of tabledata.list requests per second | 1,000 requests |
| Read data plane/control plane requests per minute per user | 5,000 requests |
| Maximum tables.insert requests per second | 10 requests |
For UDFs (user-defined functions)
| Parameter | Limit |
| The maximum amount of data that your JavaScript UDF can output | 5MB |
| Maximum concurrent legacy SQL queries with Javascript UDFs | 6 queries |
| Maximum number of arguments in a UDF | 256 arguments |
| Maximum number of fields in STRUCT type arguments or output per UDF | 1,024 fields |
| Maximum update rate per UDF per 10 seconds | 5 updates |
Using the above information and a version control system like GIT, you can keep your UDFs optimal and consistent.
Access control permissions in BigQuery Datasets
- A dataset can contain tables, views, or data, and BigQuery allows defining fine-grained policies and permissions for accessing these resources.
- Dataset-level permissions determine which users, groups, and service accounts can access tables, views, and data within a dataset.To control access to a dataset, the user or administrator must have the following permissions:
bigquery.datasets.updateroles/bigquery.dataOwnerbigquery.datasets.get
- Once these permissions are granted, the administrator can selectively grant other users access to the dataset’s resources.
- Example: To allow a user to create, update, or delete tables and views within a dataset, the user must be assigned the
bigquery.dataOwnerIAM role. - Permissions can be managed using coarse-grained Basic roles (Owner/Editor/Viewer) or by creating custom roles that define a set of permissions over specific objects.
- Roles can be applied at the dataset level, jobs and reservations level, table/view level and finally trickling down to row-level access control.
- The above permission can be specified by using the Cloud Console/GRANT and REVOKE DCL statements/bq update command/datasets.patch API method.
Best practices to follow while using BigQuery datasets
- If your source data evolves all the time, it will mostly enable the schema_update_option parameter in your API calls to facilitate the auto schema evolution capability.
- Using this feature, you can augment/merge/coalesce old tables to generate newer ones that better consume your incoming data.
- If you’re using partitioned tables and your data storage is large, store the result of your related subquery in a variable and use this variable to filter the partition column.
- Use the data pre-processing features of Cloud Data Prep and Cloud Dataflow to fine-tune your data before loading it into Bigquery.
- All your data in BigQuery is encrypted, and you can use digital signatures and timestamping to add non-repudiation and trust to your data.
- The Google HMS ( Hardware Security Module) lets you store your unique digital identity and signing certificates in a secure fashion.
- Also, you can use the Google KMS( Key Management) service to load and use your own keys for encryption.
Conclusion
This article gave a comprehensive guide on Google BigQuery Datasets, explaining how to create a dataset keeping in mind the various parameters while utilizing the Datasets. Learn about the various BigQuery ETL tools and select the best one.
While using BigQuery Dataset is insightful, setting up the proper environment can be hectic. To make things easier, Hevo comes into the picture. Hevo Data is a No-code Data Pipeline and has an awesome 150+ pre-built Integrations that you can choose from.
Hevo can help you Integrate your data from numerous sources and load them into a destination like BigQuery to analyze real-time data. It will make your life easier and data migration hassle-free.
SIGN UP for a 14-day free trial and see the difference! Share your experience of learning about the BigQuery Dataset in the comments section below.
FAQs
1. What is BigQuery used for?
BigQuery is a serverless data warehouse designed for fast, SQL-based querying and analysis of large datasets, typically for business intelligence and analytics.
2. Can I use BigQuery as a database?
While BigQuery stores and queries data like a database, it’s optimized for analytics rather than transactional workloads, making it more suitable for data warehousing and big data analysis.
3. What is a dataset in BigQuery?
A dataset in BigQuery is a container that holds tables and views, helping to organize and manage data within a project.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link




