




Data warehouses have transformed how companies store and manage data. By centralizing data into a single repository, overall data accessibility and quality improve a lot. A data warehouse is not a single tool but a combination of various processes and tools involved in organizing data in a structured format in a central location.
Building an efficient data warehouse architecture comes at a cost. So, this article is about estimating the price of building a data warehouse. Before discussing data warehouse costs, let’s first understand whether your company needs one.
Table of Contents
Does Your Business Need a Data Warehouse?
Every business doesn’t always need a data warehouse. A data warehouse is optional if you pull data from a single source or don’t work with data so often. It is unnecessary when your company doesn’t rely on data to make decisions.
Looking for the best ETL tools to connect your data sources? Rest assured, Hevo’s no-code platform helps streamline your ETL process. Try Hevo and equip your team to:
- Integrate data from 150+ sources(60+ free sources).
- Utilize drag-and-drop and custom Python script features to transform your data.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
Try Hevo and discover why 2000+ customers have chosen Hevo over others to upgrade to a modern data stack and optimize their data warehouse costs.
Get Started with Hevo for FreeHowever, the data warehouse helps maintain the quality and integrity of your data. It improves the speed and efficiency of accessing and utilizing data from multiple sources.
The chart below shows the market size of data analytics year by year. It clearly shows that data analytics will continue to grow in the next decade as well.
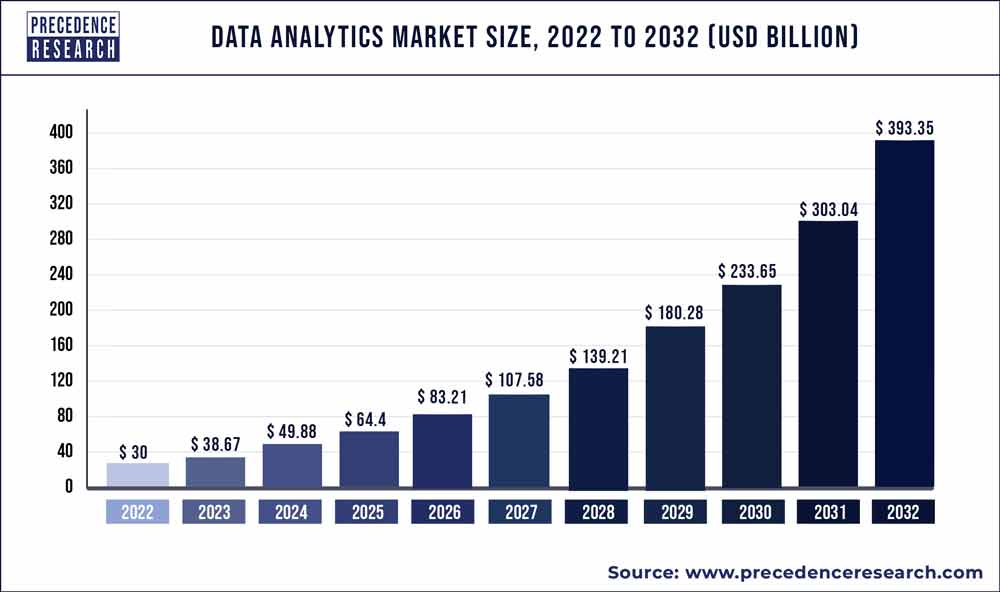
For your organization to leverage data analytics and stay competitive, you’ll need accurate, well-managed, and structured data. A data warehouse ensures these factors in your data. It is a centralized storage repository that stores a huge volume of data and supports running analytics on it.
According to the Maximize Market Research Report, the data warehouse market size is expected to grow at 10.7% CAGR, reaching $64.79 billion within 6 years from now (2024).
With such a promising growth rate, any company prioritizing data should consider this architecture. A data warehouse isn’t just about transforming the way we store data; it also enhances data quality and saves time.
For example, automated ETL tools integrated into data warehouses streamline data transformation, reducing duplicate records, updating outdated information, and maintaining data accuracy.
To sum up, if you use data from multiple sources and rely on data for decision-making, you would benefit from a data warehouse. It helps maintain high-quality data, ensures data security, and makes necessary data available for the long term.
Interestingly, while the industry has focused heavily on cost-efficient AI inferencing and GPU cycle optimization, the same cost awareness hasn’t been fully applied to data transformation in cloud warehouses. We’re seeing a design pattern that wasn’t built with cost efficiency in mind.
Archan Ganguly, CTO @IBM
Key Factors Defining Data Warehouse Cost
Costs will vary based on the company’s data needs, resource demands, tools, and infrastructure. However, this section explores a few deciding factors that determine the data warehouse cost.
Data sources
As the first stage is collecting data from different sources, the type and number of data sources you pull data from play a crucial role in determining the average data warehouse cost.
A data source can be a machine like a computer or an IoT device, a raw data file, or an external API. You may also collect data from your internal CRM or ERP systems, which are again considered data sources.
So, depending on the number of data sources and their types, the average data warehouse cost setup varies.
Data storage
In the data warehouse architecture, the central storage repository is where all your data is stored. This central repository can be either on-premise or a cloud storage system.
The basic on-premise physical server can cost between $1000 to $2500. The initial setup and other hardware are also expensive for on-premise data storage. A report by Cooladata says the on-premise data warehouse with 1 TB storage and 100,000 queries per month costs nearly $500k per year.
The maximum cloud data cost for a popular provider like S3, offering comparable storage and querying capabilities, is only $776 per year.
Data processing
A large amount of data processed in chunks is called batch processing. On the other hand, stream data processing happens instantly, as it flows through the system in real-time.
Compared to streaming data processing, batch data processing is cost-effective as it can be installed on less complex infrastructure. Moreover, real-time processing tasks require high-performance computing resources and continuous monitoring, stretching the budget.
ETL
ETL (Extract, Transform, Load) is the process of collecting data from multiple sources, formatting it, and loading it into the destination. This can be done either manually or through automated tools.
For the manual approach, you’ll need a team of software experts to write code for ETL processes. However, automated ETL software is the most cost-efficient solution. Hevo Data is a popular ETL software that automatically syncs data from multiple sources to the warehouse. The pricing starts at just $239 per month.
Reporting & Analytics
Many companies collect and store data to gain insights that help them make decisions. That’s why data warehouses are often integrated with BI and analytics tools to analyze data and gain valuable insights. However, these tools come with a cost.
For visualization and analytics, both paid and free tools are available. Paid tools like Tableau, Looker, and Microsoft Power BI are simple to use and intuitive.
While open-source tools are free, you’ll need to hire experts to build data visualizations using them.
Resources (Staff)
A team of software engineers, data engineers, and backend developers are required to manage the data warehouse.
The average salary of a Data Engineer is $1,32,021 per year, and backend or software engineers’ pay ranges from $66k to $167k per year, depending on their skills and experience. These costs also come under maintaining your data warehouse.
Learn the essential steps to build a data warehouse and understand how the cost factors come into play in our comprehensive cost estimation guide.
Comparison Of Different Data Warehouses Cost (BigQuery, Redshift, Snowflake, Azure)
As you might have already guessed, BigQuery, Redshift, Snowflake, and Azure are the popular cloud data warehouse platforms. Discussing their individual pricing gives you a perspective on the overall average data warehouse cost.
 |  |  |  | |
| On-demand pricing for computing resource utilization | $6.25 per TiB with access to up to 2,000 concurrent slots | Ranges from $0.25 per hour to $13.04 per hour, depending on the node type | Starts at $1 per hour for X-small warehouse size | $5 per TB of data processed |
| Capacity pricing for computing resources utilization | Multiple editions ranging from $0.04 / to $0.1 / slot hour | $0.36 per RPU hour | $0.10 to $0.30 per credit. (Large warehouses consume more credits than small ones at the same time) | Starts at $1.20 per hour. Price varies depending on the DWUs selected. |
| Storage pricing | $0.02 per GiB per month | $0.024 per GB per month | $0.023 – $0.04 per GB / per month, depending on the region | $0.02 to $0.03 per GB per month |
BigQuery

BigQuery is a fully managed, serverless, and cost-effective data platform from Google Cloud. It offers both computing resources and storage capacity, each with its pricing plan.
The compute pricing model charges for the queries you run on the data, scripts you execute, and any data manipulation you perform. Storage pricing means the cost of storing data in a central location.
Compute pricing is further categorized into on-demand pricing and capacity pricing. In on-demand pricing, you are charged for the queries you run against the data, usually $6.25 per TiB of data processed. On the other hand, capacity pricing is a pay-as-you-go model that measures the computing resources utilized and charges accordingly.
Storage pricing depends on the storage type, whether active or long-term. Active storage means the stored data has been modified in the last 90 days, while long-term storage is the untouched data in the last 90 days. Active storage costs $0.02 per GiB per month, and long-term storage costs $0.01 per GiB per month.
Redshift
Similar to BigQuery, Redshift also offers on-demand pricing that allows you to pay only for what you use. You’ll pay based on the node type you use, the number of nodes, and the hours you use them. For example, Dc2.large is a basic node that costs $0.25 per hour. In on-demand pricing, the clusters scale up whenever needed and can be paused when not in use.
When it comes to storage pricing, Redshift charges for the stored data per GB per month. The typical pricing starts from $0.024 per GB-month. Moreover, if you can commit to Redshift for a long time, choosing the reserved instances pricing model can save you a lot on your budget.
Snowflake
Snowflake also offers compute resources and storage resources pricing models. Here, you’ll be billed based on the credits you use. In the standard edition, each credit costs $2, while $3 per credit is applied in the enterprise edition.
In the compute resources pricing model, the credits are consumed when you load data, perform data manipulation operations, manage metadata, and run queries. Credit consumption also depends on the warehouse configuration you use. For example, the “X-Large” type warehouse size for one hour costs 8 credits while the “Small” warehouse type for one hour costs only 2 credits.
Snowflake storage pricing model is the cost of your data storage. You’ll be charged a flat rate per terabyte each month, depending on your location.
Azure

Azure’s Synapse Analytics is a unified data platform for data warehousing and big data analytics. The data warehouse service provider offers both dedicated and serverless resources.
The serverless pricing model stores the data in a data lake, and the T-SQL queries are performed on it. You’ll be charged based on the number of queries performed and the amount of data processed by each query. The cost is $5 per TB of data processed.
Typically, for 100 data warehouse units (DWU), you will pay $1.20/hour. However, reserved instances pricing can cut down costs significantly. For the same amount of DWUs, the price is down by 37% for 1 year commitment and 65% lower for 3 years commitment.
Average Data Warehouse Cost
Storage, ETL, BI & data analytics, and human resources are the common components of a data warehouse. Let’s estimate the cost of each component and sum up to approximate the overall price.
Data storage: Data storage costs significantly differ depending on whether you choose cloud or on-premise systems. Popular cloud storage service providers like BigQuery, Azure, and Redshift charge an average of $0.02 per GB per month. That costs ~$240 annually for a terabyte of storage.
For on-premise systems, the monthly storage costs will start from $1000 a month, which is $12k annually. Moreover, cloud storage takes less time and is simple to build, while on-premise infrastructure setup is complex.
ETL software: If you go with open-source tools, you do not need to pay the subscription costs, but you might need expert developers to write your own ETL pipelines. That costs more than $200K and takes months or years to develop.
However, an ETL software like Hevo Data is a cost-effective solution. The pricing starts at $239 per month, which is $2.8K annually. The software automates many routine tasks, improving the speed and efficiency of ETL processes.
BI & Data Analytics: According to Capterra, the average price of a BI solution is $3,000 per year. BI tools offer fixed subscription pricing and pay-as-you-use pricing models. Power BI, Looker, Tableau, and Qlik are popular paid BI tools.
Similar to ETL software, there are open-source BI tools as well, but you need to hire human experts to build analytics reports and visualizations.
Human Resources: Though you choose automated tools and cloud storage systems, you will need manual support to maintain them.
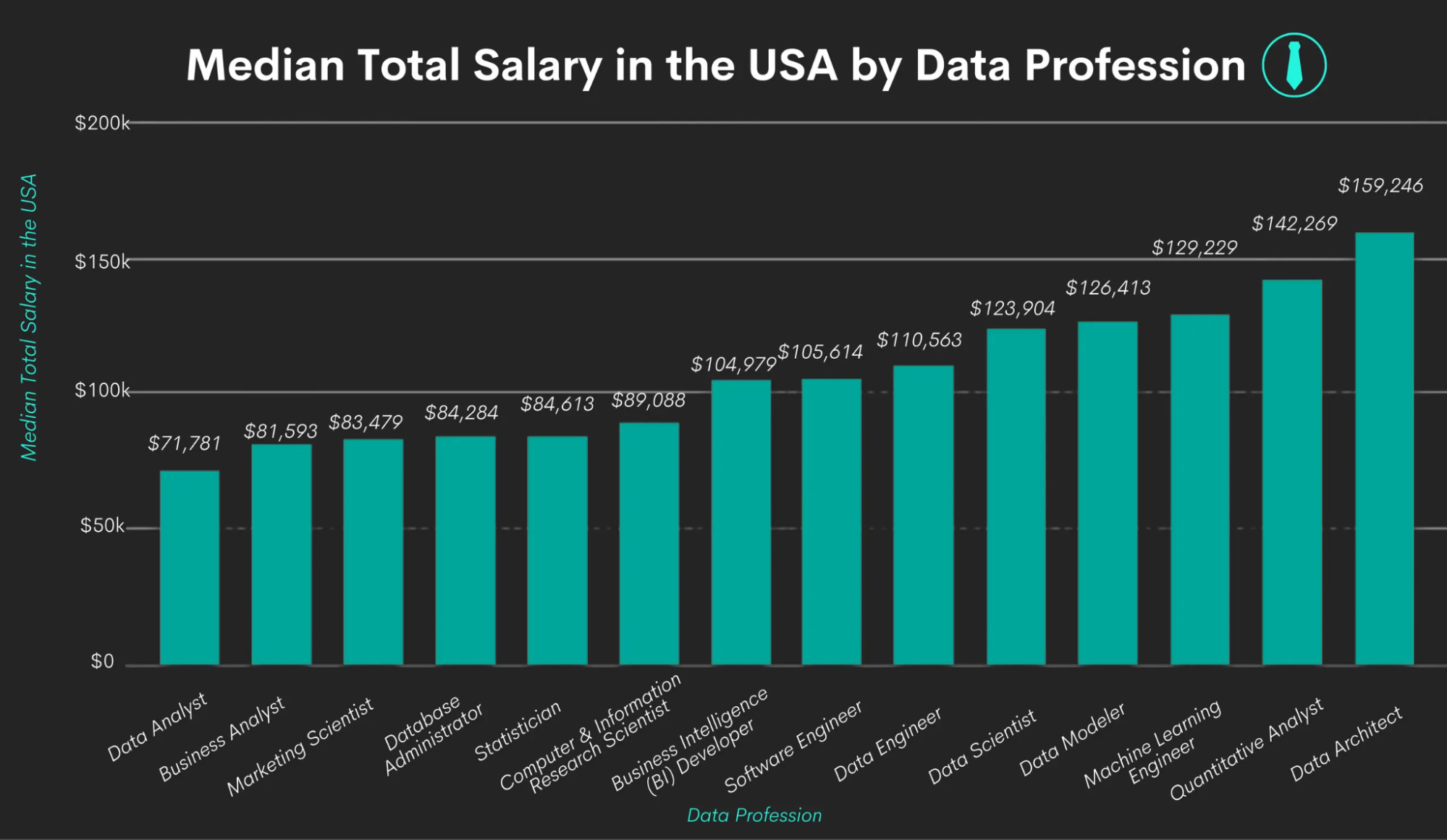
Assuming you run a small business and need one data analyst, one data engineer, and one business intelligence developer. The total estimated cost is ~$285,000 per year.
Summing up these numbers, the total cost of a cloud-based data warehouse is nearly $290K. The on-premise setup data warehouse costs $302K. However, these are approximations, and the exact price varies according to your use case.

Conclusion
No one can predict the exact cost of a data warehouse. The salary range of human resources varies based on their location, experience, and skill level. Different ETL tools also have varying pricing. Storage costs differ depending on whether you choose a cloud data warehouse or on-premise.
So, from the research reports and statistics, this article estimates data warehouse costs. Moreover, the way we calculate pricing and the factors that affect it are mentioned above, allowing you to better estimate data warehouse costs for your own business.
FAQs on Data Warehouse Cost
Is a data lake cheaper than a data warehouse?
Yes, storing data in a data lake is cheaper than a data warehouse. Data lakes can store data of any format in a low-cost storage solution like cloud object storage. In contrast, a data warehouse prioritizes the structure and performance of the data over cost.
What is data storage cost?
Data storage cost is the price you pay to store the data. That is, the storage space your data used. Smaller data size means lower costs, and vice versa.
How much does a data center cost per month?
A data center is a company’s physical facility that hosts IT infrastructure and hardware for storing and managing data and applications. From Intel’s Granulate research, the cost of building a small data center ranges from $200K to $500K. The cost involves setting up physical servers, power backups, coolers, and other hardware equipment.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link




