

Businesses generate huge volumes of data that include transactional data, user data, Marketing, and Sales data, etc. All this data needs to be stored in a common place for analysis and to generate insights from it. Databricks is a Data Warehousing, Machine Learning web-based platform that allows users to store data, run analysis, and get insights using Spark SQL.
APIs are flexible, reliable methods to communicate between applications and transfer data. Companies connect various third-party tools and platforms as a target or a data source to Databricks using the Databricks API. Databricks API integrates with Amazon Web Services, Microsoft Azure, and Google Cloud Platform for data accessibility.
In this article, you will learn about Databricks and REST APIs. You will also understand how you can connect to the Databricks API using the REST API and access data. You can also efficiently access data by utilizing Databricks Autoloader for streamlined ingestion.
Table of Contents
Prerequisites
- An active Databricks account.
- Knowledge of APIs
What is Databricks?

Databricks is a web-based platform and enterprise software developed by the creators of Apache Spark. It is a unified cloud-based data engineering platform focusing on big data collaboration and data analytics that lets users combine data warehouses, data lakes, and data from other sources in one place to create a lakehouse.
Databricks offers a versatile workspace for data engineers, data scientists, business analysts, and data analysts to collaborate using collaborative notebooks and machine learning runtime and manage ML flow. Databricks was founded as an alternative to MapReduce to process big data.
Databricks is built on top of Apache Spark, a fast and generic engine for large-scale data processing. It delivers reliable and high performance. Databricks also supports integration with leading cloud service providers such as Amazon Web Services, Microsoft Azure, and Google Cloud Platform. It comes with delta lakes, an open-format storage layer that assists in handling scalable metadata, unifying streams, and batch data processing. You should also understand the foundation of large-scale data processing with Databricks Architecture.
What is REST API?
REST API stands for Representational State Transfer Application Programming Interface and is a data source’s frontend that allows users to create, retrieve, update, and delete data items.
It is a software architecture style used to guide the development of architecture.
Dr. Roy Fielding described REST API in 2000, giving developers flexibility and an approach to link components and applications in a microservices architecture because of their versatility.
REST API defines how two applications communicate with each other over HTTP. An HTTP request accesses and uses the data with PUT, GET, POST, and DELETE commands. The loosely coupled components make the data flow through HTTP fast and efficient.
Tired of writing long lines of code for replicating your data to Databricks? Unlock the power of your data by effortlessly replicating it using Hevo’s no-code platform. Use Hevo for:
- Hevo provides live data flow monitoring and 24/7 customer support via chat, email, and calls.
- Hevo’s fault-tolerant architecture ensures secure, consistent data handling with zero loss and automatic schema management.
- Hevo supports real-time, incremental data loads, optimizing bandwidth usage for both ends.
Join 2000+ happy customers who’ve streamlined their data operations. See why Hevo is the #1 choice for building a modern data stack for leading companies.
Get Started with Hevo for FreeUse Cases of Integrating Databricks APIs
- Automated Cluster Management: Dynamically create, resize, or terminate clusters to optimize resource utilization and costs based on workload demands.
- Job Scheduling and Monitoring: Automate job submission, execution, and monitoring directly from external systems or scripts for seamless workflow management.
- Data Pipeline Automation: Trigger ETL processes or integrate Databricks with other tools to ensure automated data ingestion, transformation, and loading.
- Custom Dashboard Integration: Pull real-time data or job status from Databricks into third-party dashboards for enhanced monitoring and reporting.
- User and Access Management: Programmatically manage user roles, permissions, and workspaces to streamline admin tasks and enforce security policies.
Methods to Connect to Databricks APIs
Method 1: Invoking Databrick API Using Python
In this method, python and the request library will be used to connect to Databricks API. The steps are listed below:
- Step 1: Authentication Using Databricks Access Token
- Step 2: Storing the Token in .netrc File
- Step 3: Accessing Databricks API Using Python
Step 1: Authentication Using Databricks Access Token
- Log in to your Databricks account.
- Click on the “Settings” button located in the lower-left corner of the screen.
- Then, click on the “User Settings” option.
- Now, switch to the “Access Token” tab.
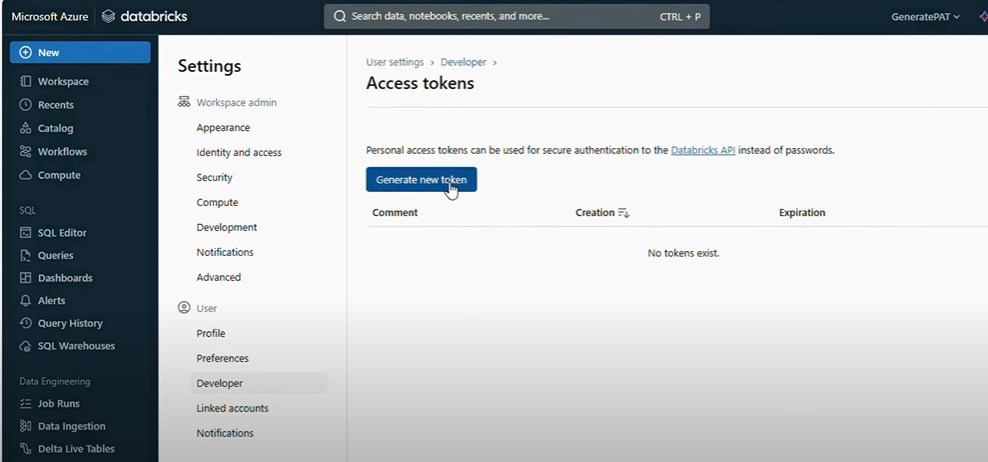
- Here, click on the “Generate New Token” button to generate a new personal access token for Databricks API.
- Now, click on the “Generate” button.
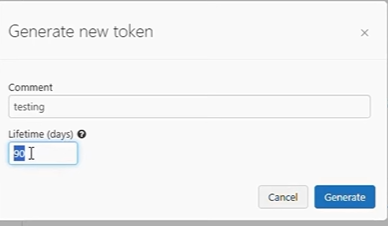
- Copy the access token that you just generated and store it in a safe location.
Step 2: Storing the Token in .netrc File
- Now create a file with .netrc and add machine, log in, and password properties in the file. The syntax for the file is shown below.
machine <databricks-instance>
login token
password <token-value>- Here, the <data-instance> is the Instance ID part of your Workspace URL for Databricks Deployment.
- Let’s say your Workspace URL is https://abc-d1e2345f-a6b2.cloud.databricks.com then the instance ID or <databricks-instance> is abc-d1e2345f-a6b2.cloud.databricks.com.
- The token is the literal string token.
- The <token-value> is the value of the token you copied. For example: api1234567890ab1cde2f3ab456c7d89efa.
- Finally, after creating the .netrc file, the resulting file will look similarly as shown below:
machine abc-d1e2345f-a6b2.cloud.databricks.com
login token
password dapi1234567890ab1cde2f3ab456c7d89efaStep 3: Accessing Databricks API Using Python
- Open any code editor that supports Python.
- For invoking Databricks API using Python, the popular library requests will be used for making HTTP requests. You will go through the process of getting the list of information about specific Databricks clusters.
- Here, the .netrc file will be used to pass the credentials.
- The code for accessing Databricks API using Python is given below:
import requests
import json
instance_id = 'dbc-a1b2345c-d6e7.cloud.databricks.com'
api_version = '/api/2.0'
api_command = '/clusters/get'
url = f"https://{instance_id}{api_version}{api_command}"
params = {
'cluster_id': '1234-567890-batch123'
}
response = requests.get(
url = url,
params = params
)
print(json.dumps(json.loads(response.text), indent = 2))- Here, first, you need to import 2 libraries then provide all the information regarding instance ID, app commands, app versions, URL to call, additional parameters for the cluster, etc.
- After running the code, the finalized result will look like as shown below:
{
"cluster_id": "1234-567890-batch123",
"spark_context_id": 1234567890123456789,
...
}Method 2: Invoking Databrick API Using cURL
In this method, cURL is used to access Databrick APIs. It follows simple cURL command in the terminal window. The steps are listed below:
- Follow Step 1 and Step 2 of Method 1, if you haven’t created the .netrc file yet. Else skip it.
- Open your terminal window and write the commands as given below.
curl --netrc --get
https://abc-d1e2345f-a6b2.cloud.databricks.com/api/2.0/clusters/get
--data cluster_id=1234-567890-patch123- Here, replace the https://abc-d1e2345f-a6b2.cloud.databricks.com with your Workspace URL.
- After completing the command correctly with your credentials, URL, and cluster-ID. The result will look similarly as given below.
{
"cluster_id": "1234-567890-patch123",
"spark_context_id": 123456789012345678,
"cluster_name": "job-239-run-1",
"spark_version": "8.1.x-scala2.12",
...
}Method 3: Connect Databricks APIs Using Hevo Data
Step 1: Configure REST API as a Source
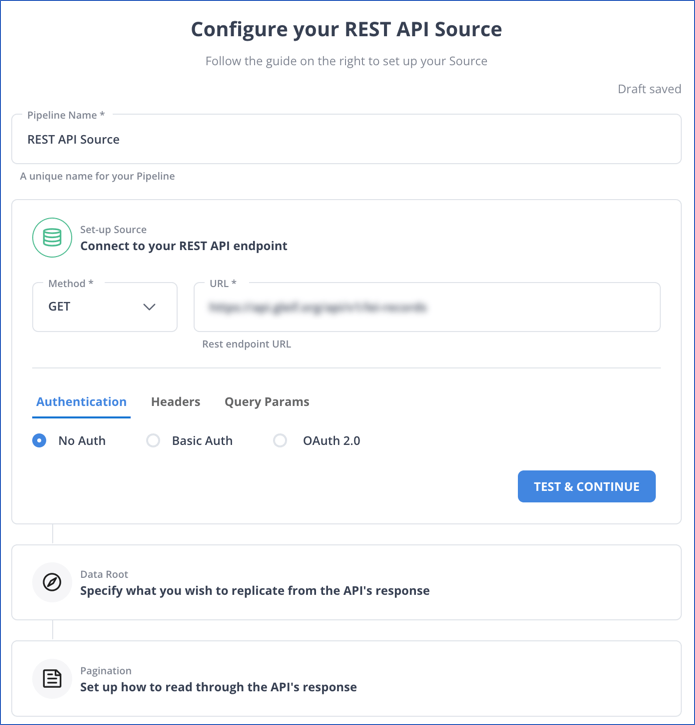
Step 2: Configure Databricks as a Destination


Best Practices for Integrating APIs in Databricks
- Use Secure Authentication: Always use secure methods for authentication, such as OAuth tokens or personal access tokens, and avoid hardcoding sensitive credentials in scripts. Store them securely using tools like Databricks secrets or .netrc files.
- Leverage Pagination and Rate Limiting: When working with APIs that return large datasets, implement pagination to retrieve data efficiently. Also, respect the API’s rate limits to avoid throttling or disruptions.
- Implement Error Handling and Retries: Design robust error-handling mechanisms to catch API failures or unexpected responses. Incorporate retry logic with exponential backoff for transient errors to ensure reliability.
- Optimize API Calls: Minimize the number of API calls by batching requests where possible and caching frequently accessed data to reduce redundancy and improve performance.
- Monitor and Log API Activity: Log all API requests, responses, and errors for troubleshooting and monitoring. Use Databricks’ logging frameworks or external monitoring tools to gain visibility into API integrations.
Discover how to efficiently load data from ActiveCampaign to Databricks and optimize your data processing capabilities. Implement Best Practices by securely managing credentials using Databricks Secrets.
Conclusion
In this article, you learned about Databricks, REST APIs, and different methods to connect to Databricks APIs using Python and cURL. Databricks APIs allow developers to communicate with apps and platforms and integrate Databricks with them. Companies usually integrate visualization tools, reporting tools, and data sources using Databricks APIs. Explore how Databricks Materialized Views enhance query performance and integrate seamlessly using Databricks APIs.
Companies need to analyze their business data stored in multiple data sources. The data needs to be loaded to the Databricks to get a holistic view of the data. Hevo Data is a no-code data pipeline platform that helps to transfer data from 150+ sources to the desired data warehouse.
Want to take Hevo for a spin? Try Hevo’s 14-day free trial and experience the feature-rich Hevo suite first hand.
Share your experience of learning about Databricks APIs in the comments section below!
FAQs
1. What is Databricks API?
Databricks API lets you control Databricks features like clusters, jobs, and data using code, making it easier to automate tasks.
2. What does Databricks do?
Databricks is a platform that helps you process data, build machine learning models, and do data analysis, all in one place.
3. How do I call a Web API from Databricks?
Use code in Databricks (like Python or Scala) to send HTTP requests to the Web API and get data or perform actions.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





