

Batch Processing is a commonly used data integration method to capture data changes in a database. It runs on a schedule to fetch either incremental or a full data extract. However, this method is inefficient when data latency causes significant performance strain on the source systems.
A more modern approach to capturing data changes was then introduced in data engineering: CDC (Change Data Capture). Tools like Debezium help enable CDC on relational databases like Oracle, allowing downstream applications to respond to the changes in real time. In this article, we will discuss how we can leverage Debezium connector for Oracle environment and its benefits and downsides in the data engineering workflow.
Table of Contents
Introduction to Debezium

Debezium is an open-source, distributed platform that helps enable CDC (Change Data Capture) in relational and non-relations databases like Oracle, MySQL, PostgreSQL, MongoDB, Cassandra, etc. It transforms any existing database into an event stream, enabling downstream applications to respond almost instantly to row-level changes in the database.
Debezium is built on top of Kafka and provides connectors for source databases. It records the history of data sources in the Kafka logs and ensures that all events are accurately and completely processed, even after downtime.
Hevo’s no-code data integration platform offers a seamless alternative, making CDC fast, reliable, and easy—without the need for code.
Here’s why Hevo is the smarter choice for CDC:
- No-Code Setup: Skip the complex configurations of Debezium and Kafka Connect. Hevo offers an intuitive, no-code interface that allows you to integrate to Oracle with just a few clicks.
- Automated Data Pipelines: Hevo automates the entire CDC process, ensuring real-time data sync from source into your destination without the hassle of managing Kafka and Debezium infrastructure.
- Real-Time Data Capture: With Hevo, capture every data change in real-time and deliver it to your data warehouse instantly, ensuring that your data is always fresh and ready for analysis.
Why deal with the complexity of Debezium and Kafka Connect when you can achieve the same results with Hevo’s no-code platform? Streamline your CDC processes and focus on what matters—your data.
Get Started with Hevo for FreeHow does Debezium work with Oracle?
Oracle’s database architecture has a critical component, which is responsible for data integrity, known as Redo Logs. Every transaction that modifies data (inserts, updates, and deletes) in the database generates redo records in the redo logs. These records describe what changes were made, including before and after state of the data. These redo log files are a reliable source for tracking data modifications for the Debezium Connector. The connector reads these files, identifies the change, and converts them into event streams for Kafka to process.
Debezium supports two mechanisms for reading change data from Oracle. Let us discuss these mechanisms briefly:
- LogMiner: LogMiner is Oracle’s built-in interface that queries the contents of redo logs. Debezim uses LogMiner to query changed data, extract, process, and produce CDC events for downstream systems. LogMiner is compatible with Oracle Standard Edition. However, this mechanism is less performant and feature-rich than more advanced CDC solutions like Oracle GoldenGate and XStream. So, it is only preferred for low-throughput environments.
- XStream: XStream is a more advanced feature available in Oracle Enterprise Editions and offers higher performance and greater control over the CDC. Unlike LogMiner, which provides a SQL interface to read redo logs, XStream provides native (C and JAVA) APIs to integrate with external systems like Debezium. This mechanism is used for mission-critical and high-throughput systems and when real-time data movement with scalability is necessary.
Setting Up the Debezium Oracle Connector
Prerequisites:
- Oracle Database: A supported version (version 12c or later) of the Oracle Database installation with necessary privileges and configurations.
- Java: Debezium needs a Java runtime to function.
- Apache Kafka: A Kafka cluster for debezium to stream data and Kafka Connect.
- Connector Plugins: Download and include the Debezium Oracle connector plugin in the Kafka Connect setup.
- Driver: Oracle JDBC driver.
Setting up Debezium for CDC on the Oracle database can be tricky sometimes. So, let us dive into a step-by-step process
Step 1: Configuring Oracle
The first step is to configure the Oracle database and make the necessary changes for the Debezium installation.
Enable Database Features needed for the CDC
To enable change data capture, specific features in the Oracle database need to be enabled.
- Enable Supplemental Logging
Supplemental logging needs to be enabled to capture the required metadata for the CDC.
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;- Enable Minimal Supplemental Logging for Primary Key
Suppose the tables in the Oracle database contain a primary key. In that case, minimal supplemental logging for the primary key needs to be enabled to ensure that these keys are captured during changes.
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;- Enable Force Logging
Force logging ensures all the changes are recorded in the redo logs, even those that normally don’t generate redo logs like direct path inserts.
ALTER DATABASE FORCE LOGGING;- Set Oracle to Archive Log Mode
Setting Oracle to the archive log mode ensures that the redo logs are retained.
To check the current log mode, let us run the query below:
SELECT log_mode FROM v$database;If not in ARCHIVELOG mode, let us run the query below to switch to it.
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE OPEN;Step 2: Configure Oracle CDB and PDB Permissions for Debezium
Debezium requires access to certain Oracle views and tables to be able to read the redo logs. Let us create a user and grant it the necessary access and privileges for CDC.
- Create an Oracle DB user for Debezium
Let’s create a dedicated user to be used by the Debezium connector to connect to the database.
CREATE USER debezium_user IDENTIFIED BY 'password';
GRANT CONNECT, RESOURCE TO debezium_user;- Grant Additional privileges
The user we just created needs additional privileges before it can access the redo logs.
GRANT EXECUTE ON DBMS_LOGMNR TO debezium_user;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO debezium_user;
GRANT SELECT ON V_$ARCHIVED_LOG TO debezium_user;
GRANT SELECT ON V_$LOG TO debezium_user;
GRANT SELECT ON V_$LOGFILE TO debezium_user;
GRANT SELECT ON V_$LOG_HISTORY TO debezium_user;
GRANT SELECT ON V_$DATABASE TO debezium_user;
GRANT SELECT ON V_$THREAD TO debezium_user;
GRANT SELECT ON V_$PARAMETER TO debezium_user;
GRANT SELECT ON V_$NLS_PARAMETERS TO debezium_user;GRANT LOGMINING TO debezium_user;
Step 3: Configure Oracle LogMiner
We need to make some database configurational changes for the LogMiner to work efficiently
- Configure Database Parameter
We need to set the value of the database parameter UNDO_RETENTION to allow Debezium enough time to mine the necessary data from the redo logs.
ALTER SYSTEM SET UNDO_RETENTION = 3600;- Increase Redo Log Size
If the database needs to handle large volumes of transactions, we need to increase the size of the redo log files.
ALTER DATABASE ADD LOGFILE SIZE 500M;Step 4: Install and Configure Debezium, Connector
Once Oracle is configured, we can start installing and configuring Debezium for the CDC. We must run Debezium as a Kafka Connect connector and configure it to stream data changes to the Kafka Cluster’s Topic.
- Installing Debezium Connector for Oracle:
Download and install the connector from the Debezium’s Maven Repository.
- Configure Kafka Connect:
Create an Oracle connection definition file for the Oracle connector. We can also specify in the configuration file, which changes in the database should be captured. Below is a sample configuration JSON file saved as register-oracle.json
{
"name": "oracle-connector",
"config": {
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"tasks.max": "1",
"database.hostname": "your-oracle-host",
"database.port": "1521",
"database.user": "debezium_user",
"database.password": "password",
"database.dbname": "your-dbname",
"database.pdb.name": "your-pdb-name",
"database.out.server.name": "your-server-name",
"database.connection.adapter": "logminer",
"database.history.kafka.bootstrap.servers": "your-kafka-bootstrap-server",
"database.history.kafka.topic": "schema-changes.oracle",
"table.include.list": "your-schema.your-table",
"database.tablename.case.insensitive": "false"
}
}- Register the Connector:
We can use Kafka Connect REST API to register the connector.
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" \
localhost:8083/connectors \
-d @register-oracle.json- Verify the deployment:
We can again use the Kafka Connect REST API to get the list of all the connectors deployed by using the BASH command below:
curl -X GET http://localhost:8083/connectorsWe can also check the status of the oracle-connector
curl -X GET http://localhost:8083/connectors/oracle-connector/status- Start the Kafka Connect Worker:
Now that the connector is installed and deployed. We can start the Kafka Connect Worker with the Debezium Oracle connector.
bin/connect-standalone.sh config/connect-standalone.properties config/oracle-connector.jsonStep 5: Validate the CDC Pipeline
Now that the Kafka Connect is configured with the Oracle Connector and the Kafka Connect worker is started. Let us validate if the data is being sent from the Oracle database to the Kafka Topic. We can use the kafkacat or Kafka CLI to check the contents of the Kafka Topic.
kafka-console-consumer.sh --bootstrap-server <your-kafka-bootstrap-server-url> --topic <your-topic-name> --from-beginningStep 6: Monitoring and Troubleshooting
Monitoring and troubleshooting is a very crucial part of any data pipeline including the CDC pipeline. As we are using Kafka as an intermediary element in the pipeline, we can use the Kafka Connect provided REST APIs and metrics that can be used to monitor the status of connectors, tasks, and message throughput.
Common Issues
- Insufficient Access Privileges: We need to ensure that the user created for the Debezium connector has needed access to necessary tables and views.
- Connector Restarts and Failures: This can be a configuration issue. We need to ensure the parameters for the Oracle connector are accurately configured. And check the connector status using the Kafka REST API.
- Oracle Compatibility and Version issues: Oracle connector has compatibility requirements and may not work with all Oracle Versions. We can check for the supported version on the Debezium Release page.
- LogMiner Performance issue: LogMiner is not compatible with very large transactions, potentially causing performance degradation and frequent crashes. We can use XStream for such cases but it is available only for the Oracle Enterprise Edition.
- Schema Change Handling: Sometimes Kafka consumers receive incorrect or malformed messages in its topic this can be due to a schema change in the source. We need to make some additional configurational changes to Debezium to handle the schema changes and schema evolution.
Benefits and Downsides of Debezium
Let us quickly look into the pros and cons of using Debezium for the CDC pipeline on our Oracle Database:
| Pros | Cons |
| Enables data change capture in real-time. | We need to run and manage tools like Kafka, connectors, and monitoring tools. |
| Works with Relational (MySQL, PostgreSQL, Oracle, SQL Server) and Non-Relational (MongoDB) etc. | Strains the source database especially the one with the high volumes of transactions. |
| Uses database logs like Redo Logs, and Archive Logs with no major database change required. | Challenging to configure a distributed database for high availability. |
| Ensure data accuracy by reading the transaction logs. | It is dependent on the log retention and sizing to avoid loss in the data. |
| Open source with a wide community for support. | Some database features like Oracle XStream require additional licensing. |
Setting up Debezium for our Oracle database, managing Kafka clusters and multiple connectors and configuration looks complicated, right?
Let us now explore a simpler way to implement a CDC pipeline for our Oracle database using Hevo Data.
Setting up Oracle Database with Hevo
Following are the steps to follow to set up the Oracle database with Hevo:
Step 1: Create a New Pipeline
- In the Hevo Dashboard, navigate to the Pipeline section.
- Click the Create Pipeline Button to create a new Pipeline.
Step 2: Setup Oracle as a Source
- As soon as you click Create Pipeline, you’re taken to the sources page
- From the list of available data sources, select Oracle
- Fill in the connection details for your Oracle Database.
- Host
- Port
- Service Name or SID
- Username
- Password
- SSL/SSH Mode (Optional)
- Click on the Test Connection button to make sure your Oracle database is reachable from Hevo.
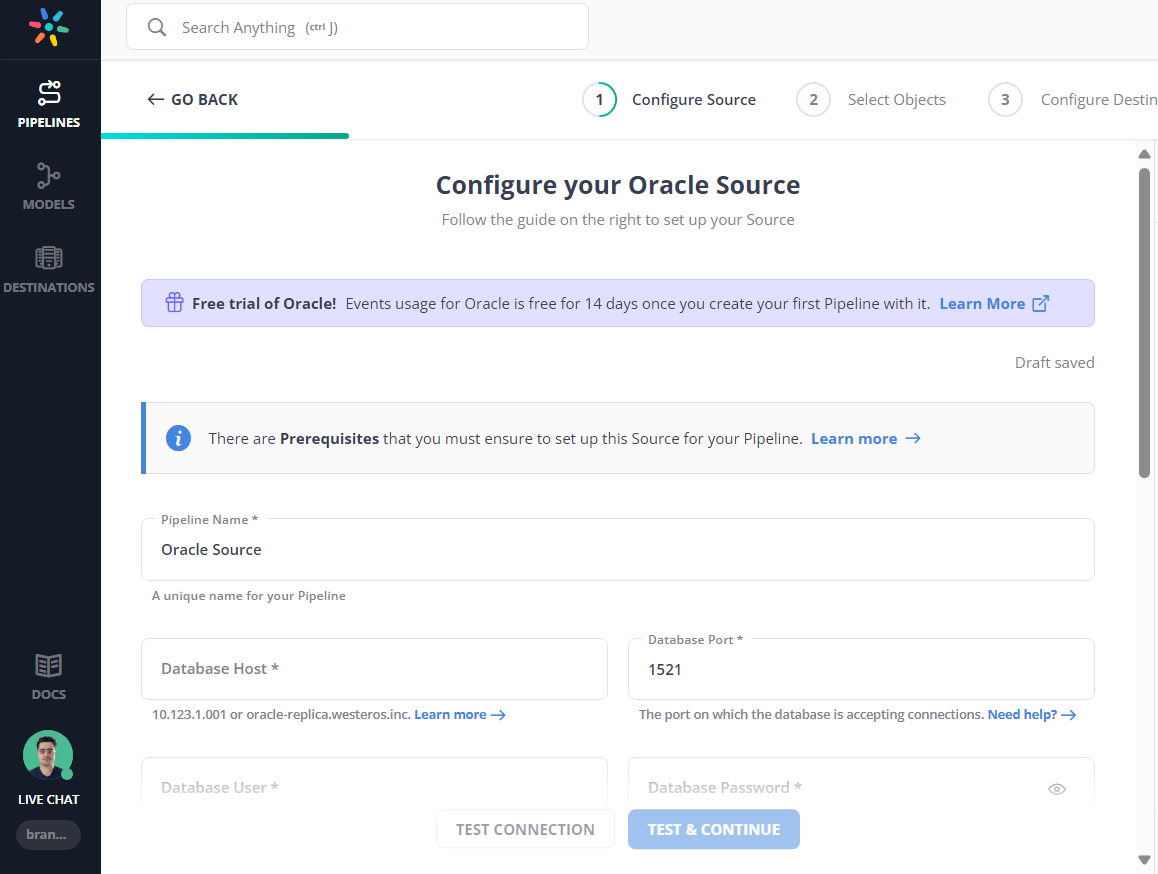
Step 3: Setup Data Replication
- After the successful connection, Hevo fetches the available tables in your Oracle database. Select the ones you need to replicate to the destination.
- Hevo automatically detects the schema of the tables, but we have the liberty to review and make any necessary changes to the schema.
- Choose the Replication Mode
- Full Table: Replicates the entire data of the selected tables.
- Incremental: Replicates the only change since the last sync.
Step 4: Setup Destination
- Set up the destination for your data in the Oracle Database.
- Enter necessary destination details, for example for Snowflake:
- Account: Snowflake account URL
- Warehouse: Name of the warehouse where the data will be loaded
- Database
- Schema
- Username
- Password
- Click on the Test Connection button to ensure Hevo can reach and connect to your destination data store.
And that is it, you can now run the pipeline and validate the data in the destination data store. It also allows us to monitor the status, error logs, and performance metrics of the pipeline in the Monitoring section of the dashboard.
Isn’t it simple enough for any non-technical person to create and run the pipeline?
Conclusion
Debezium is an open-source tool that helps capture data changes in real time. It enables a transactional database into an event-driven architecture by streaming the data changes to Kafka topics to be consumed by downstream systems and applications. However, managing, monitoring, and troubleshooting multiple infrastructures that are needed to run the Debezium for the CDC pipeline is challenging. It gets more complex in large-scale and distributed environments.
For those looking for a simpler and more streamlined solution for building real-time data pipelines, Hevo provides an easier setup with minimal configuration.
You can schedule a personalized demo with Hevo or check out the pricing page to choose a model that suits your business.
Frequently Asked Questions (FAQs)
1. Does Debezium work with Oracle?
Yes, Debezium provides an Oracle connector for the CDC workload on an Oracle Database.
2. What is the difference between Debezium and Kafka Connect?
Kafka Connect is a framework within Kafka Family that supports connection to various data sources and sinks. However, debezium is a set of connectors that is built on top of Kafka to capture data changes in the database.
3. How to connect to the Oracle Database?
We can use the Oracle JDBC driver to connect to the Oracle database programmatically.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





