




A massive amount of data is being generated by eCommerce companies due to the adoption of online shopping. eCommerce companies are using these data to communicate with their customers and boost sales effectively. Drip is one of the most effective revenue engines for eCommerce companies, allowing seamless communication with users on a single platform.
However, handling a colossal amount of data on specific platforms like Drip to Redshift limits companies from harnessing the power of data. As a result, storing such information in a data warehouse like Amazon Redshift is necessary for gaining in-depth insights. Redshift provides a secure and cost-effective place to store data.
Table of Contents
What is Amazon Redshift?

Amazon Redshift is a fast and fully monitored cloud data warehouse service provided by Amazon. It supports efficient analysis through BI tools or machine learning techniques. Amazon Redshift can optimize massive datasets ranging from a few hundred gigabytes to some petabytes. Hence enabling the organizations to evaluate data-driven business options effectively before making a final decision.
Every data warehousing database has a different type of architecture, and Redshift uses the nodal architecture. There are two types of nodes, single-node, and multi-node. A single node in Redshift can have a storage capacity of 160 GB. On the other hand, a multi-node is a combination of more than one node. It is subdivided into the leader and computes node. Leader node manages queries from clients. While the compute node executes these queries and sends them back to the client.
Key Features of Amazon Redshift
Here are some major features of Amazon Redshift:
1) Performance
Redshift has many factors which enhance its performance, one of which is the RA3 instance. Due to these Redshift instances, the performance speed is maximized for workloads dealing with vast data. Redshift also uses Advanced Query Accelerator (AQUA), which enables it to execute ten times faster than other cloud data warehouses. AQUA uses solid-state storage, FPGAs, and AWS Nitros to increase the speed of queries that scan, filter, or aggregate databases. The advanced machine learning algorithms automate the workload and dynamically manage concurrency and memory.
2) Integration
The possibilities of combinations are endless when working with Amazon Redshift. AWS integrations among different services simplify handling tedious analytics workflows. For instance, you can use AWS Glue to extract, transform and load data into Redshift. You can also store data in Redshift from various applications such as Facebook Ads.
3) Security
Redshift caters to one of the most demanding requirements and security for no additional charges. It uses SSL for secure data transit for end-to-end encryption. At the same time, hardware-accelerated AES-256 for data at rest. Additionally, for safe keeping, AWS CloudTrail is integrated with Redshift and allows you to audit all API calls made by Redshift. These logs can be accessed using SQL queries. To invoke these queries, you need to use the AWS Lambda function as a UDF (user-defined function). You can use UDFs to enable data masking, identification, and external tokenization.
Method 1: Connect Drip to Redshift via AWS S3
Export Drip data to Amazon S3, then load it into Redshift for efficient data storage and analysis. Ideal for users familiar with AWS services.
Method 2: Use Hevo for Drip to Redshift Integration
Easily transfer data from Drip to Redshift with Hevo’s no-code platform. Benefit from automated transformations, real-time data sync, and full flexibility in data handling—no complex setups needed.
What is Drip?
Drip is an eCommerce revenue engine that uses email marketing to grow brands. Using Drip, you can achieve excellent results by running multiple channel marketing campaigns without the need for coding. This automated marketing software is not only used for getting email sales, but you can also get critical insights into purchase data. Usually, businesses can use it for personalized marketing and communication with their clients. You can use Drip as CRM for both B2C and B2B marketing. If you are a small to medium-sized company that currently does not have a sales team, then drip eCommerce CRM is a good choice for you.
You can launch marketing campaigns over emails, onsite popups, and other social media platforms using this single software. Drip eCommerce CRM also comes with pre-built playbooks, which can assist you in driving more sales. Playbooks in Drip include abandoned carts, welcome series, win-back series, and so on.
Key Features of Drip
Below are some notable features of Drip:
1) Automation
Drip eCommerce facilitates automation, so you can quickly build a self-running profit-boosting workflow in no time. The pre-built templates like the welcome series and post-purchase are at your fingertips. You have to download Drip, select the appropriate pre-built for you, and make some edits before you deploy it.
2) Personalization
Using the stored data from other integrated applications, Drip smartly tailors personalized content for every customer automatically. The intelligent technology and algorithm help take necessary actions at the perfect time. The dynamic segmentation feature enables you to understand your customers and their wants more profoundly, thereby effectively creating content that caters to their particular needs.
3) Integration
Once you have downloaded Drip eCommerce, you can start integrating various channels and applications to gather more information on your customers. The more data, the better insights you can get. You can connect Drip to eCommerce stores like Shopify, BigCommerce, Magento, or even custom stores. Featured integrations include the Facebook custom audience, lead ads, Gobot, etc.
Method 1: Connecting Drip to Redshift using AWS S3
Two main steps for connecting Drip to Redshift are exporting all the data from Drip to Redshift for storing and analyzing. Follow these steps to connect Drip to Redshift properly:
Step 1: Exporting data from Drip
You can export data from your Drip account in a CSV file, which will automatically be sent to the email address you have entered under your account settings. You can export the people list, account details, and analytics. Under analytics, you will get a CSV file of a report consisting of new people, unsubscribe, clicks, events, and email metrics.
In email metrics, there are two types of download, one for a specific campaign and one for a bulk download. Follow the given steps to download your data from Drip:
1) For specific campaign
- Go to the Analytics section and click on Email Metrics.
- Select Single Email Campaign or workflow email types.
- Select the email address at which you want the data.
- Choose the data range of the required report.
- Click on the Apply button.
- Click the Export to CSV button.
2) For Bulk Download
- Under Settings, go to Analytics and then to Email Metrics.
- Click on the Bulk Download button.
- Select the email series, email campaign, or workflow email type.
- Click on the Start Date button and select the start date on the calendar.
- Click on the End Date button and select the end date on the calendar.
- Download the Report.
You will receive a link to the CSV file at the email address you have used to log in to Drip. However, the CSV file will not have an email address in bulk download. For that, you will need to export the people list CSV.
Step 2: Uploading data to Amazon Redshift
You can load data into Amazon Redshift using the files in Amazon S3 and DynamoDB or from remote hosts through textual outputs. Vast quantities of data can be easily uploaded to Redshift using the COPY query. In this example, we will be using Amazon S3 to load data to Redshift.
1) Loading data to Amazon S3
For Drip to Redshift Connection, Amazon S3 uses buckets as containers to store data such as photos, videos, CSV files, or other documents. Each account has access to 100 buckets by default, although you can increase the number of buckets of your account on request.
Start by creating an Amazon S3 bucket, which should be in the same region as your cluster. Once you have a new bucket, select the Drip files to upload.
2) Uploading data from Amazon S3 to Redshift
Follow the below-given steps to upload your data from Drip to Redshift properly.
- Create a table
Use the CREATE TABLE command in your SQL client to create a new table in Amazon Redshift. Ensure to provide the specifications per the CSV file you downloaded from Drip.
- Run the COPY command
The COPY command can easily copy the data from the Amazon S3 bucket to Redshift. Note that before running this command, you must give access to read the objects in the Amazon S3 bucket.
#Drip to Redshift----
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options]
#Drip to Redshift----You can also use the INSERT command, but it is slow compared to the COPY command since it uses parallel processing. Due to this, the COPY command is a good alternative as you can efficiently and quickly upload data into Redshift.
This concludes Drip to Redshift Connection!

Method 2: Connecting Drip to Redshift using Hevo
- Step 1: Configuring Drip as Source
- Click PIPELINES in the Navigation Bar.
- Click + CREATE PIPELINE in the Pipelines List View.
- In the Select Source Type page, select Drip.
- In the Configure your Drip Source page, specify the following:
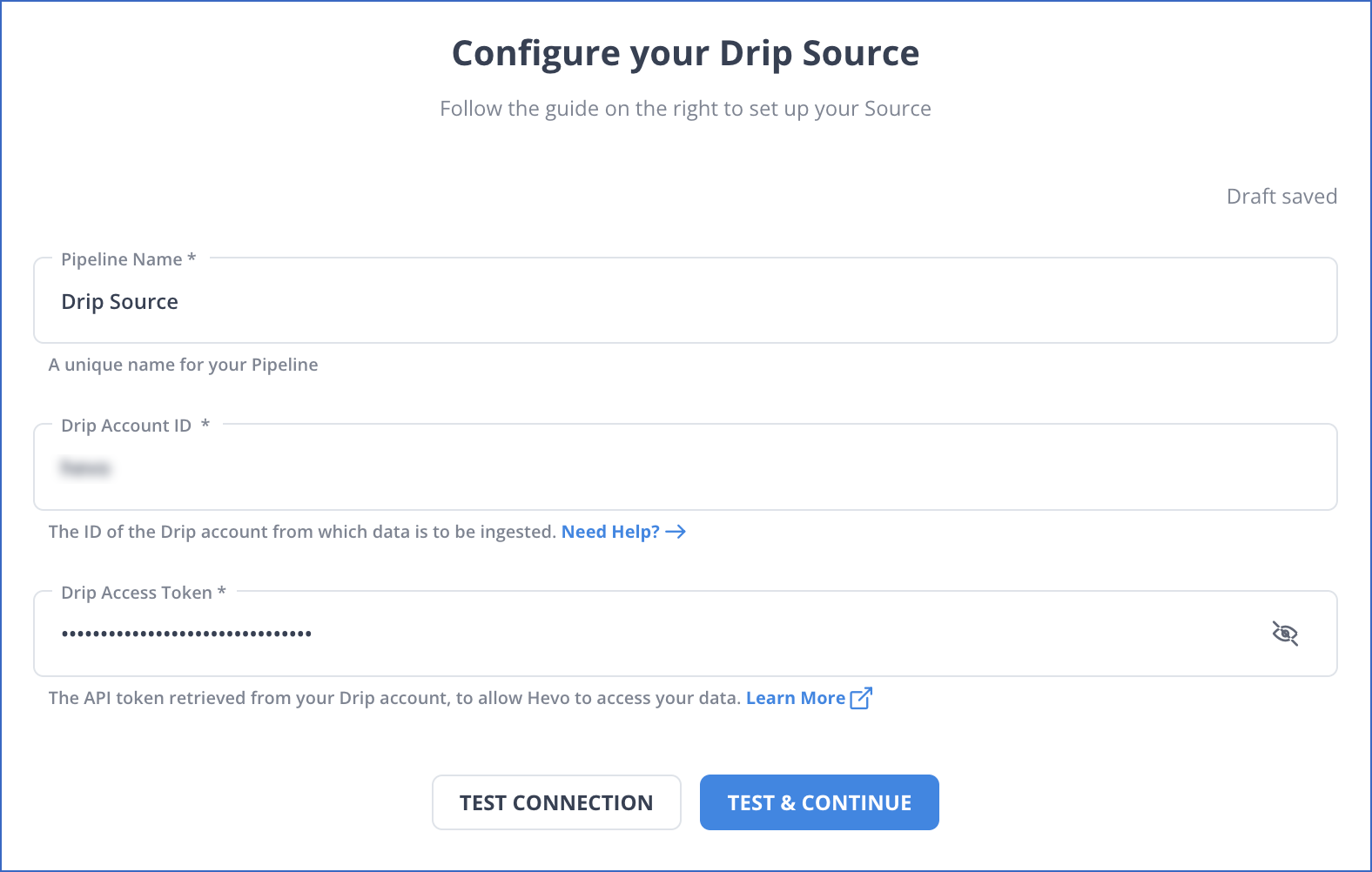
- Step 2: Connecting to Redshift as a Destination
- Click DESTINATIONS in the Navigation Bar.
- Click + CREATE DESTINATION in the Destinations List View.
- On the Add Destination page, select Amazon Redshift.
- On the Configure your Amazon Redshift Destination page, specify the following:
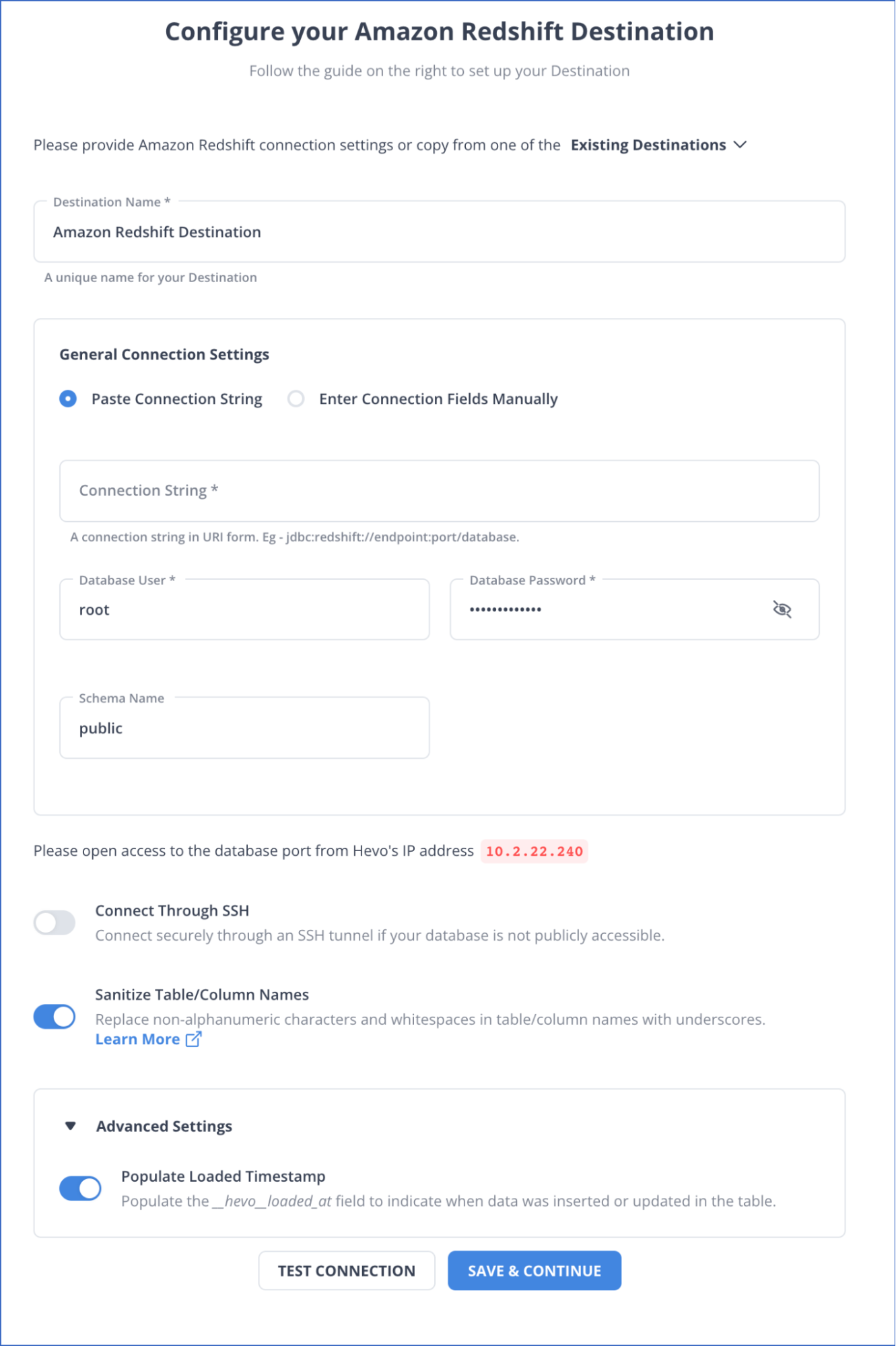
Limitation of Drip to Redshift Connection
Exporting data from your Drip account, loading it onto Amazon S3 buckets, and copying the data to Redshift for storage and analysis is tedious, time-consuming, and does not support real-time data transfer.
Nevertheless, you can use this manual method for a few datasets. But, if you are handling big data, you will witness several data integrity and data consistency issues. Here is where low-code or no-code platforms like Hevo Data are highly beneficial for connecting Drip to Redshift for transferring data effectively.
Conclusion
In this article, you learned how to use Drip to grow your brand via email marketing and personalize content for your target audience. Then you also understood how Amazon Redshift is essential for storing your data securely. Connecting Drip to Redshift can help you democratize data within your organization and allow quick decision-making.
There are various Data Sources that organizations leverage to capture a variety of valuable data points. But, transferring data like Drip to Redshift, from these sources into a Data Warehouse for a holistic analysis is a hectic task.
An Automated Data Pipeline helps in solving this issue and this is where Hevo comes into the picture. Hevo Data is a No-code Data Pipeline and has awesome 150+ pre-built Integrations that you can choose from.
Hevo can help you integrate data from 150+ data sources and load them into a destination to analyze real-time data at an affordable price. It will make your life easier and Data Migration hassle-free. It is user-friendly, reliable, and secure.
FAQ on Drip to Redshift
How do I import data from CSV to Redshift?
To import CSV data to Redshift, upload the file to S3, then use the `COPY` command to load the data from S3 into a Redshift table. Ensure the file permissions and table schema match your CSV structure.
How do I connect to Redshift in Excel?
You can connect to Redshift in Excel by installing the Amazon Redshift ODBC driver. Then, use Excel’s “Get Data” option, select “ODBC,” and configure the connection using your Redshift credentials and the driver.
How to transfer data from SQL Server to Redshift?
You can transfer data from SQL Server to Redshift by exporting the data to CSV, uploading it to S3, and using the `COPY` command to load it into Redshift. Alternatively, tools like AWS DMS (Data Migration Service) can automate the migration process.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



