




The loading stage of the ETL(Extract, Transform & Load) process is an essential part of your Data Pipeline. While consolidating data from multiple sources and loading it to your desired destination, such as a Data Warehouse, you need to take notice of the data volume, structure, target, and load type. On a broader level, you can use the ETL Full Loading or the ETL Incremental Loading method based on your specific use case.
ETL Incremental Loading is often advantageous when dealing with data sources of relatively larger sizes. Compared to full load, it only uploads the data that is either newly added or changed, instead of entirely dumping the dataset.
This article will teach you about ETL Incremental Loading and how to implement it effectively.
Table of Contents
What is ETL Incremental Loading?
- ETL(Extract, Transform, & Load) is a popular process for consolidating data from several sources into a central repository. Many organizations often use the ETL Incremental Loading for their load stage of the ETL, depending on their use case.
- Let’s first understand what an incremental load is in ETL. An Incremental Data Load can be a selective data transfer from one system to another. This process attempts to search for any newly created or modified data compared to the last run of the data transfer process.
- The ETL Incremental Loading is more efficient than the traditional full data load that completely copies the full dataset from a particular source. Reducing the overhead in the ETL process, the ETL Incremental Loading is often designed as time-based, i.e., when the data was created or modified.
- To correctly identify any change(new data, updates, or deleted data), ETL Incremental Loading compares the data present in the target system with the source.
Providing a high-quality ETL solution can be a difficult task if you have a large volume of data. Hevo’s automated, No-code platform empowers you with everything you need to have for a smooth data replication experience.
Check out what makes Hevo amazing:
- Extremely intuitive user interface: The UI eliminates the need for technical resources to set up and manage your data Pipelines. Hevo’s design approach goes beyond data Pipelines.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: Hevo has in-built integrations for 150+ data sources (with 60+ free sources) that can help you scale your data infrastructure as required.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Join thousands of users who trust Hevo for seamless data integration, rated 4.7 on Capterra for its ease and performance.
Get Started with Hevo for Free!Why Do You Need ETL Incremental Loading?
Unlike full loads, incremental load in ETL significantly improves efficiency by reducing transferred data volume. The ETL Incremental Loading is often the choice for many data pipelines due to the following advantages:
- Faster Processing: It usually runs much faster because there is less data to interact with. Considering there are no bottlenecks, the time it takes to transfer and transform data is directly related to the amount of data involved. In many cases, interacting with half the data will reduce the execution time by the same amount.
- Better Risk Handling: The lesser amount of data to touch reduces any potential surface risk associated with a particular load. Sometimes, a given loading process may fail or malfunction, leaving the target data inconsistent. The incremental loading technique is a fractional loading method. It reduces the amount of data you add or change, which may need to be rectified in the event of any irregularity. Because less data is reviewed, it also takes less time to validate the data and review changes.
- Consistent Performance: With ETL Incremental Loading, you get a constant performance despite any fluctuating workloads. Generally, today’s load always contains more data than yesterday’s. Therefore, running a full load can be a time-consuming method as the time required for processing increases monotonously. It only transfers data in case of any modifications, increasing the likelihood of more consistent performance.
- Recording Historical Data: You will notice that many of the source systems regularly delete old data. This can be problematic, as often you may be required to report this data to your downstream systems. Using the ETL Incremental Loading process, you will need to load only the new and modified data. This allows you to keep all the source data(including the data deleted from the upstream sources) in your target destination system.
To maintain accuracy and minimize errors, incremental ETL often relies on timestamps or change data capture (CDC) methods to determine what data needs to be updated. Also, implementing an effective ETL incremental load strategy can contribute to data warehouse optimization and reduce strain on system resources.
If you are looking to dive into the world of data integration and transformation, our blog offers two insightful articles that can help you navigate the ETL landscape.
- ETL vs ELT based on 19 parameters [+case study] provides a comprehensive comparison between ETL and ELT methodologies, exploring essential parameters to consider.
- Best Python ETL tools highlight the top Python-based ETL tools available, equipping you with the knowledge to choose the right tool for your data projects.
Difference between ETL Full Loading and ETL Incremental Loading
| Parameter | ETL Full Loading | ETL Incremental Loading |
| Data Loaded | Entire dataset is loaded each time | Only newly created or updated data is loaded |
| Performance | Inefficient due to large data volumes | Faster and efficient for large datasets |
| Complexity | Simple to set up and maintain | More complex and requires higher maintainability |
| Error Handling | Can redo the entire load if errors occur | Difficult to redo; needs sequential file loading |
| Techniques Used | No special techniques needed | Uses timestamps, CDC, or SCD to track changes |
In ETL Full Loading, the entire dataset is replaced with a newly updated dataset. Hence, it doesn’t require you to maintain any extra information such as timestamps. For instance, you can consider a supermarket that uploads sales data to a data warehouse at the end of the day on a daily basis.
So, if there were 10 sales on Monday, then the 10 sales records would be uploaded at night. On Tuesday, 7 sales were made. Now, on Tuesday night, a complete data set of 10 Sales records from Monday and 7 sales from Tuesday will be uploaded to the Data Warehouse. Though setting up this system is fairly simple & easy to maintain, performance-wise, this is inefficient.
In ETL Incremental Loading, you only need to upload the source data that is different(newly created or updated) from the target system. Based on the amount of data you are loading, Incremental loading can be classified into the following 2 categories:
- Stream Incremental Load: For loading small data volumes.
- Batch Incremental Load: For loading large data volumes.
Considering the same example discussed above, incremental loading would only require you to load the changes on Tuesday. Instead of uploading data for both Monday & Tuesday, you only have to update the 7 newly created sales records.
This is a popular method to save time and resources, although it adds complexity. Though incremental loading is faster than the full load, it requires high maintainability. Compared to the full load, the incremental load does not allow the entire load to be redone if an error occurs. In addition, the files need to be loaded in sequence, so if other data is pending, the error aggravates the problem.
Standard techniques for implementing a data warehouse incremental load strategy include using timestamps, change data capture (CDC), or slowly changing dimensions (SCD).
When should you use ETL Incremental Loading?
ETL Incremental Loading is an excellent alternative to ETL Full Loading in the following cases:
- Dealing with a comparatively bigger data source
- Facing slower performance issues while querying data due to data size and technical limitations.
- Tracking the data changes is possible.
- In several data sources, old data gets deleted. You might want to retain that deleted data in the target system, such as a Data Warehouse.

Incremental Load Method for Loading Data Warehouse Example
- To understand the working of the ETL Incremental Loading, you can consider a data source having 2 tables, i.e, sales and customer.
Customer Table
CustomerID CustomerName Type Entry Date
1 Jack Individual 11-Apr-2021
2 Roland Individual 11-Apr-2021
3 Bayes Corporate 12-Apr-2021Sales Table
ID CustomerID ProductDescription Qty Revenue Sales Date
1 1 Chart Paper 100 4.00 11-Apr-2021
2 1 Board Pin (Box) 1 2.50 11-Apr-2021
3 2 Permanent Marker 1 2.00 11-Apr-2021
4 3 Eraser 200 75.00 12-Apr-2021
5 1 Pencil (HB) 12 4.00 12-Apr-2021- Using ETL Incremental Loading, 2 records from the “Customer Table” and 3 records from the “Sales Date” table will be uploaded to your target data warehouse on 11 April 2021. Now, on the next day (12 April 2021), only 1 record from the customer table and 2 records from the sales table are uploaded to your destination system.
- This is because it only uploads the newly created or modified records instead of copying the entire table.
- To know which records are already present in the target data warehouse, you can use the Entry data column of the customer table and the Sales Data column of the sales table.
- You can now record the date till which the data is present after the data is loaded on that day and then only upload data with the date greater than the previously recorded date. You can create a table “batchdate” to store these dates.
Batch_ID Loaded_Until Status
1 11-Apr-2021 Success
2 12-Apr-2021 SuccessYou can now write your respective SQL Queries to extract data from the:
Customer Table
SELECT c.*
FROM Customer c
WHERE c.entry_date > (select nvl(
max(bd.loaded_until),
to_date('01-01-1900', 'MM-DD-YYYY')
)
from batchdate bd
where bd.status = 'Success'
);- Selection:
c.*: Selects all columns from theCustomertable. - Filtering:
WHERE c.entry_date > (...): Filters customers with anentry_dategreater than a calculated date. - Subquery:
- Finds the maximum
loaded_untildate from thebatchdatetable wherestatusis ‘Success’. - Uses
nvlto return01-01-1900if no successful load date exists.
- Finds the maximum
- Purpose: Selects customers who entered after the last successful batch date or after
01-01-1900if no successful loads are found.
Sales Table
SELECT s.*
FROM Sales s
WHERE s.sales_date > ( select nvl(
max(bd.loaded_until),
to_date('01-01-1900', 'MM-DD-YYYY')
)
from batchdate bd
where bd.status = 'Success'
);- Selection:
s.*: Selects all columns from theSalestable.
- Filtering Condition:
WHERE s.sales_date > (...): Filters sales records with asales_dategreater than a calculated date.
- Subquery:
- Calculates the maximum
loaded_untildate from thebatchdatetable where thestatusis ‘Success’. - Uses
nvl(...)to handleNULLvalues:- If no successful load date exists, it defaults to
01-01-1900.
- If no successful load date exists, it defaults to
- Calculates the maximum
- Overall Purpose:
- The query selects all sales that occurred after the most recent successful load date or after
01-01-1900if no successful loads are found.
- The query selects all sales that occurred after the most recent successful load date or after
- Initially, no data has been loaded, so the batchdate table will be empty. Hence, when you execute the above queries, the nvl function will give the date 01-01-1900 as the max(bd.loaded_until) will return a NULL value.
- This means everything will be extracted. After loading the data for April 11, the first entry can be made into the batchdate table. For the next day(April 12), the max(bd.loaded_until) will now return April 11, 2021. Hence, the data only after April 11 will now be uploaded to the data warehouse.
Implementing ETL Incremental Loading
When choosing the ideal methods of incremental loading in data warehouse settings, it’s essential to consider the source systems, the volume of data to be updated, and the needed load frequency.
To effectively implement the ETL Incremental Loading for your use case, you can through the following two methods:
Method 1: Destination Change Comparison
This method requires a row-wise analysis to compare the unchanged data and the data that has been newly added or modified. Hence, this process might perform slower than the source change Identification method.
This technique requires you to bring all the data you need to monitor for changes into the ETL Data Pipeline. Compared to the Source Change method, it has fewer assumptions. Owing to its flexibility, it can work for almost any structured data source, including text files, XML, API result sets, and other non-relational structures.
You can use this method via the following approaches:
1.1: Brute Force
This is the most direct way & with the least ETL requirements to use the destination change comparison method by analyzing the data row-by-row. If no other comparison method is available, the Brute force comparison works. If you can not use other methods, use it as a last resort.
1.2: Row Hash

For Row hashes, you will be using a single column that stores a kind of calculated binary version of the column used for comparison. This hashed binary value is a computed aggregate of all the specified columns.
Unlike the traditional method of manually comparing each column, Row hashes are usually more efficient. However, the hash value needs to be calculated, which adds a bit of complexity and overhead but is usually worth improving performance.
1.3: Upsert Operations

UPSERT, i.e., update & insert, will effectively process both newly added and modified data in one step. This is done by matching the unique key columns and comparing the ones confirming the change. You can also bring in the row hash method within this merge operation to make the comparison.
Popular RDMS systems such as SQL Server, Oracle, Postgres, and MySQL work with the UPSERT logic. On most systems, UPSERT operations can also handle data deleted at the source. You can also decide whether to delete the data on the target or softly delete it, i.e., leave it as it is and mark it as deleted.
Method 2: Source Change Identification
This method opts for a selective approach by extracting only the new and modified data from the source system since the last run of the loading process. This essentially puts a limit on the amount of data that is being brought to the ETL Data Pipeline.
It is done by only extracting the data that actually needs to be moved and excluding the unchanged data from the load cycle. The less data you need to interact with, the faster the data processing. To apply this technique, you can employ the following approaches:
2.1: Change Tracking

For a simple, reliable & easy-to-use method, you can try out the change tracking technique present in most of the RDBMSs today. Change tracking makes it easy to see which rows have been newly created, modified, or deleted since the last load. However, this is not always an option because you need to modify the source database to use change tracking for incremental loads.
2.2: Update Dates or Row-level Insert
This is the easiest way to detect changes in the source. With this method, for each table, you will have a column that records the date the data was loaded and the date the data was modified. This allows you to identify each row when it changes effectively. Although it turns out that this method can be unreliable. Especially on third-party systems that you can’t control.
2.3: Change Data Capture
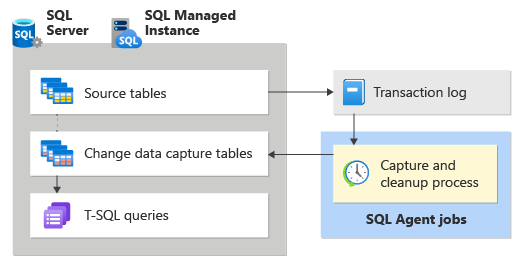
Change data capture is another brilliant source-side change detection method available in SQL Server and other RDBMS systems. Though change data capture allows you to perform several tasks compared to simple change detection, it can still be used to identify which data has been newly created, modified, or deleted.
2.4: With a ‘Last Updated Timestamp’
The source system includes a column called ‘Last Updated Timestamp’, which indicates the last time each row was modified. By leveraging this column, we can selectively extract updated records after the last extraction timestamp.
For example, if the previous load was completed on 2022-01-09 12:00:00, in the next run, we would only extract records where the ‘Last Updated Timestamp’ is later than this timestamp. This method allows us to track both new records and updates.
2.5: Without a ‘Last Updated Timestamp’
When there is no ‘Last Updated Timestamp,’ a control table can be used to store metadata like the last extraction timestamp and the number of loaded records. A surrogate key or a combination of natural keys with a checksum can be used to identify new or changed records. Using an auto-incrementing ID for new records is another common approach to track new records. However, tracking updated records with this approach is not possible.
Example:
Consider a large-scale e-commerce platform as an example. Suppose the platform operates a ‘users’ table that maintains a record of all users, with new users registering every second.
Using a Full Load strategy would entail loading the entire ‘users’ table into the data warehouse during each ETL run, despite the majority of the data remaining unchanged. This approach would be highly inefficient, given the size of the table.
Alternatively, an Incremental Load strategy would only load new users since the previous ETL run. The process is straightforward if a ‘Last Updated Timestamp’ exists in the ‘users’ table. However, if not, the ‘user_id’ (assuming it is an auto-incrementing ID) can be used, and the highest ‘user_id’ loaded can be stored in the control table. During the subsequent ETL run, only users with a ‘user_id’ greater than the stored value would be extracted.
Key Challenges of ETL Incremental Loading
While implementing and working with ETL Incremental Loading, you may encounter the following ETL challenges:
- Monitoring: While extracting and consolidating data from different sources, you will occasionally observe errors. These can occur because your API credentials have expired or you have difficulty interacting with your API. You need constant monitoring of your processes to identify and correct these errors as quickly as possible.
- Incompatibilities: You can add new records that invalidate existing data. For example, providing an integer to a column that is expecting a text. This is especially problematic when adding real-time data, which creates a bottleneck because end users can query that data to get inaccurate or incomplete results and not be able to add new datasets.
- Sequencing: Data pipelines are often distributed systems to maximize availability. This can cause the data to be processed in a different order than when it was received, especially when the data is modified or deleted.
- Dependencies: Regarding ETL management, it’s important to understand the dependencies between processes or subprocesses. For example, if process 1 fails, do you want to run process 2? This gets more complicated as more processes and subprocesses grow.
- Tuning: The tuning process is required to ensure that the data in the ETL data warehouse is accurate and consistent. This requires you to perform ETL testing regularly. However, data warehouse tuning is an ongoing process.
Managing the Challenges of ETL Incremental Loading
- To effectively manage & maintain an efficient ETL Incremental Loading, you need to find the right balance between parallel and serial processing.
- Serial processing occurs when one task is completed at a time, and the processor executes the tasks in a prescribed order. Therefore, you start a new task as soon as the previous task is finished.
- Compared to Serial Processing, Parallel processing executes multiple tasks at the same time.
- If the processes are not interdependent when loading the data, the processes can be processed in parallel, saving a lot of time.
- However, if there are dependencies, this can be complicated, and the data must be processed serially. You can also use Parallel processing by dividing your data into smaller data files for parallel access.
- You can easily create a pipeline by running multiple components on the same data stream at the same time, and the components can run multiple processes on the same data stream.
Conclusion
In this article, you have learned in detail about the ETL Incremental Loading process. Compared to the Full Loading process, incremental loading is fast, can perform consistently with fluctuating workloads, and allows you to store historical data. You can implement change detection methods using either source- or destination-sided methods.
As you collect and manage your data across several applications and databases in your business, it is important to consolidate it for a complete performance analysis of your business. However, it is a time-consuming and resource-intensive task to continuously monitor the Data Connectors. To achieve this efficiently, you need to assign a portion of your engineering bandwidth to integrate data from all sources, Clean & Transform it, and finally, Incrementally Load it to a Cloud Data Warehouse or a destination of your choice for further Business Analytics.
All of these challenges can be comfortably solved by a Cloud-based ETL tool such as Hevo Data. Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. What is incremental ETL?
Incremental ETL involves loading only the new or updated data into the target system instead of loading the entire dataset every time, making the process faster and more efficient.
2. What is the meaning of incremental data?
Incremental data refers to the new or changed records since the last data load, which are selectively added to the existing data.
3. What is the difference between incremental and full load?
Full load replaces the entire dataset every time, while incremental load only updates new or modified data. Tools like Hevo make incremental loading simple and automated.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



