




‘Hey, how many customers do we receive through email? And, through which marketing channel do our customers rate our product the best?’ Do you have an answer to such questions from your team’s data analysts? If yes, great! If not, don’t worry. I’m here to help you with that.
Replicating data from Freshsales to BigQuery will help you revert to them with accurate results. How to do that, you ask? In this blog, I will introduce you to two ways to connect Freshsales to BigQuery for data replication. I will also explain the detailed benefits of them.
Table of Contents
What is Freshsales?
Freshsales is a cloud-based customer relationship management (CRM) software designed to help businesses streamline their sales processes and manage customer interactions effectively. Part of the Freshworks suite, Freshsales offers a variety of tools for sales teams to engage with prospects, track leads, and close deals efficiently.
Key Features of Freshsales:
- Email Tracking and Automation: Send, track, and automate emails, ensuring timely follow-ups with real-time notifications when emails are opened or clicked.
- Lead and Contact Management: Organize and manage your leads, contacts, and customer details in one place with a 360-degree view of interactions.
- AI-Powered Insights: Freddy AI, Freshsales’ AI assistant, provides sales insights, lead scoring, and predictions to help prioritize high-value leads and close deals faster.
- Pipeline Management: Visualize and manage your sales pipeline with drag-and-drop functionality, keeping track of deals at every stage.
Take advantage of CRM data stored in Freshsales along with its reliability at scale and robust feature set by seamlessly connecting it with various destinations using Hevo. Hevo’s no-code platform empowers teams to:
- Integrate data from 150+ sources(60+ free sources).
- Simplify data mapping and transformations using features like drag-and-drop.
- Easily migrate different data types like CSV, JSON, etc., with the auto-mapping feature.
Join 2000+ happy customers like Whatfix and Thoughtspot, who’ve streamlined their data operations. See why Hevo is the #1 choice for building modern data stacks.
Get Started with Hevo for FreeWhat is BigQuery?
Google BigQuery is a fully managed and serverless enterprise cloud data warehouse. It uses Dremel technology, which transforms SQL queries into tree structures. BigQuery provides an outstanding query performance owing to its column-based storage system.
Key Features:
- Serverless Architecture: BigQuery manages servers and storage in the background, so a user does not need to.
- High Scalability: It scales seamlessly to handle petabytes of data.
- SQL Compatibility: It supports ANSI SQL, which is useful for people who already know SQL and want to write and run queries. This also allows a user to combine various BI tools for data visualization.
- Machine Learning: BigQuery ML allows users to train and run machine learning models in BigQuery using only SQL syntax.
What are the Ways to Migrate Data from Freshsales to BigQuery?
Method 1: The easiest way to Migrate Data from Freshsales to BigQuery- Using Hevo
Step 1: Configure Freshsales as your source.
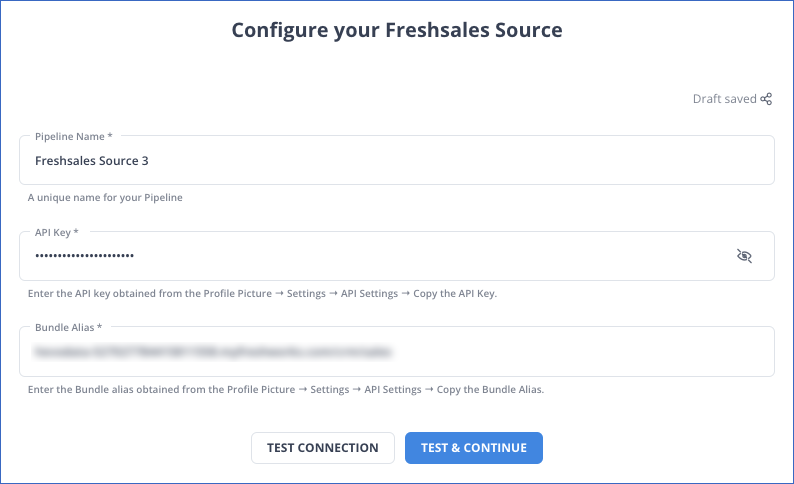
Step 2: Configure BigQuery as your destination

Method 2: The Manual Method to Load Data from Freshsales to BigQuery Using CSV files
Step 1: Export Data from Freshsales to CSV
- Select the desired report category (e.g., Leads, Contacts, Accounts, Deals).
- Choose the report to export.
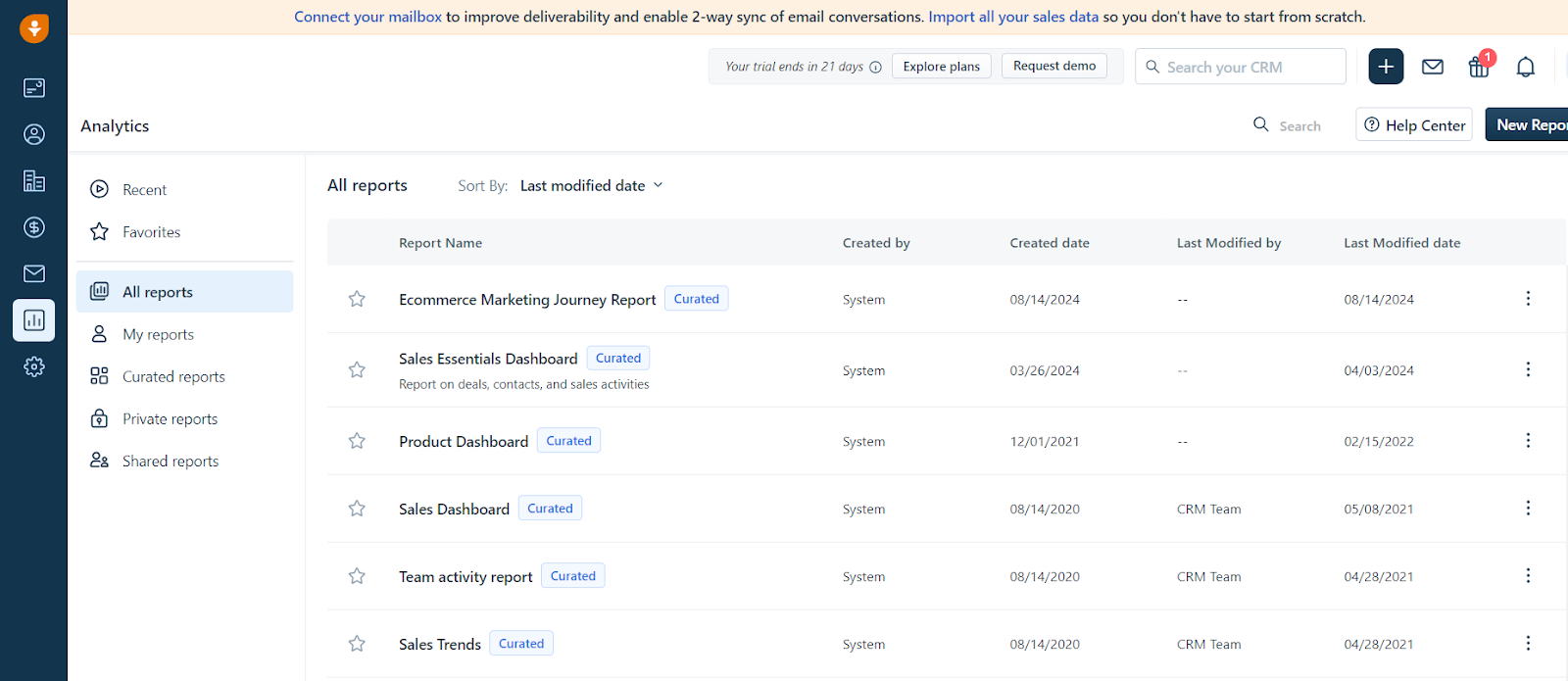
- For immediate export, select Export as CSV.
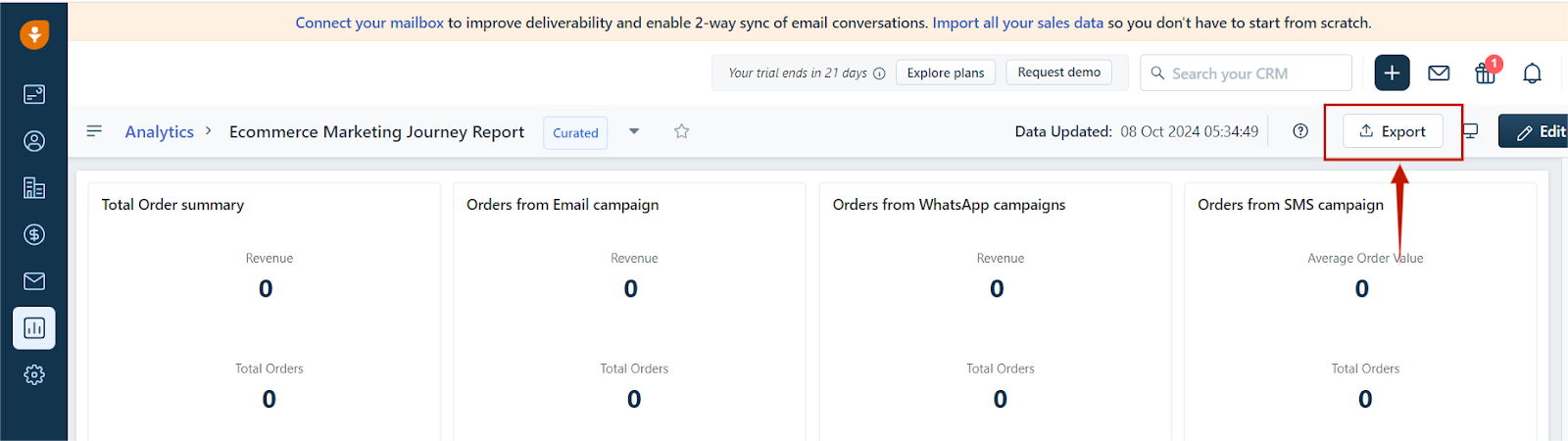
- To customize the report, select Edit Report:
- Adjust filters, grouping, and time period.
- Choose columns by selecting Simple as the table type.
- Click Preview Data and then Add Field to select columns.
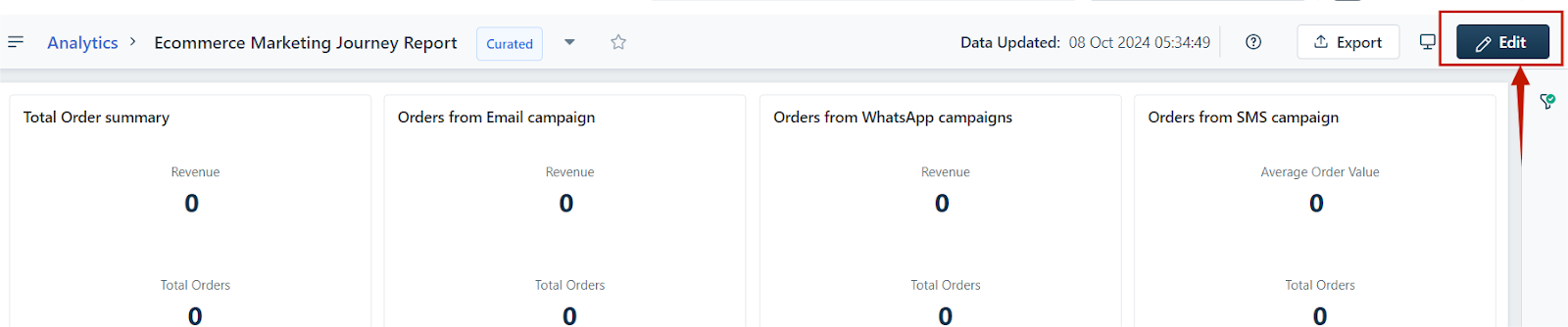
- Save the report and click Export as CSV.
- You’ll receive a download link via email or flash notification.
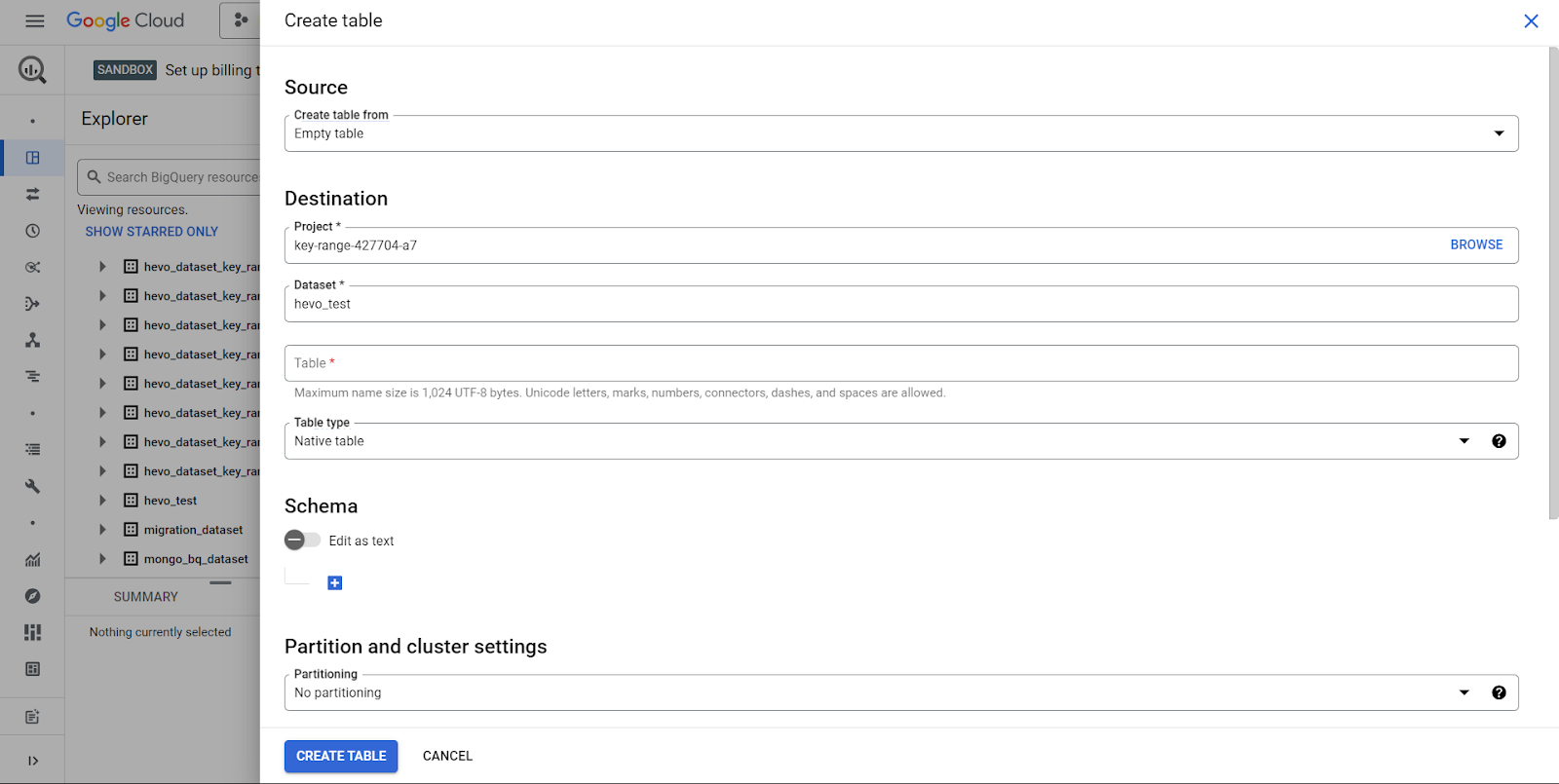
Step 2: Import CSV Data into BigQuery
- Open Google Cloud Console and navigate to BigQuery.
- Select a dataset under the Explorer panel.
- Under Actions, click Open.
- Go to Create Table and:
- For Create table from, select Upload and browse for your CSV file.
- Set the File format to CSV.
- In the Destination section:
- Choose the project and dataset.
- Name your new table and ensure the table type is Native table.
- Under the Schema section:
- Enable Auto-detect for CSV files or manually input schema.
- Click Create Table to complete the import.
Limitations of Using CSV files to Transfer Data from Toggl to Redshift
- Lack of Data Validation: CSV files never force proper validation on input data. As a result, such faulty data may be transferred into Snowflake, thus posing difficulties to query or further analyze.
- Time-Consuming: The data exported from Lemlist needs to be extracted in CSV files and imported manually in Snowflake, so it is more of a human-intensive process. This process will be inefficient if one were to transfer large or frequent loads.
- Human Error: There is a high probability of probable mistakes in information extraction, transformation, or uploading in manual processes that would make the data inconsistent.
- No Real-Time Updates: CSV transfers can be only batched based, meaning data isn’t updated in real-time. This might result in analytics and reporting conducted in Snowflake based on outdated information.

What Can You Achieve by Replicating Your Data from Freshsales to BigQuery?
You can help your data analysts in obtaining crucial business insights for the following situations by replicating data from Freshsales to BigQuery. Does the list include your use case?
- How much of a region’s consumer inquiries come via email?
- Which client acquisition method has generated the most support tickets?
- What proportion of agents reply to tickets that customers submit over the communication channel?
- Which marketing channel has the highest customer satisfaction ratings?
Conclusion
In this blog, you learned two ways to migrate your data from Freshsales to BigQuery. The manual method using CSVs has a lot of challenges and is more error-prone. To avoid these errors use the second method, i.e., use Hevo.
Hevo is a reliable, no-code, cost-effective platform that automates the process of data migration to provide you an effortless experience. Sign up for Hevo’s 14-day free trial today and get to know more.
Frequently Asked Questions
1. How do I export data from Datastore to BigQuery?
-Use Cloud Datastore Export to export data to a Google Cloud Storage bucket.
-Load the exported data from Cloud Storage into BigQuery using the BigQuery Data Transfer Service or manually import the data by creating a BigQuery load job.
2. How to convert Oracle query to BigQuery?
-Manually adjust the SQL syntax, as BigQuery and Oracle have different SQL dialects (e.g., replace Oracle’s NVL() with BigQuery’s IFNULL(), or adjust JOIN syntax).
-Use Google’s SQL translation tool (part of the Data Migration service) to assist with translating Oracle queries to BigQuery-compatible SQL.
-Some ETL tools like Hevo or Fivetran can help automate query conversions during migration.
3. How to migrate data from SQL to BigQuery?
-Use Google’s Database Migration Service (DMS) to streamline the migration.
-Alternatively, use ETL tools like Hevo, Fivetran, or Stitch to extract, transform, and load (ETL) data from SQL to BigQuery.
-You can also export SQL data to CSV and then load it into BigQuery using the BigQuery console or the bq command-line tool.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



