

Databricks SQL is an efficient platform for querying and analyzing large datasets. Its SQL editor, interactive dashboards, and robust BI tool integration features can help you streamline data exploration and reporting. As a fully managed service, it handles the complexities of infrastructure management, facilitates informed decision-making, and helps you gain a competitive edge.
This article introduces the platform, its functioning, benefits, and the best practices while using it to gain data-driven insights.
Table of Contents
What is Databricks SQL?
Databricks SQL is a collection of services managed by the Databricks platform that induce data warehousing capabilities in a data lake. It provides a user-friendly interface and computational resources that enable you to run SQL queries and create visualizations of your datasets stored in a data lake. The queried data can provide valuable insights for revenue generation in your enterprise.
While using it, you can store SQL code snippets for quick use and cache query results to reduce runtime. It allows you to schedule the automatic refreshing of query updates and receive warnings when any changes are made in the database. These functionalities of the platform help you to leverage data lakehouse services in a scalable and cost-effective way.
Are you looking for ways to connect Databricks with Google Cloud Storage? Hevo has helped customers across 45+ countries migrate data seamlessly. Hevo streamlines the process of migrating data by offering:
- Seamlessly data transfer between Salesforce, Amazon S3, and 150+ other sources.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
- In-built transformations like drag-and-drop to analyze your CRM data.
Don’t just take our word for it—try Hevo and experience why industry leaders like Whatfix say,” We’re extremely happy to have Hevo on our side.”
Get Started with Hevo for FreeTypes of Warehouses Supported by Databricks Lakehouse Architecture
Databricks Lakehouse supports the following three types of warehouses:
1. Classic
The classic warehouse supports limited functionalities and basic performance features. It supports the Photon engine and can be used for entry-level operations.
2. Pro
The pro warehouse supports all features and performs better than the classic version. Although it is less responsive to autoscaling, it supports Predictive IO features.
3. Serverless
The serverless warehouse supports advanced performance features like the Intelligent Workload Management (IWM) along with features provided by the pro version. You can scale the serverless version more quickly than the other versions.
What is the SQL Editor?
The SQL editor in Databricks is a web-based interface that allows you to write, execute, and manage SQL queries within the Databricks workspace. It enables you to create, save, edit, terminate, and run multiple queries. You can browse data objects and Unity Catalog-governed database objects from the Catalog Explorer in the SQL editor without an active compute.
The SQL editor also facilitates the creation of interactive dashboards and visualizations. It enables you to share your SQL queries with your colleagues by providing them access as owner or viewer according to your security requirements.
Databricks SQL Tools
You can integrate the Databricks ecosystem with native or third-party tools to execute SQL commands. Some of these are as follows:
1. Databricks SQL CLI
You can use CLI to execute SQL commands on your Databricks SQL warehouse. It enables you to perform queries on your current Databricks warehouse from your terminal or using the Windows command prompt.
2. Databricks Driver for SQLTools
This tool facilitates using Visual Studio Code, a code editor solution, to interact with the platform warehouses in a remote Databricks environment. Databricks driver for SQLTools allows you to use the SQLTools extension to browse SQL objects and execute SQL queries.
3. DataGrip with Databricks Integration
You can easily integrate databases in Databricks with DataGrip, an integrated development environment for executing SQL queries. It offers features such as a query console, explain plans, schema navigation, version-control integration, intelligent code completion, and real-time analysis.
4. DBeaver and Databricks Integration
DBeaver is a multi-platform database solution that allows you to work efficiently with databases for data engineering, data analysis, and data administrator roles. It supports any database, including Databricks, for SQL query execution. You can also browse data objects in your database using relevant SQL commands.
5. SQL Workbench for Java
SQL Workbench for Java is a script query tool that you can use to interact with your SQL data in Databricks. Although Databricks does not natively support it, you can use the Databricks JDBC driver to set up a connection.
How Does Databricks SQL Work?
The working of this platform can be classified into the following three steps:
Step 1: Access Data in Data Lake
This platform allows you to query any type of data stored in a data lake, such as CSV, Parquet, JSON, or ORC. You can also query data from external sources, such as traditional databases like MySQL or data warehouses like Snowflake.
Databricks provides Delta Lake, a storage layer that enhances the storage features of existing data lakes. You can use it to add schema enforcement, and ACID transaction features to the data lake for proper data management.
Step 2: Query Execution
Databricks provides an SQL warehouse, a separate compute resource to facilitate the execution of SQL queries on data stored in the data lake. It is highly scalable and allows you to perform complex queries on large datasets. You can also use any of the above-mentioned tools for successful SQL query execution.
On running a query, this platform leverages Photon, a native query engine of Databricks, to execute SQL workloads efficiently. It is a vectorized engine that facilitates batch-wise data processing instead of row-wise processing to reduce downtime and usage costs.
Step 3: Data Governance
After query execution, you can integrate this platform with Unity Catalog to ensure the implementation of the data governance framework. Unity Catalog is a data governance solution that provides centralized access controls, auditing, and data discovery features in the Databricks workspace.
You can use it to manage your data assets, such as tables or views. This ensures that your data is secure and reliable for making data-driven decisions.
Benefits of Databricks SQL
Here are some benefits of using this platform:
- Ease of use: SQL is a simpler programming language, and you do not need much expertise for data analytics. You can easily work with this platform to gain insights from your datasets.
- Unified Ecosystem of Tools: This platform is a bouquet of services that enables you to execute SQL queries with high precision. It offers auto-scaling, a built-in SQL editor, visualization tools, and collaboration capabilities to improve operational efficiency.
- Robust Data Governance: You can utilize Databricks’ Unity Catalog feature for data governance and security while leveraging this platform. It lets you maintain high data quality, increasing authenticity and operational efficiency.
- Advanced Functionality: You can use Databricks SQL with Databricks Runtime ML to utilize machine learning for advanced data analysis. It also facilitates the use of Apache Spark to perform complex data manipulation, transformation, and analysis tasks.
- Cost-Effectiveness: Using this platform is cost-effective for SQL data analytics as it offers a unified solution for various sub-processes of analytics such as data collection, cleaning, or modeling. You can also prefer to use the serverless version of this platform to get high performance at a lower cost without infrastructure management.
Databricks SQL Best Practices
You can adapt the following best practices to leverage this platform efficiently:
1. Avoid Using SELECT * FROM My_Table
You should select only the required columns for analysis instead of the whole table. The SELECT * FROM retrieves all the columns of the table, resulting in discrepancies in query execution. This happens especially when many users are working on the same table simultaneously. You can use the Data Explorer feature in the Databricks Console to profile your data tables to get statistical details and perform data analysis.
2. Streamline Your Search
Limiting the number of rows in query execution can enhance the performance of Databricks SQL. You can use the LIMIT clause to prevent the execution of extra rows in a query and retrieve subsets from your datasets. You can also apply the function to control the amount of memory used in query execution for performance enhancement and cost optimization.
It adds the limit of 1000 rows to all queries by default. You can further limit this by using the LIMIT clause to prevent the querying of irrelevant rows. Also, the WHERE clause helps you to filter your data based on specific conditions. You can also use it to avoid unnecessary querying.
3. Use Caching
Caching is a process of storing data at a temporary location for quick access. You can leverage caching in this platform to reduce the time required for repeated computational tasks. It offers various caching mechanisms such as DBSQL UI cache, query result cache, and disk cache to reduce query processing time. However, you should use the cache features judiciously to avoid memory overuse.
4. Choose Wisely between CTE and Subqueries
Common Table Expressions (CTE) and subqueries are compelling features that help you to organize data and execute queries effectively. Though both give similar results, subqueries can sometimes be less efficient than CTEs, especially for larger datasets.
Depending on specific queries, the query optimizer may differentiate between subqueries and CTEs. The query optimizer is a software component that determines the execution price plan based on your written query. It is advisable to prefer using CTEs as they provide better performance for complex querying and are easy to maintain.
5. Understand Your Query Plan
You should understand and analyze your query plan before execution. For this, you can use the EXPLAIN clause. It tells you how your query will be executed so that you can decide on ways to optimize it.
The platform also provides an Adaptive Query Execution (AQE) feature that can re-optimize the query plan during execution. This is useful when your statistics data is missing or when the data distribution is uneven.
Explore top Databricks competitors and alternatives for 2025 to see how they stack up against Databricks SQL.
What is Databricks SQL Analytics?
Databricks SQL analytics is a Databricks feature that enables you to analyze a massive amount of data in real-time. You can use it to query data, extract useful insights, and make better decisions. This feature is based on Apache Spark, which provides a scalable processing engine for advanced data analysis.
You can integrate data from different sources, such as databases, data warehouses, and cloud storage platforms, to create a seamless data pipeline workflow. It offers high scalability, enabling you to scale up data processing and analysis activities to improve your operational efficiency.
It also provides an easy-to-use interface that can help you conduct all the data analytics tasks without much expertise.
How to Perform Databricks SQL Analytics?
You can refer to the below steps to perform analytics:
Step 1: Setting up the Environment
Create a Databricks workspace if you do not already have one, and launch a SQL warehouse for query execution.
Step 2: Data Ingestion
You can ingest data into Databricks from databases, data warehouses, or cloud platforms. You can use any third-party data integration platform like Hevo Data to achieve data ingestion. It is a no-code ELT platform providing real-time data integration and a cost-effective way to automate your data pipeline workflow. With over 150 source connectors, you can integrate your data into multiple platforms, conduct advanced analysis on your data, and produce important insights. After ingesting data, use SQL commands to create tables and views in Databricks workspace.
Step 3: Data Exploration and Transformation
To get a comprehensive understanding of your data, perform data exploration. You can also remove any discrepancies in the datasets through cleaning and transformation. Here, you can use Hevo’s Python and drag-and-drop data transformation techniques to convert your data into a consistent format.
Step 4: Query and Data Analysis
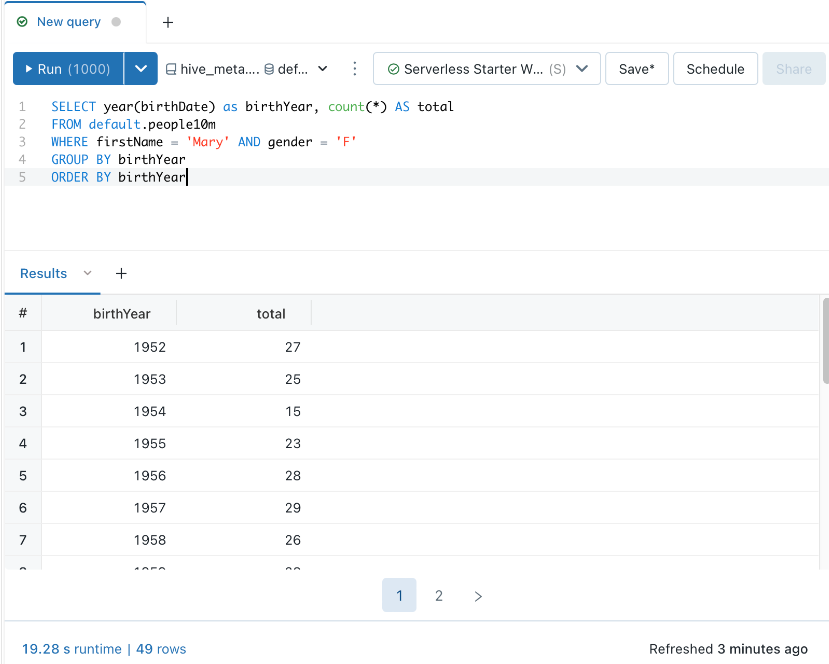
You can query and analyze your Databricks data using various SQL functions and clauses. Take a look at the following steps:
- Click the New Query button on the user interface to create a new query. Select the data source to query and enter your SQL code. Then, type your query in the editor and run it by clicking the ‘Run’ button.
- You can use the WHERE clause as a filter to retrieve relevant information. It helps narrow down the query and reduce downtime.
- Query parameters allow you to reuse your queries and save time and effort processing the same queries with different input values. So, you should design and execute effective query parameters that support various values without changing the basic code.
- You can use the Query Snippet option of analytics feature to create snippets of your query. These snippets are pre-written codes, and by leveraging this option in this platform, you can simplify the writing process for repetitive queries.
The query results are displayed in the workspace on execution, and you can analyze them for informed decision-making.
Step 5: Visualization
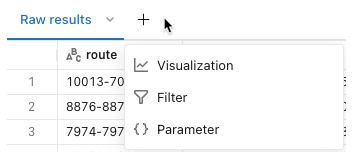
For in-depth analysis, you can use the built-in visualization features of Databricks SQL analytics. Click the Visualizations tab on the Databricks SQL analytics interface to do this. Select the type of chart you want, such as a bar chart or pie chart, and customize it according to your requirements. You can also create an interactive dashboard by arranging all your visualizations in an orderly manner to get a comprehensive picture of your data.

Conclusion
This blog gives you an overview of Databricks SQL and provides benefits, best practices, and steps to conduct data analytics using this platform. You can use this information to retrieve data stored in various disparate sources and analyze it effectively using SQL queries.
Learn how Autoscaling in Databricks enhances performance and efficiency, complementing your understanding of Databricks SQL capabilities.
To ingest data scattered in multiple locations, you can use a data integration platform such as Hevo Data. Its extensive library of connectors, data transformation techniques, auto schema mapping, and incremental data loading features make it a versatile solution. Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
FAQs
1. What is Databricks SQL used for?
Databricks SQL can be used for profiling your data tables to get statistical details, avoiding unnecessary querying and abstain from memory overuse.
2. What is the difference between Databricks SQL and Spark SQL?
-Databricks SQL is a collection of Databricks services, and it facilitates interactive data analytics and business intelligence. On the other hand, Spark SQL is a module used for structured data processing in Spark and it primarily enables data processing within the Spark ecosystem.
-Spark SQL is, in fact, a component of Databricks SQL. It facilitates unified data processing, enhanced performance, and ecosystem compatibility in Databricks. You can use any of these solutions to meet your data processing requirements.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





