




 Quick Take
Quick TakeMoving Google Ads data to Databricks for advanced analytics can be achieved through multiple methods:
- Hevo’s no-code ETL – Automated 3-step setup with real-time data sync
- Google AdWords API – Powerful but complex, requires technical expertise
- Google Analytics Premium export – A Costly and cumbersome process
This guide focuses on Hevo’s streamlined approach, eliminating the technical barriers of API integration while providing faster insights than manual export methods.
Today, marketing thrives on data-driven strategies, with businesses leveraging Google Ads to run impactful campaigns and analyze engagement data. To unlock deeper insights, consolidating this data in a unified platform like Databricks is essential for advanced analytics and decision-making. This post will guide you through seamlessly replicating data from Google Ads to Databricks.
While Google’s AdWords API offers powerful features like custom reporting and bidding management, it can be complex and challenging for non-technical users. Alternatives like exporting data via Google Analytics Premium are costly and cumbersome. Hevo’s no-code ETL pipelines simplify the process, enabling automated data replication from Google Ads to Databricks in just three easy steps—no technical expertise required!
Table of Contents
How to Replicate Google Ads Data to Databricks Using Hevo
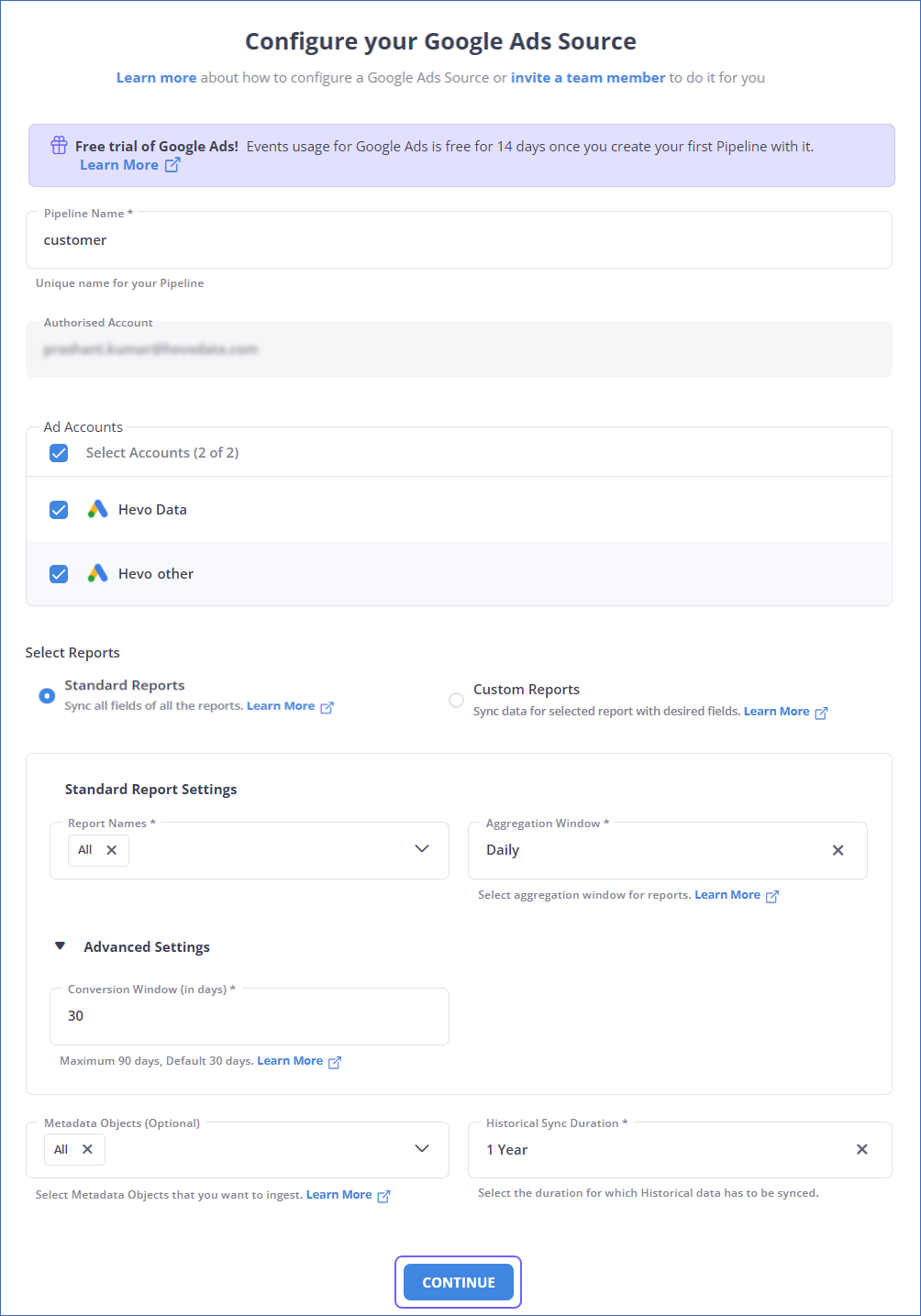
Step 1: Configure Google Ads as a Source
Authenticate and Configure your Google Ads Source.
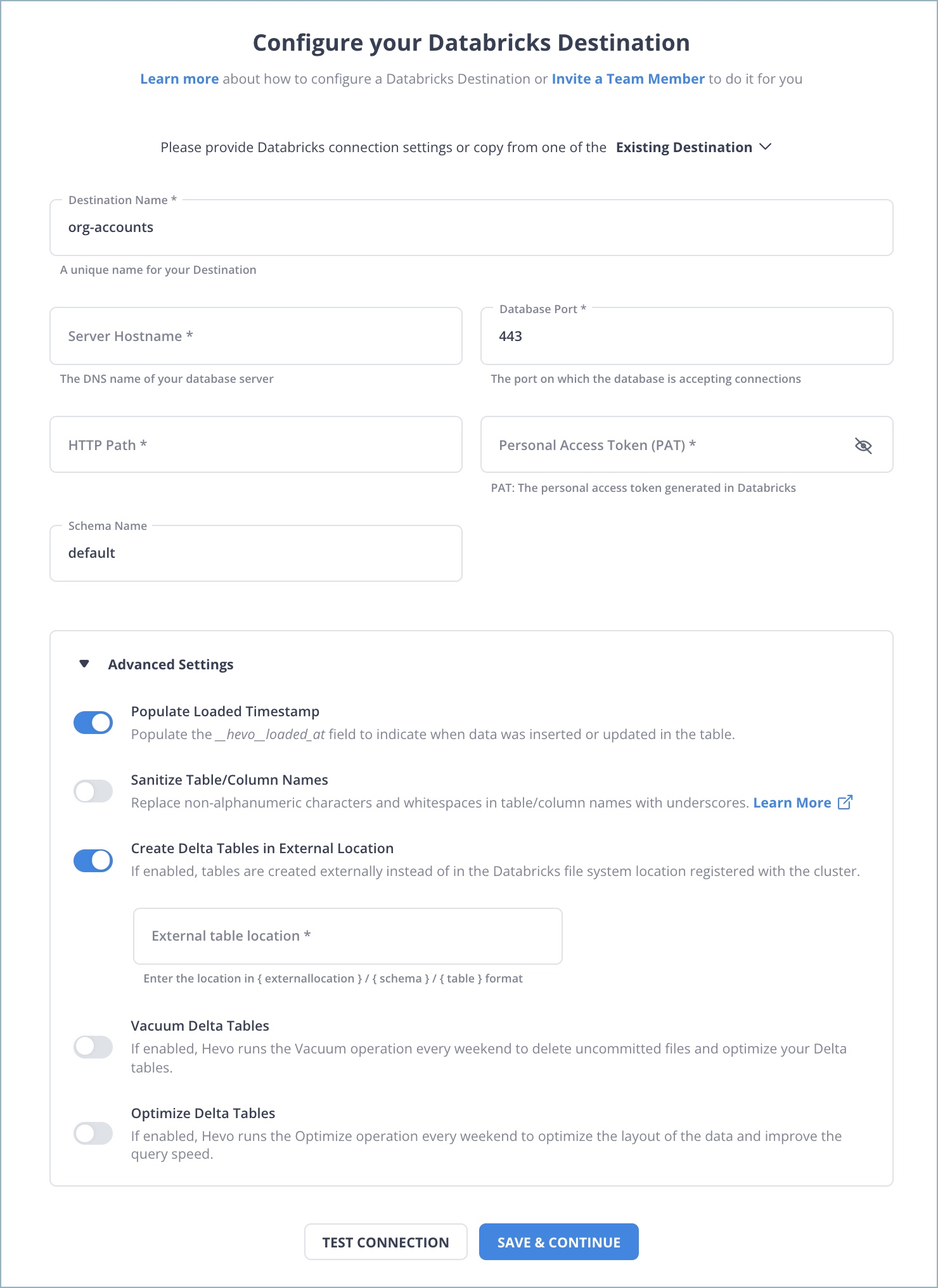
Step 2: Configure Databricks as Destination
In the next step, we will configure Databricks as the destination.
Step 3: All Done to Setup Your ETL Pipeline
And next comes…. Well, nothing. Once your Google Ads to Databricks ETL Pipeline is configured, Hevo will collect new and updated data from your Google Ads every five minutes (the default pipeline frequency) and duplicate it into Databricks. Depending on your needs, you can change the pipeline frequency from 5 minutes to an hour.
Data Replication Frequency
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 5 Mins | 5 Mins | 24 Hrs | 1-24 |
Don’t believe setting up an ETL process can be this easy with Hevo? I encourage you to head over to the official Hevo’s Databricks as Destination Docs and Hevo’s Google Ads as Source Docs, which make the reassuring claim.
Why Use Hevo?
If yours is anything like the 1000+ data-driven companies that use Hevo, more than 70% of the business apps you use are SaaS applications Integrating the data from these sources in a timely way is crucial to fuel analytics and the decisions that are taken from it. But given how fast API endpoints etc, can change, creating and managing these pipelines can be a soul-sucking exercise.
Hevo’s no-code data pipeline platform lets you connect over 150+ sources like Google Ads in a matter of minutes to deliver data in near real-time to your warehouse like Databricks.
Here’s how Hevo challenges the normal to beget the new ‘exceptional.’
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: As your sources and the volume of data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Understanding Google Ads to Databricks Integration
Google Ads

Google Ads is a powerful online advertising platform by Google that enables businesses to create targeted ads on search engines, websites, and apps. It provides tools for campaign management, audience targeting, and performance tracking, allowing businesses to optimize ad spending and drive conversions effectively.
Databricks

Databricks is a cloud-based data platform designed for big data analytics and machine learning. It provides a unified environment for data engineering, data science, and business analytics. With its scalability and robust features, Databricks simplifies managing and analyzing large datasets for actionable insights.
Why Integrate Google Ads to Databricks?
Centralize your Google Ads Data with Databricks: Consolidate your data into a single repository for archiving, reporting, analytics, machine learning, artificial intelligence, and other purposes.
Measure Campaign Performance in Single Dashboard: Regular performance monitoring is vital. You can leverage Google Ads data with Databricks and run advanced analytics to get better insights. Good insights will help you understand the quality of leads generated through ad campaigns.
Use your Engineering Bandwidth Judiciously: Getting your data from Google Ads to Databricks might be difficult. Engineering bandwidth to build and maintain the pipeline can cost you a fortune. You can get rid of that hassle with the help of an automated data pipeline solution.

You can also read more about:
Final Thoughts
After replicating your data into Databricks, you can connect to reporting and dashboard systems such as Looker, Tableau, Metabase, and others on top of Databricks to acquire business insights. These dashboards are the third and final tier of your data analytics stack and are responsible for creating compelling visualizations of your data.
Initiate your journey with Hevo today and enjoy fully automated, hassle-free data replication for 150+ sources. Hevo’s free trial gives you limitless free sources and models to pick from and a spectacular live chat service supported by an incredible 24/7 support team to help you get started. Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
FAQs
1. Can you connect Google Ads to Google Analytics?
Yes, you can connect Google Ads to Google Analytics to track ad performance, user behavior, and campaign effectiveness across platforms.
2. How do I export Google Ads assets?
You can export Google Ads assets through the Google Ads Editor by selecting campaigns, ads, or assets and exporting them as CSV files.
3. How do I access Google Ads data?
Access Google Ads data via the Google Ads interface, API, or by linking to tools like Google Analytics or BigQuery for detailed analysis.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



