


Apache Hive is a Data Warehouse system that facilitates writing, reading, and manipulating large datasets residing across distributed storage using SQL. SQL (Structured Query Language) is a querying language that is used to perform various operations on the records stored in a database. These operations include deleting records, updating records, creating and modifying views, tables, etc.
This article will help you get a deeper understanding of Hive vs SQL by considering 5 key factors language, purpose, data analysis, training and support availability, and pricing. The article starts with a brief introduction to Apache Hive and SQL before diving into the differences.
Table of Contents
What is Apache Hive?

Apache Hive was developed by Facebook to analyze structured data. Apache Hive is built on top of the Hadoop framework. It allows you to bypass the requirements of the old approach of jotting down complex MapReduce programs. Apache Hive supports User-Defined Functions (UDF), Data Definition Language (DDL), and Data Manipulation Language (DML). The UDFs are primarily used for chalking out tasks like Data Filtering and Data Cleansing.
Here are a few salient features of Apache Hive that make it an indispensable tool in the market:
- Apache Hive is scalable and fast.
- Apache Hive was developed to focus on managing and querying only structured data stored across tables.
- It supports four file formats: RCFILE (Record Columnar File), SEQUENCEFILE, ORC, and TEXT FILE.
- For simple and fast data retrieval, Apache Hive supports buckets and partitioning.
- Apache Hive uses directory structures to partition data which helps improve the performance of specific queries. Directory structures are used because Hadoop’s programming works on flat files.
Depending on the size of the Hadoop Data Nodes, Hive can operate in two different modes:
- MapReduce Mode: This is Apache Hive’s default mode. It can be leveraged when Hadoop operates with multiple data nodes, and the data is distributed across these different nodes. It comes in handy when a user has to deal with massive data sets.
- Local Mode: Apache Hive’s Local Mode can be used if Hadoop was installed under the pseudo mode which means it only houses one data node. If the data size is smaller and limited to a single local machine then the Local Mode can come in handy. It can also be put to use when users expect faster processing because the local machine contains smaller datasets.
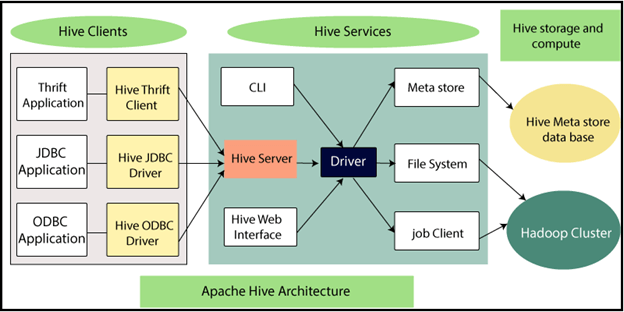
Working of Apache Hive

Here are the steps involved in the working of Apache Hive that can provide you a holistic view of the data flow:
- Step 1: First, the Data Analyst executes a query on the User Interface (UI). Then, the driver interacts with the query compiler to retrieve the plan. This contains the metadata and the query execution process.
- Step 2: The driver then parses the query to check the requirements and see if the syntax matches the requirements.
- Step 3:The compiler comes up with the metadata or the job plan that needs to be executed. It communicates with the metastore to retrieve a metadata request. The metastore sends the metadata information back to the compiler.
- Step 4: The compiler conveys the execution plan to the driver. Once the driver receives the execution plan, it forwards it to the Execution Engine.
- Step 5: The Execution Engine (EE) processes the query by bridging Hadoop and Apache Hive. The job process is executed in MapReduce.
- Step 6: The Execution Engine sends the job to the JobTracker in the Name Node. The job will then be assigned to the DataTracker in the Data Node. The Execution Engine simultaneously executes metadata operations with the metastore.
- Step 7: The results are extracted from the Data Nodes and sent to the Execution Engine. From there the results are loaded back to the driver and the front end (UI).
Apache Hive Optimization Techniques
Apache Hive queries can be optimized by Data Analysts using the following techniques that ensure they run faster in their clusters:
- You could divide the table sets into more manageable parts through bucketing.
- You can partition your data to reduce read time within your directory.
- You can create a separate index table that serves as a quick reference to the original table.
- You can improve filters, aggregations, scans, and joins by vectorizing your queries. To do this, you need to perform these functions in batches of 1024 rows, instead of one at a time.
- You can use appropriate file formats such as the Optimized Row Columnar (ORC) to boost query performance. ORC can reduce the data size by up to 75 percent.
What is SQL?
SQL is designed for managing the data in a Relational Database Management System (RDBMS) based on tuple relational calculus and relational algebra. You need to install and set up a database first to perform SQL queries.
SQL is divided into several language elements such as:
- Predicates: The predicates specify the conditions that can be evaluated to SQL three-valued logic (3VL) or Boolean truth values. They can also be used to limit the effects of queries and statements or to modify the program flow.
- Expressions: This can produce either table consisting of rows and columns of data or scalar values.
- Clauses: These are constituent components of statements and queries.
- Queries: Queries can help you retrieve the data based on specific criteria, and is an important part of SQL.
- Statements: These may have a persistent effect on data and schema, or may be involved in controlling connections, transactions, sessions, program flow, or diagnostics.
With Hevo, you can seamlessly integrate data from multiple sources into any data warehouse, ensuring your organization has a unified view of its data assets.
Why Use Hevo for Data Warehouse Integration?
- Broad Source and Destination Support: Connect to over 150+ sources, including databases, SaaS applications, and more, and load data into your preferred data warehouse.
- Real-Time Data Sync: Keep your data warehouse up-to-date with real-time data flow, ensuring your analytics are always based on the latest information.
- No-Code Platform: With Hevo’s user-friendly interface, you can easily set up and manage your data pipeline without any technical expertise.
Start for free now!
Get Started with Hevo for FreeHive vs SQL
Now that you have seen the basics of Apache Hive and SQL, you can get around to Hive vs SQL. Based on the following 5 factors, you can make an educated decision as to which one suits you best:
Language
Apache Hive uses a query language for its operations known as HiveQL. HiveQL is pretty similar to SQL and is highly scalable. SQL supports 5 key data types: Integral, Floating-Point, Binary Strings and Text, Fixed-Point, and Temporal. On the other hand, HiveQL supports 9 data types: Boolean, Floating-Point, Fixed-Point, Temporal, Integral, Text and Binary Strings, Map, Array, and Struct. SQL doesn’t support MapReduce but HiveQL does. The Views in SQL can be updated, unlike HiveQL.
Purpose
Apache Hive is a preferable choice for batch processing, while SQL is more ideal for straightforward business demands for data analysis.
Data Analysis
Apache Hive has been developed to handle complicated data more effectively as compared to SQL. SQL is better suited for less complicated data sets that need frequent modification.
Training and Support Availability
Both SQL and Apache Hive are fairly easy to learn. Since Apache Hive’s language is similar to SQL, SQL professionals can find it very easy to master their skills while working on the Hadoop platform. Apache Hive offers comprehensive documentation for all the features and components. You can look up free resources like w3schools for SQL as far as support is considered.
Pricing
SQL is a free open-source tool whereas Apache Hive starts at $12 per month. It has a tailored pricing plan for each of its features and doesn’t provide a free trial version.
Hive plans start at $12 per month per user.
There is a 14-day free trial available.
SQL is a completely free open-source platform. SQL pricing, on the other hand, does not account for any setup or maintenance costs you might incur.
Conclusion
This article first gives an introduction to Apache Hive and SQL before diving into the 5 key factors that can be used for Hive vs SQL: Language, Purpose, Data Analysis, Training and Support Availability and Pricing. Extracting complex data from a diverse set of data sources can be a challenging task and you might need to deploy the services of a third-party tool to help you out. Learn more about Hive MySQL Replication.
Explore the key differences between Hadoop and SQL to understand which one is better suited for handling big data. Learn about their architecture, scalability, and use cases in the Hadoop vs SQL guide.
This is where Hevo saves the day! Hevo offers a faster way to move data from Databases or SaaS applications into your Data Warehouse to be visualized in a BI tool. It offers a No-code Data Pipeline that can automate your data transfer process, hence allowing you to focus on other aspects of your business like Analytics, Customer Management, etc.
Want to take Hevo for a ride? Sign Up for a free 14-day trial to streamline your data integration process.
FAQ
Are Hive and SQL the same?
No, Hive is not the same as SQL. Hive uses Hive Query Language (HQL), which is similar to SQL, to query and manage data in a Hadoop environment.
What is the main disadvantage of Hive?
Hive has high latency and is not suitable for real-time queries; it is optimized for batch processing of large datasets rather than quick responses.
What is the difference between SQL and HQL?
SQL is used for querying relational databases, while HQL (Hive Query Language) is used to query and manage data in Hive, focusing on Hadoop’s distributed architecture.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





