
Kyle Kirwan is the CEO and co-founder of Bigeye, the premier data observability platform. Bigeye gives observability for Data Engineering and science teams the tools they need to ensure their data is always fresh, accurate, and reliable. Previously, Kyle was the product manager of Uber's metadata tools team. There, he developed the first set of data pipelines used by product teams across the company to analyze A/B test outcomes.
Imagine you’re driving a car. You can see what’s happening on the road in front of you, but you have no idea what’s going on under the hood. It’s like driving blindly without any gauges or a dashboard to give you vital information. You don’t know how fast you’re going, how much fuel you have left, or if something is about to go wrong.
In the same way, data engineers who lack data observability are like drivers with a limited view of the road. They may be able to see what’s happening on the surface, but they have no way of knowing what’s going on beneath the hood, i.e., your data stack.
These half-sighted data engineers may be able to make some informed guesses, but without real-time insights into how their data is being used and by whom, they are at a disadvantage. Without a complete understanding of the inner workings of their data systems, they are unable to come up with the best possible strategies and decisions.
It is therefore essential to have the guiding compass of data observability so you can succeed while planning your data engineering.
Implement effective data models to enhance your data consistency and integrity.
What does Hevo provide:
- Extremely intuitive user interface: The UI eliminates the need for technical resources to set up and manage your data Pipelines. Hevo’s design approach goes beyond data Pipelines.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: Hevo has in-built integrations for 150+ data sources (with 60+ free sources) that can help you scale your data infrastructure as required.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Table of Contents
Maximizing Data Engineering Effectiveness Through Observability
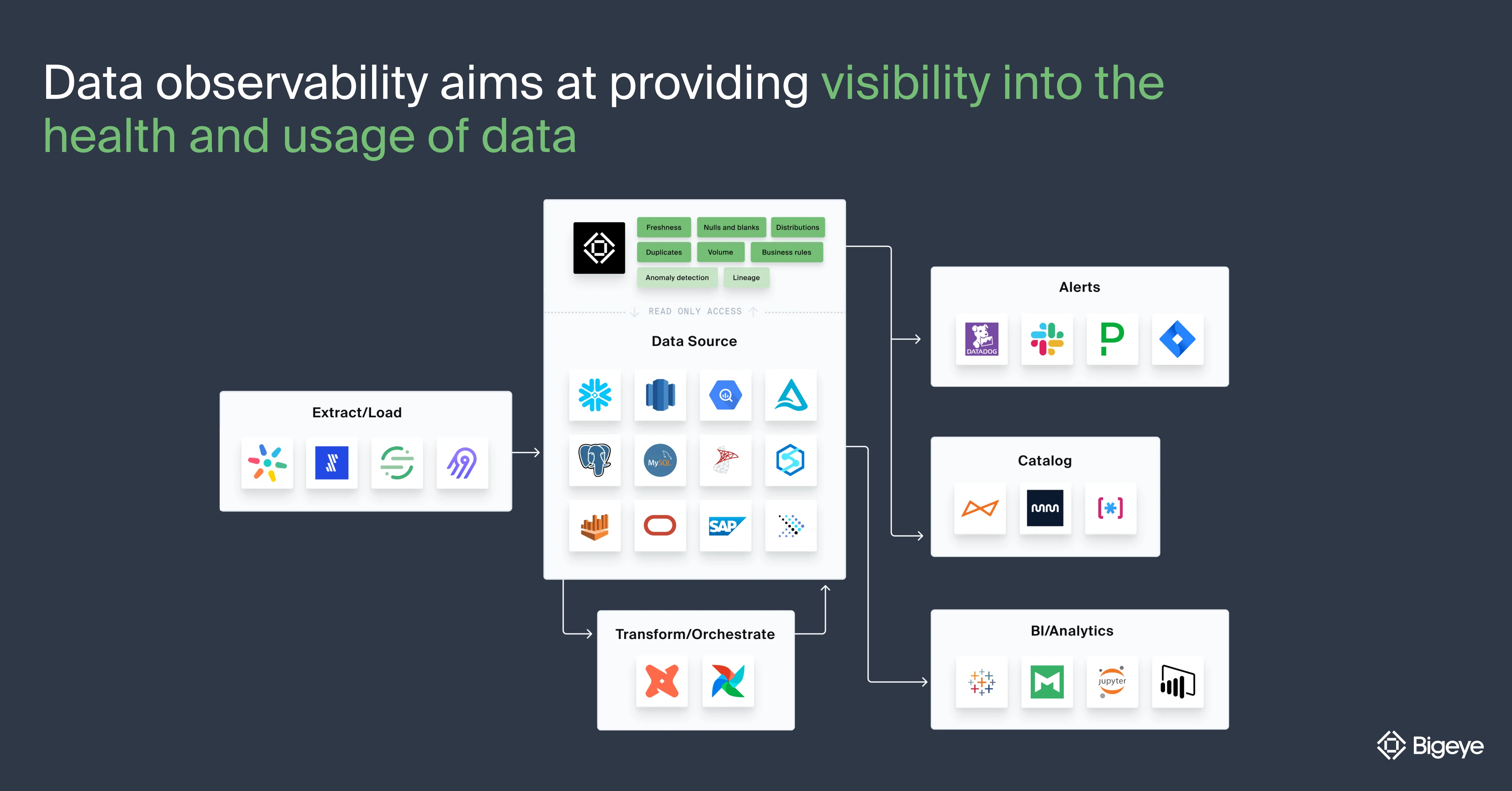
- Data observability for data engineering aims at providing visibility into the health and usage of data while, at the same time, minimizing “data downtime” (periods of time when data is partial, erroneous, missing, or otherwise inaccurate).
- Since it is possible for your data engineers to make certain changes upstream without realizing their downstream impact on data consumers, data observability gives them awareness into the end-to-end health of their data.
- Using automated logging and tracing information, data engineers can trace data problems to their point of origin in your system upstream and fix them quickly before they become major issues, thereby maximizing the value of data for your consumers.
- A data engineer works within an organization, often on data, product, engineering, or business intelligence teams, and is responsible for turning raw data into valuable insights that can be used and presented in service of organizational business goals.
- On a daily basis, data engineers are tasked with designing, building, testing, and optimizing data pipelines that pull in real-time data from a variety of sources. It’s a challenging role that requires a high level of technical expertise and attention to detail, as well as a deep understanding of the data they are working with.
- Performing these tasks requires data engineers to ensure the data they work with is accurate and reliable. This is where data observability comes into play.
Data observability refers to the ability to monitor, understand, and debug data pipelines in real time. It allows data engineers to identify and fix issues with data quality, performance, and efficiency, as well as understand the context and meaning of the data they are working with.
Observability for Data Engineering: Problems Solved
With data observability, data engineers can be confident that their pipelines are operating optimally and that the data they are working with is of the highest quality. Any data engineer who observes data can answer questions like:
- What is exactly happening with the data pipelines?
(Specifically) Are customer tables getting real-time data, or is it delayed or blocked? - How does the volume of data compare with expectations? Do any data duplicates exist?
(Specifically) Are duplicate shopping cart transactions messing up your profit and loss calculations? - Is the data behaving within the ranges that we expect it to, or are there lots of anomalies and errors happening?
(Specifically) Was your massive, sudden decrease in sales just a data problem or a real issue?

Essential Practices to be Implemented by Data Engineers
If you’re already monitoring data, you may be ready to take the next step toward data observability: the practice of gaining real-time visibility into the data flow, performance, and context. To transition from data monitoring to data observability, your data engineers should focus on implementing the following practices:
- Define your observability goals: Define what you want to achieve with data observability, what specific data issues do you want to address, and how it aligns with your overall business goals.
- Implement real-time monitoring: Decide which key data sources and business terms should be monitored in real-time. Identify and prioritize your data observability efforts for these sources and monitor their data pipelines in real time, including logging, alerting, and dashboards.
- Collect and centralize data: Collect data from all relevant data sources and centralize it in a single location for easy access and analysis.
A single source of truth is needed to support all of the many purposes and evolutions of the use of the data for observability that an enterprise needs as it matures its observability capabilities.
Marc Hornbeek, CEO and Principal Consultant, Engineering DevOps Consulting.
- Use metadata and context: Enhance data observability by adding metadata and context to data, including information about the source, format, and purpose of the data to quickly pinpoint the root cause.
- Schedule data profiling runs and set up alerts: Choose how frequently you want to profile your data. Data profiling helps identify anomalies, apply new business terms, enforce data quality rules, and check data structure. By setting up alerts, you can be notified of any issues that arise during the profiling process.
- Continuously test and optimize: Improve anomaly detection AI and regularly test and optimize data pipelines to ensure that they are operating at their best.
While some parts of data observability can be achieved manually via spreadsheets, logs, and CRMs, many organizations look to automate data observability by integrating tools like Bigeye that can send alerts and automate the process.
As part of such data observability initiatives, the primary focus isn’t just about ensuring healthy data and detecting broken data immediately. It is actually about fostering a data-driven culture throughout the organization, especially among data scientists, engineers, and business users who depend on reliable data to succeed.
By providing transparency and real-time insights into the data systems, data observability for data engineering can foster better communication, improve collaboration, and increase trust in the data. This ultimately leads to more efficient and effective data-driven strategies and greater success in decision-making.
The Role of Data Observability in Ensuring Data Pipeline Health
A data pipeline is never immune to errors and inaccuracies. Issues such as slow data processing, bottlenecks in the flow of data, or conflicts with data matching can always impact the integrity of your data.
Within every functional data pipeline is a series of steps that data engineers use to move data from its point of ingestion to its intended destination. Raw data is collected from various sources and is transformed into structured data that can be used for operations and analysis.
These transformations can involve multiple steps, all of which are part of the pipeline. There can be dozens, if not hundreds, of different data pipelines in organizations, and each pipeline may require a few to dozens of steps.
Having data observability for your data pipelines is like having a vital heartbeat monitor for your data pipeline's well-being.
Through close monitoring of data as it flows through the pipeline, data observability can identify, prevent, and resolve any data-related issues that may arise. This helps optimize system performance, particularly when dealing with large volumes of data that can slow down traditional systems.
Data observability tracks and compares numerous pipeline events and highlights significant inconsistencies. By focusing on these discrepancies, data managers can identify problems in the system that may affect the flow and quality of data in the pipeline. This lets them find potential issues before they become serious, ensuring that the pipeline stays operational and avoiding costly downtime.
When a team needs to map the lineage of data to upstream tables, data observability can do that. When a team needs to map the lineage of data downstream to analytics and machine learning applications, data observability can help that team understand the total impact of any data problems.
In effect, with data observability, a data team can track exactly when, where, and why these issues arise, allowing them to take a systematic approach to addressing and resolving the problems.
Data Observability for Data Engineering Is the Key to Unlock Better Data Quality
Most businesses aren’t founded with data quality as a top priority. As time goes on, datasets grow more complex, and data engineers often find themselves at the receiving end of bad or thoughtless data governance practices.
For data engineers, data quality assessment becomes a top priority.
Common Data Quality Assessment Errors
- Outdated data – If data isn’t revised over time, it can grow outdated and cause errors.
- Manual errors – Typing errors, misspellings, or misplacements can create bad or broken data causing problems for downstream data consumers.
- Unclear metadata – If data fields are ambiguous, incorrect data might get entered and stored.
- Data duplications – Often, multiple records that belong to the same data are ingested into data pipelines causing redundancy.
- Incomplete data – Blank spaces and empty fields can disrupt datasets, and cause further blank fields in any dependent data fields.
- Data inconsistency – Inconsistent formats and patterns that aren’t standardized can also create misunderstandings among users.
Most of the time, these errors are not the data engineers’ fault. But unfortunately, all data pipelines experience failures at some point. It’s not a question of “if,” but rather “when.”
In the midst of such chaos, there is always a need for data engineers to provide accurate and reliable data at all times for business operations. Data scientists need completeness and accuracy in data to build machine learning models or generate business insights. Data analysts are dependent on clean and structured data for easy analysis. Business users need relevant data to augment their decisions.
Effectively, every data consumer relies on high-quality data to run their operations.
And thus, data observability plays a crucial role by enabling data engineers to detect and prevent data corruption and improve data accuracy. Any organization that prioritizes investing in data analytics, machine learning, automation, and data observability will foster trust with their teams and customers, be able to drive the business forward, and extract more value from their data.
Benefits of Observability for Data Engineering
- Decreasing impacts from data issues: Data observability for data engineering can help you understand and resolve issues faster, ideally before reaching another teammate or, worse, a customer. Data outages are always possible, but with observability, they are less likely and their impacts are less catastrophic.
- Less firefighting: Data engineers spend way less time-fighting data outages and going into reactive problem-solving mode. They get their time back to build things and focus on the core business of data science and engineering.
- Increasing trust: With super accurate, highly valuable data, all stakeholders can trust data teams more. When business teams can assume data is accurate and make decisions accordingly, all teams can breathe more easily.
- Enhancing data governance: Data observability can help enforce data governance policies and ensure that data is being used and shared appropriately.

Final Words
- As organizations collect and process more data from a growing number of sources, their data environments become increasingly complex. This can make it difficult for your data engineers to understand and track data flows and processes and can make it challenging for them to identify and correct data issues.
- If left unaddressed, these data issues can have serious consequences, such as loss of trust in data, decreased productivity, and damage to your organization’s revenue and reputation.
- With data observability, your data engineering teams can monitor and track data flows and processes, identify and correct errors, detect and prevent data corruption, and improve the accuracy of their data. Testing, automation, alerting, and analysis are all key components of data observability that can help your data engineering teams ensure the quality and reliability of your data for everyone’s success.
- It’s like having dashboard gauges in a car to tell you how you’re doing—you can feel confident that you have all the information you need to succeed.
Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines. You can also check out the unbeatable pricing, which will help you choose the right plan for your business needs.
Frequently Asked Questions
1. What are the pillars of data observability?
The pillars of data observability typically include data quality, data lineage, data monitoring, and data performance. These pillars help ensure that data is accurate, traceable, and reliable for decision-making.
2. What is observability in data engineering?
Observability in data engineering refers to the ability to monitor and understand the state of data systems. It involves tracking data flows, identifying issues, and ensuring that data pipelines function as expected.
3. What is KPI in observability?
KPI (Key Performance Indicator) in observability is a measurable value that indicates how well a data system is performing. KPIs help teams assess the health of their data pipelines and make informed decisions for improvements.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





