

 Key Takeaways
Key TakeawaysIntegrating Azure MySQL with Databricks lets you run advanced analytics and ML on your live transactional data. Two streamlined approaches:
- Configure Azure MySQL source: whitelist IPs, enable binlogs if needed, then enter host, port & credentials in the pipeline UI.
- Configure Databricks destination: supply your workspace URL, HTTP path and access token.
- Result: continuous, incremental data sync with zero coding and automated schema mapping.
- Export: dump tables to CSV (via Workbench or mysqldump).
- Import: in Databricks UI click Add Data, upload CSV and create the table.
- Trade-offs: manual steps, no real-time updates, higher risk of errors.
Easily move your data from Azure MySQL To Databricks to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
With software supported in the cloud, many companies prefer to store their on-premise data on a database management service such as Azure MySQL. Integrating this data with a cloud analytics platform like Databricks can enable organizations to produce efficient results through data modeling.
Migrating data from Azure MySQL to Databricks can help you make decisions that scale your business. This article will discuss two of the most prominent methods to load Azure MySQL to Databricks.
Table of Contents
Why Integrate Azure MySQL to Databricks?
- There are many reasons to consider integrating Azure MySQL with Databricks.
- It can enable your organization to perform machine learning modeling on data and generate visualizations and dashboards.
- Using this, you can decide what key performance indicators (KPIs) you should focus on to expand your business performance.
- Databricks support machine learning libraries like Hugging Face Transformers, enabling you to integrate pre-trained models and open-source libraries into your workflow.
Method 1: Migrate Azure MySQL to Databricks Using Hevo Data
Hevo Data, an Automated Data Pipeline, provides you with a hassle-free solution to connect Azure MySQL to Databricks within minutes with an easy-to-use no-code interface. Hevo is fully managed and completely automates the process of loading data from Azure MySQL to Databricks and enriching the data and transforming it into an analysis-ready form without having to write a single line of code.
Method 2: Sync Azure MySQL to Databricks Using CSV Import/Export
This method would be time-consuming and somewhat tedious to implement. Users will have to write custom codes to enable two processes, streaming data from Azure MySQL to Databricks. This method is suitable for users with a technical background.
Get Started with Hevo for Free!An Overview of Azure MySQL

- Azure MySQL is Microsoft’s fully managed database management service. It provides a cost-effective solution for managing a database with high availability and security at a 99% service level agreement (SLA).
- Azure MySQL allows you to automate updates and backups. It also provides an AI-powered optimization and monitoring system that can improve query speed.
- With Azure MySQL’s flexible server feature, you can build resilient and responsive applications.

An Overview of Databricks

- Databricks is an analytics platform that allows users to build, deploy, and maintain applications at scale. Databricks Data Intelligence Platform can securely integrate with your cloud storage account to deploy and manage applications.
- Databricks, when working as a data warehouse, provides 12 times better price/performance for SQL workloads with its AI-optimized query execution.
- It can enable you to generate useful insights from data to make better data-driven decisions. To compare the Azure ecosystem to Databricks, refer to Azure Data Factory vs. Databricks.

Methods to Load Data from Azure MySQL to Databricks
This section will discuss two of the most widely used methods for how to read Azure MySQL in Databricks.
Method 1: Migrate Azure MySQL to Databricks Using Hevo Data
Step 1.1: Configure Azure MySQL as Source
Prerequisites
- Your Azure MySQL database instance must be running. You can check for it by following these steps:
- You must log in to your Microsoft Azure Portal.
- You must confirm the Status field has the value Available in the Overview tab.

- You must have the MySQL version 5.7 or higher.
- If you choose Pipeline mode as Binlog, you must enable Binary Log replication.
- You must whitelist Hevo IP addresses.
- You can create a database user and grant the necessary privileges to the new user.
- You can retrieve the port number and hostname of the source instance.
- You must have the role of Team, Pipeline administrator, or Team collaborator in Hevo.
Setting up Azure MySQL as Your Source
After satisfying the prerequisites, you can configure Azure MySQL as a source.

You can follow the Azure MySQL Hevo Documentation to learn more about the steps involved.
Step 1.2: Configure Databricks as Destination
Prerequisites
- You must have an active Azure, GCP, or AWS account.
- You must have a Databricks workspace on your cloud service account.
- You must enable the IP address lists feature in your cloud provider.
- Get the URL of your Databricks workspace. It will be in the format https://<deployment name>.cloud.databricks.com.
- You must create a Databricks cluster or a Databricks SQL warehouse.
- You must obtain the Databricks credentials, which include the database port number, hostname, and HTTP path.
- You must have the Personal Access Token (PAT).
- You must have the Team Collaborator role or any administrative role apart from Billing Administrator in Hevo.
Setting up Databricks as Your Destination
After satisfying all the prerequisites, you can set up Databricks as a destination in the data pipeline.

To know more about the steps involved in this section, you can refer to Hevo Documentation on Databricks.
That’s it, literally! You have connected Azure MySQL to Databricks in just 2 steps. These were just the inputs required from your end. Now, everything will be taken care of by Hevo. It will automatically replicate new and updated data from Azure MySQL to Databricks.
Key Features of Hevo Data
- Data Transformation: Hevo Data provides you the ability to transform your data for analysis with a simple Python-based drag-and-drop data transformation technique.
- Automated Schema Mapping: Hevo Data automatically arranges the destination schema to match the incoming data. It also lets you choose between Full and Incremental Mapping.
- Incremental Data Load: It ensures proper utilization of bandwidth both on the source and the destination by allowing real-time data transfer of the modified data.
With a versatile set of features, Hevo Data is one of the best tools for exporting data from Azure MySQL to Databricks files.

Method 2: Sync Azure MySQL to Databricks Using CSV Import/Export
Are you wondering how to insert Azure MySQL data into Databricks table in an alternate way? This section will help you move data from Azure MySQL to Databricks using CSV file transfer.
Step 2.1: Exporting Data from Azure MySQL
Before starting the steps, you must ensure the prerequisites are satisfied.
Prerequisites
- You must have an Azure Database instance for MySQL. If you cannot access it, refer to the Azure Database instance for MySQL.
- You must have MySQL Workbench.
Export Data from Azure MySQL
After satisfying the prerequisites, you can follow the steps here:
- You can create a database on the Azure Database for MySQL flexible server instance.
- You can determine when to use the import/export techniques.
- Follow these steps to export the files using the export wizard:

- You can right-click on the table that you want to export.
- Select columns, rows offset, and count by clicking on Table Data Export Wizard.
- You can now select Next on the Select data for export pane. Select the file path, use CSV as the data format, and mention any field you want.
- You must select Next on the Select output file location pane.
- Finally, you can click Next on the Export data pane.
To learn more about the steps, follow migrate Azure Database for MySQL.
Step 2.2: Importing Data into Databricks
You can quickly load data to Databricks using file upload. Follow the steps to do so:
- Select + New and click on Add data on your Databricks web console.
- After doing so, you can upload a file to Databricks by selecting the CSV file you exported in the previous step.
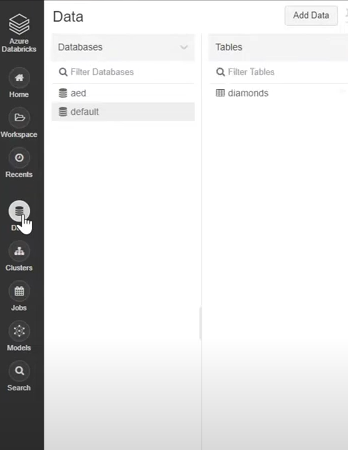
To know more about uploading files to Databricks, refer to load data using add data UI.
Limitations of Using CSV Import/Export Method
The CSV Import/Export Method is an efficient way to convert Azure MySQL to Databricks table, but there are some limitations associated with this method.
- Lack of Automation: The CSV Import/Export method lacks automation. It might become time-consuming because you must manually load data from Azure MySQL to Databricks.
- Lack of Real-time Data Integration: This method doesn’t automatically account for the new information added to the source. You must look out for updates and repeat the data transfer process.
- Increase in Errors: You must continuously monitor the data movement from source to destination. Otherwise, it can increase the chances of encountering errors or data inconsistency.
Use Cases of Loading Data from Azure MySQL to Databricks
- Integrating Azure MySQL to Databricks can enable you to perform advanced analysis on your data to generate valuable insights.
- Databricks offers users high availability, security, and governance. Its data recovery features enable users to retrieve data without worrying about data loss.
- Using the Databricks tools to automate, version, schedule, and deploy code and production resources can simplify data monitoring and operations.
Here are some other migrations that you may need:
Summary
- This article addresses the Azure MySQL to Databricks data migration process using two widely used methods.
- Both methods effectively transfer data from Azure MySQL to Databricks, but the second method has some limitations.
- To overcome the limitations, you can use Hevo Data, which provides an easy-to-use user interface to make your data integration journey easier.
- With over 150+ source connectors, you can quickly move data without technical knowledge.
Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines. You can also check out the unbeatable pricing, which will help you choose the right plan for your business needs.
Frequently Asked Questions (FAQs)
1. What is Azure Databricks?
Azure Databricks is one of the most widely used big data analytics platforms that
enables users to have a unified workspace, higher availability, security, and more. Its
Apache Spark integration allows you to perform data processing and analytics tasks at scale quickly.
2. How do I export my Azure MySQL database?
You can export your Azure MySQL database using tools like mysqldump or Azure’s
export options in the portal. This will generate an SQL file of your database.
3. Can we use SQL in Databricks?
Yes, Databricks supports SQL for querying and analyzing data. You can write SQL commands in Databricks notebooks.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





