




Unlock the full potential of your AWS DocumentDB data by integrating it seamlessly with Redshift. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
AWS DocumentDB is a document database that offers SQL querying of large datasets with MongoDB compatibility. Being a document database, it facilitates faster query performance, easy replication support, and a dynamic schema.
However, it does not support complex joins and stores data in document format, which is less organized than relational databases. You can integrate DocumentDB with relational databases like Amazon Redshift to overcome these limitations. It supports complex joins, columnar storage, and massively parallel processing capabilities for optimized query performance.
This article explains four methods for data integration from AWS DocumentDB to Redshift for faster and more complex data analytics.
Table of Contents
Why Integrate AWS DocumentDB to Redshift?
You should migrate data from AWS DocumentDB to Redshift for several reasons, such as:
- AWS DocumentDB is a document database, whereas Redshift is a relational database management system (RDBMS). RDBMS stores the data in a more organized format in the form of rows and columns, whereas document database stores data in the form of documents. Also, a relational database supports complex joins for advanced analytics, which is not supported in document databases.
- You can use Redshift to process large volumes of data through its massively parallel processing capabilities, which are not provided by DocumentDB.
- Redshift facilitates columnar data storage format, which helps with better data compression and faster query performance.
AWS DocumentDB Overview
AWS DocumentDB is a managed JSON document database service offered by Amazon Web Services. It is MongoDB compatible and supports the 3.6, 4.0, and 5.0 versions, allowing you to integrate easily with MongoDB drivers and applications. DocumentDB provides scalability up to the petabyte level, which helps you handle massive amounts of data efficiently. Further, it also provides high data security because of its authorization and encryption features. Additionally, DocumentDB integrates with Amazon SageMaker to help you develop applications based on generative artificial intelligence and machine learning functionalities.
Say goodbye to the hassle of manually connecting Redshift. Embrace Hevo’s user-friendly, no-code platform to streamline your data migration effortlessly.
Choose Hevo to:
- Access 150+(60 free sources) connectors, including AWS DocumentDB and Redshift.
- Ensure data accuracy with built-in data validation and error handling.
- Eliminate the need for manual schema mapping with the auto-mapping feature.
Don’t just take our word for it—try Hevo and discover how Hevo has helped industry leaders like Whatfix connect Redshift seamlessly and why they say,” We’re extremely happy to have Hevo on our side.”
Move PostgreSQL Data for FreeRedshift Overview
Redshift is a cloud-based data warehouse solution of Amazon Web Services (AWS). It is a fully managed service that reduces your responsibility for infrastructure management. Redshift offers high scalability up to the petabyte level and uses massively parallel processing technology to optimize performance. Redshift’s architecture also allows it to store data in columnar format for efficient data storage. Further, you can use simple SQL commands with the Redshift ML to build, deploy, and execute machine learning models within the data warehouse. This can help you with predictive analysis in fraud detection, risks, and customer churn rates.
What are the Ways to Migrate Data from DocumentDB to Redshift?
- Method 1: Using Hevo Data to Integrate AWS DocumentDB to Redshift
- Method 2: Using AWS Cloud to Integrate AWS DocumentDB to Redshift
- Method 3: Using Pymongo to Integrate AWS DocumentDB to Redshift
- Method 4: Using CSV File to Load Data from AWS DocumentDB to Redshift
Method 1: Using Hevo to Effortlessly and Quickly Migrate the Data
Step 1: Configure AWS DocumentDB as your Source.
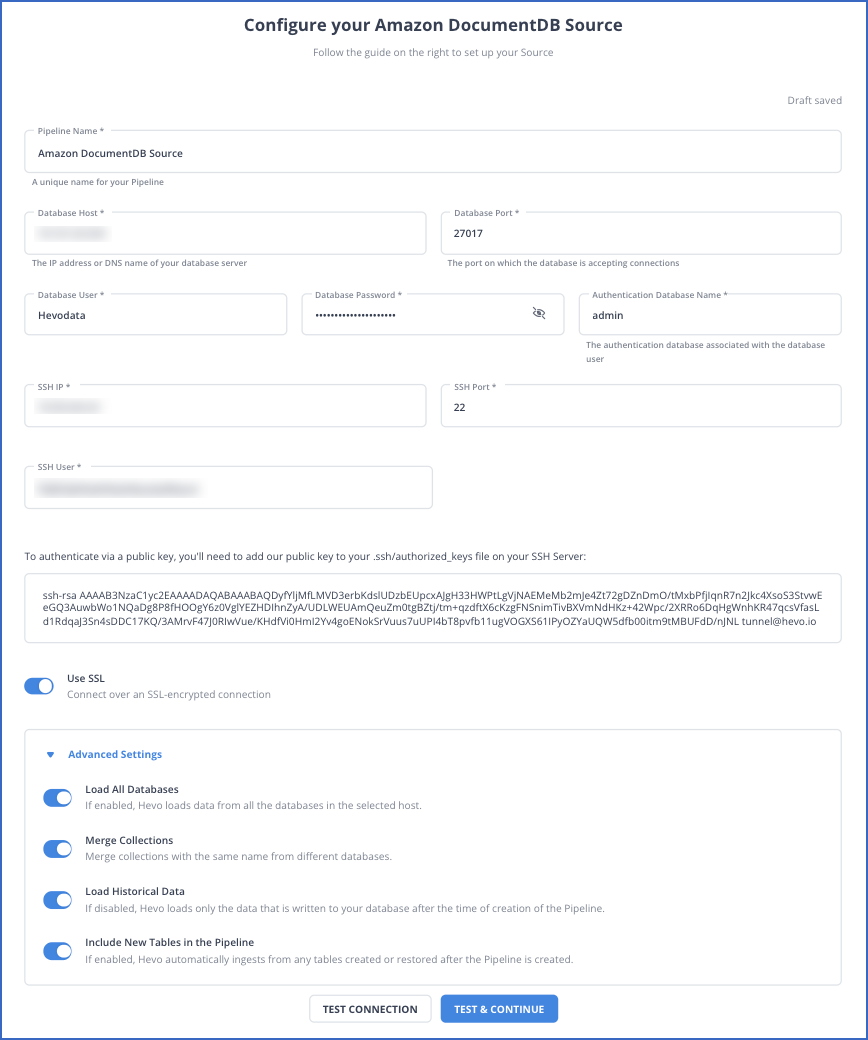
For more information on the configuration of Amazon DocumnetDB as a source, refer to the Hevo documentation.
Step 2: Configure Redshift as your Destination
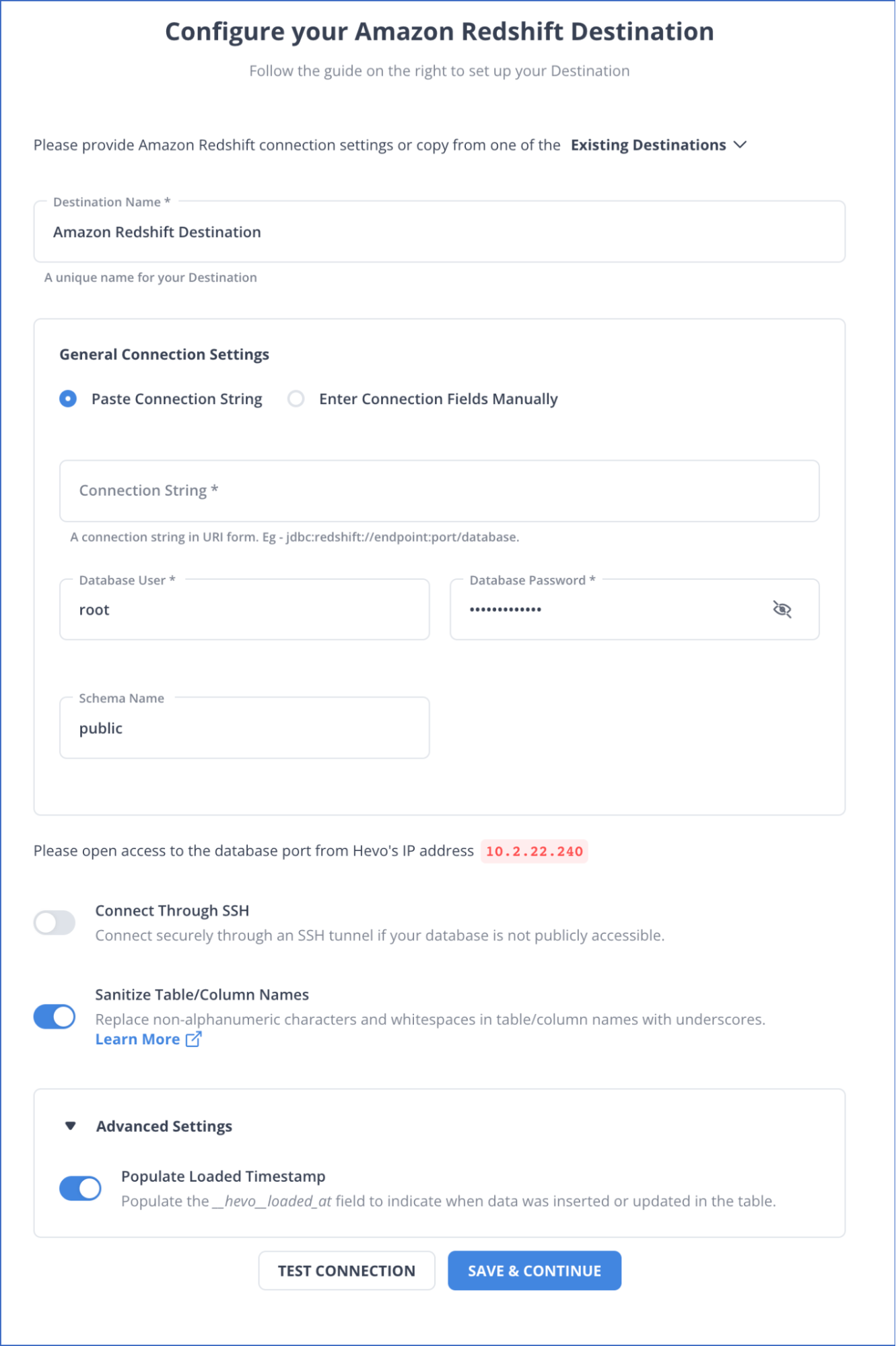
For more information on the configuration of Redshift as a destination, refer to the Hevo documentation.
Method 2: Using AWS Cloud to Integrate AWS DocumentDB to Redshift
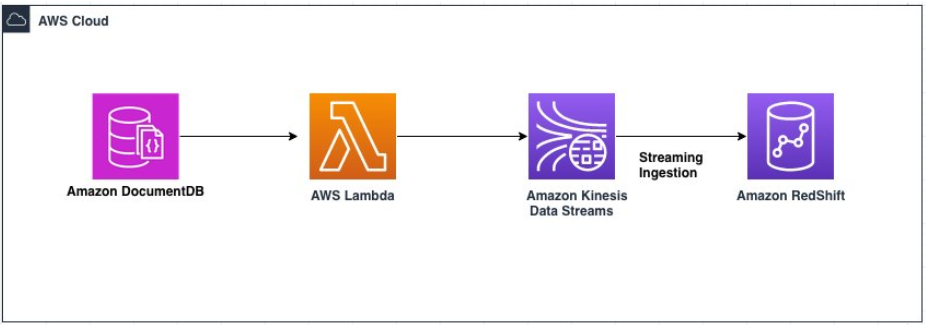
You can use AWS Cloud to integrate DocumentDB to Redshift by following the below steps. To do this, first, ensure the deployment of all the CloudFormation resources.
Step 1: Connect to the Amazon DocumentDB cluster using AWS Cloud9
- From the AWS Cloud9 Console, launch the AWS Cloud9 environment DocDBStreaming.
- You should run the following commands to install the essential packages and the Amazon DocumentDB Certificate Authority (CA) certificate key:
# Setting up mongo 4.0 repo
echo -e "[mongodb-org-4.0] \nname=MongoDB Repository\nbaseurl=https://repo.mongodb.org/yum/amazon/2013.03/mongodb-org/4.0/x86_64/\ngpgcheck=1 \nenabled=1\ngpgkey=https://www.mongodb.org/static/pgp/server-4.0.asc" | sudo tee/etc/yum.repos.d/mongodb-org-4.0.repo
# Installing packages
sudo yum -y update
sudo yum -y install mongodb-org-shell
# Downloading the SSL file and the loader
wget https://truststore.pki.rds.amazonaws.com/global/global-bundle.pem- Now, to connect to the Amazon DocumentDB cluster, follow these steps:
- First, navigate to Secrets Manager Console to access the credentials for your DocumentDB cluster and search for the secret named secretDocDBAdminUser-<randomly generated string>.
- Navigate to the Amazon DocumentDB Console and select Clusters in the Navigation Pane.
- Select the cluster transactcluster.
- From the Connectivity & Security section, copy the Mongo shell command and then add the username and password from the Secrets Manager as mentioned earlier.
# Connect to the cluster
mongo --ssl --host <cluster endpoint>:27017 --sslCAFile global-bundle.pem --username <user_name> --password <insertYourPassword>Step 2: Create the Database and Collection and Enable Change Streams
You can enable the change streams at cluster, database, and collection levels. Here, it is enabled at the collection level. The below mentioned commands can help you to create the database named database1 and the collection named collection1. You can capture transactions and enable the change streams for this collection:
# Create database
use database1
# Create Collection
db.createCollection("collection1")
# Enable change streams for collection
db.adminCommand({modifyChangeStreams: 1,
database: "database1",
collection: "colllection1",
enable: true});
# Insert a record into the new Collection
db.collection1.insertOne({“parameter1” : “value1”, “parameter2” : “value2”, “parameter3” : “value3”});Step 3: Configure a trigger for the Lambda function
- You should create a trigger for the Lambda function to be invoked whenever there is a change in the collection for real-time data capturing:
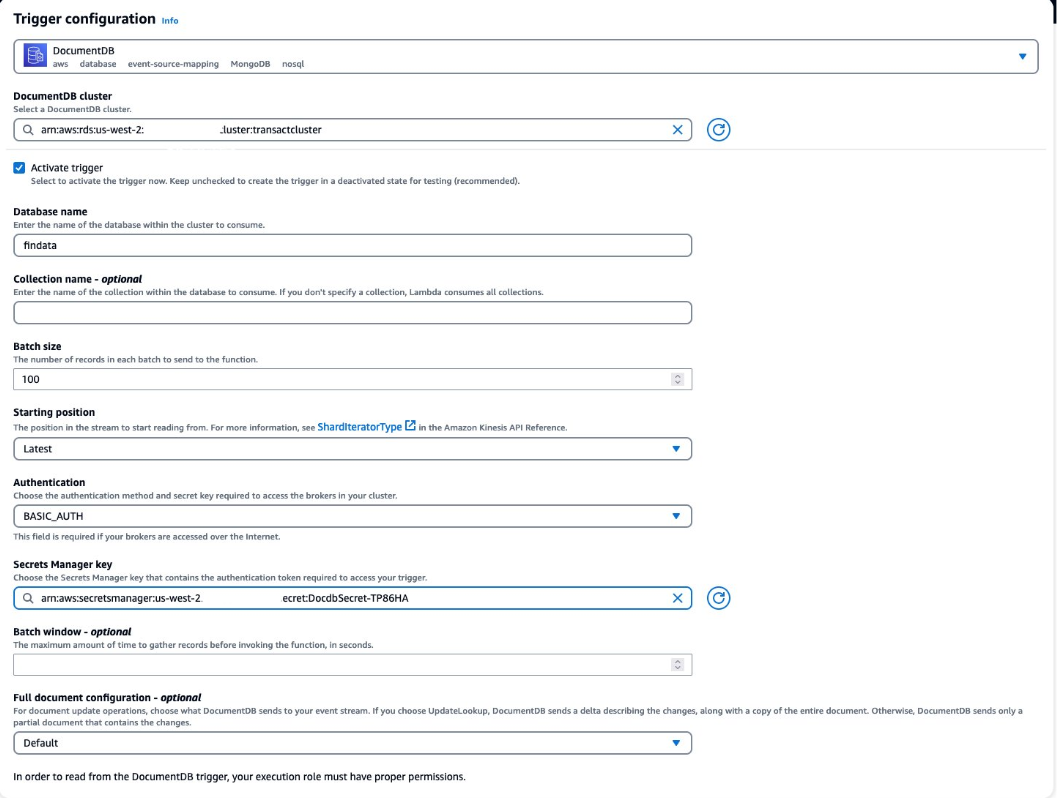
- Choose Add and wait for the event source mapping to be created and the state to change to Enabled. This can take a few minutes.
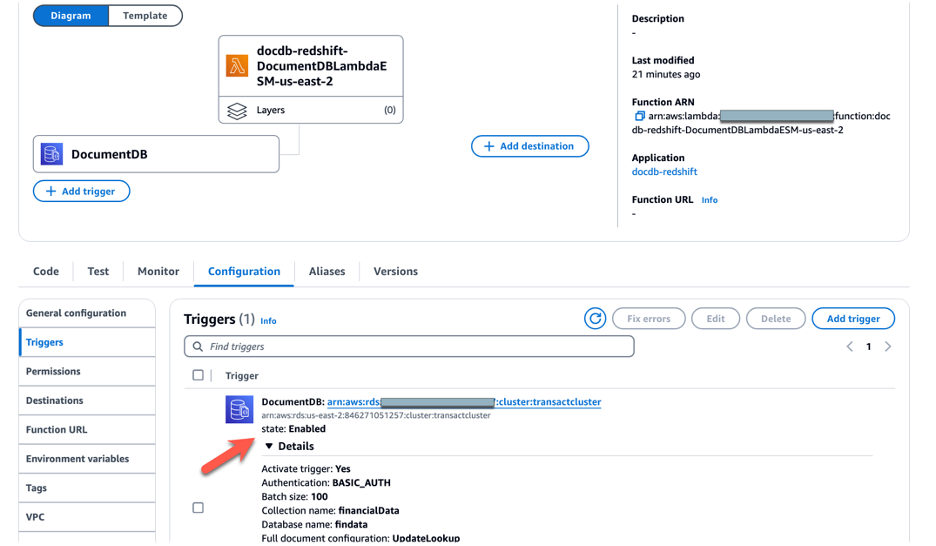
Step 4: Set up Amazon Redshift streaming ingestion
- From the left navigation pane on the Amazon Redshift Console, choose Query Editor v2.
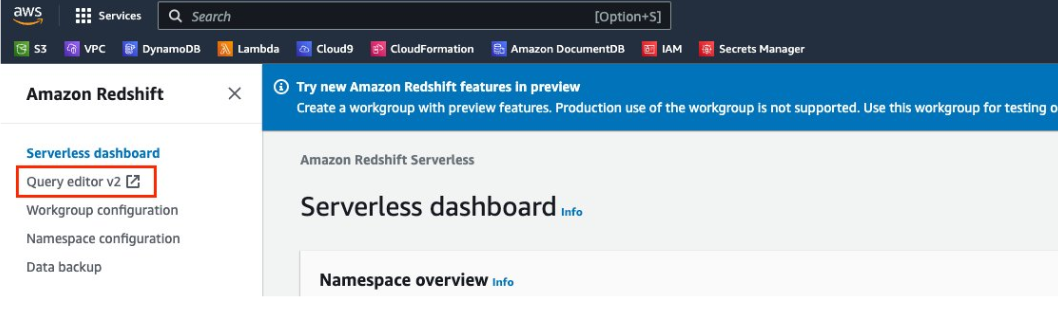
- Choose the workgroup Serverless:work-group-streamingblog in the left pane in the query editor, and toggle to use the database user name and password.
- Then, navigate to the secrets manager and use the username and password for the secret named secretRedshiftAdminUser-<randomly generated string>.
- Run the following command to create an external schema. This will map the data from Kinesis Data Streams to a Redshift object:
CREATE EXTERNAL SCHEMA database1analysis FROM KINESIS
IAM_ROLE default;- You can run the following command to create the materialized view. It is set to auto-refresh and will be refreshed whenever data arrives in the stream.
CREATE MATERIALIZED VIEW database1_extract sortkey(1) AUTO REFRESH YES AS
SELECT
refresh_time,
approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
json_parse(kinesis_data) as payload
FROM database1analysis.docdbstream
WHERE CAN_JSON_PARSE(kinesis_data);- You can also create a view on top of the materialized view of database1_extract for near-real-time analysis of the collection1. This approach allows you to integrate data from multiple sources easily.
- Then, you can query the near-real-time view to validate the transformation of raw data into columnar data. Use the following query to examine the structured data resulting after the transformation process:
Select * from "public"."database1_extract_view"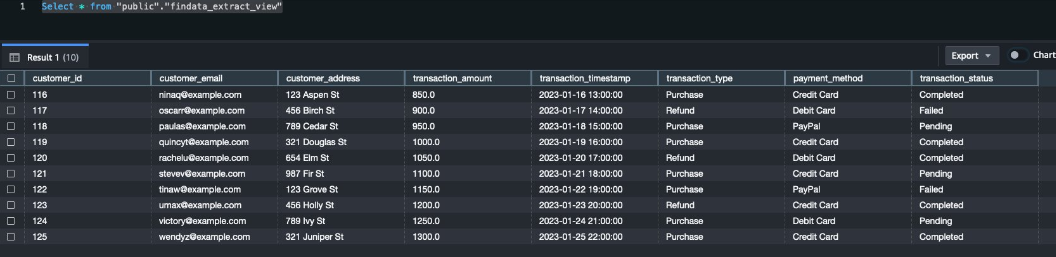
Limitations of Using AWS Cloud to Integrate AWS DocumentDB to Redshift
There are certain limitations of using AWS Cloud in order to load AWS DocumentDB to Redshift, such as:
- Inefficiency of Lambda Function: AWS Lambda cannot efficiently handle functions that require excessive processing, creating computational constraints.
- Limited Scalability: Kinesis has scalability constraints, which limit data streaming and data loading to Redshift.


Method 3: Using Pymongo to Integrate AWS DocumentDB to Redshift
Pymongo is a local Python driver for MongoDB, and DocumentDB is MongoDB-compatible. You can use the following steps to integrate AWS DocumentDB to Redshift using Pymongo.
Step 1: Connect to DocumentDB
- To connect to DocumentDB, first install Pymongo in your Python notebook using the following command:
pip install pymongo
- If you already have a connection with MongoDB, you just need to specify the host, port, username, and password and use the following command to establish a connection with DocumentDB.
import pymongo
import os
CURRENT_DIR = os.path.dirname(os.path.abspath(_ _ file _ _))
congif = {
'host': '<host>',
'post': 3000,
'username': <name-of-documentdb-user>
'password': <password-ofdocument-user>
'database': <name-of-database-we-want-to-connect>
}
connection_params = {
'host': config['host'],
'port': int(confid['port']),
'username': config.get('user',None),
'password': config.get('password', None),
'authSource': config['database'],
'ssl': True,
'ssl_ca_certs': os.path.join(*[CURRENT_DIR,'certs','rds-combined-ca-bundle-pem']),
'ssl_match_hostname': False,
'replicaset': congig.get('replica_set',None),
'readPreference': 'secondaryPreferred'
}
if not verify mode and use_ssl:
connection_params['ssl_cert_reqs'] = ssl.CERT_NONE
client = pymongo.MongoClient(**connection_params)Step 2: Extract Data from AWS DocumentDB
- To extract data from any DocumentDB database, you first need to connect to it in the DocumentDB cluster. For instance, you might want to extract data from the college database for student collection.
database name = 'college'
db = client[database name]- After connecting to the database, you need to connect to the collection from which you want the data (student in this case).
collection_name = 'student'
collection = db[collection_name]- You can use the following code to get data from the collection.
with collection.find(sort=[('id',pymongo.ASCENDING)])as cursor:
data=[]
for row in cursor:
data+=rowStep 3: Define a Schema
- Define a schema with keys you want to load to Redshift from DocumentDB.
schema = {
"columns":['_id','name','college']
}for row in data:
delete_keys=[]
for key in row:
if ket not in schema['columns'] #if key is not in schema columns add it to delete_keys
delete_keys.append(key)
for key in delete_keys: #remove all not required keys
del row[key]- For real-time data capturing, you can use the change stream method to get the data into Redshift. When you add, update, or delete a document in the DocumentDB cluster database, you are notified immediately. However, this method requires you to keep a constant eye on your database.
change_stream =
db[collection.name].watch(full_document='updateLookup')
#above will return you full document whenever some event occurs
with change_stream as cursor:
data = []
while cursor.alive:
change = cursor.try_next() #listing for other events
if change is not None:
operation_type = change.get('operationType')
#Get the full document from event
record_row = change.ger('fullDocument')
data += record_row
else:
#process the data we have recieved till now
for row in data:
detele_keys = []
for key in row:
if key not in schema['columns'] #if key is not in schema column add it to delete keys
delete_keys.append(key)
for key in delete_keys: # remove all not required keys
del row [key]You can then load this data to Redshift using psycopg2 to successfully integrate AWS DocumentDB to Redshift.
Limitations of Using Pymongo to Integrate AWS DocumentDB to Redshift
Pymongo is a native Python driver for MongoDB and possesses the limitations of MongoDB. Some of the disadvantages of using Pymongo to integrate AWS DocumentDB to Redshift are:
- Limited Joins: Joining documents in MongoDB can be difficult, and it also fails to support joins in relational databases. This can be a significant drawback while using Pymongo for AWS DocumentDB to Redshift integration.
- High Storage Memory: It has high storage memory because of data duplication and lack of support for joins. This leads to an increase in data redundancy as extra data storage consumes unnecessary space in the memory.
Method 4: Using CSV File to Load Data from AWS DocumentDB to Redshift
Step 1: Transfer AWS DcoumentDB Data to a CSV File
You can use the mongoexport tool to transfer AWS DocumentDB data to a CSV file in your native system with the help of the following code:
mongoexport --ssl \
--host="sample-cluster.node.us-east-1.docdb.amazonaws.com:27017" \
--collection=sample-collection \
--db=sample-database \
--out=sample-output-file \
--username=sample-user \
--password=abc0123 \
--sslCAFile global-bundle.pemStep 2: Loading Data from a CSV File to S3 Bucket
Follow the steps below to upload a CSV file to the Amazon S3 bucket.
Create a Bucket
- Sign in to the AWS Management Console and go to the Amazon S3 Console.
- Choose Create bucket and the AWS region where you want to create it.
- Enter a unique bucket name in the Create Bucket dialog box’s Bucket Name option.
- Choose the suggested defaults for the rest of the options and then choose Create bucket.
- On successfully creating an Amazon S3 bucket, the Console displays your empty bucket in the Buckets panel.
Create a Folder
- Choose the name of the new bucket.
- Click on the Create Folder button.
- Name the new folder as load.
Upload the CSV Files to the New Amazon S3 Bucket
- Choose the name of the data folder.
- In the Upload wizard, choose Add Files. Follow the Amazon S3 Console instructions to upload all of your CSV files.
- Choose Upload.
Step 3: Export Data from S3 Bucket to Redshift
After transferring the CSV file to the S3 bucket, you should use the COPY command to export the data in it to Redshift using the following code:
COPY table_name
FROM 'path_to_csv_in_s3'
credentials
'aws_access_key_id=YOUR_ACCESS_KEY;aws_secret_access_key=YOUR_ACCESS_SECRET_KEY'
CSV;Limitations of Using CSV File to Load Data from AWS DocumentDB to Redshift
- Limited Functionalities of CSV: CSV files only support basic data types such as numbers or dates, not complex data types like nested objects or images. They also do not provide data security mechanisms like access control or encryption, which can expose your data to potential cyber threats.
- Limitations of S3 bucket: The S3 bucket is owned by the AWS account in which it was created, and its ownership is not transferable to other accounts. Also, you cannot change the bucket’s name and the AWS region after setting it up. This can create discrepancies in seamless data integration, especially for new AWS users.
Use Cases of AWS DocumentDB to Redshift Integration
There are several use cases of integrating AWS DocumentDB with Redshift, including:
- Data Warehousing: You can use Redshift as a central repository to store data from multiple sources in a consistent format and retrieve it for reporting and analytics purposes.
- Real-time Analytics: Redshift uses massively parallel processing technology to speed up data processing. Thus, it can be used in your organization to perform real-time data analytics for better customer service.
- Business Intelligence: Redshift integrates with BI tools like Power BI, Tableau, and Looker to create interactive dashboards and reports. You can connect your BI tools directly to Amazon Redshift via JDBC or ODBC drivers to visualize your data for ease of understanding and better decision-making.
Conclusion
This blog provides you with an overview of AWS DocumentDB and Redshift Integration. It gives a detailed explanation of four methods of transferring data from DocumentDB to Redshift. While you can use any of these methods for AWS DocumentDB to Redshift data integration, using an automated platform such as Hevo is beneficial. The platform offers a zero code configuration, a vast library of connectors, and a simple interface to set up data pipelines.
Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also checkout our unbeatable pricing to choose the best plan for your organization.
FAQs
1. Where can you use Amazon DocumentDB?
The DocumentDB has a document model and can be used with dynamic datasets that require ad-hoc querying, indexing, and aggregations. It is used extensively for content management, personalization, catalogs, mobile and web applications, IoT, and profile management.
2. What are Amazon Redshift Clusters?
Clusters are groups of nodes, a collection of computing resources in Amazon Redshift. Each cluster has one or more databases and runs its own Redshift engine.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



