



Venturing into Data Science and deciding on a tool to use to solve a given problem can be challenging at times, especially when you have a wide array of choices. In this age of data transformation, where organizations are constantly seeking out ways to improve the day-to-day handling of data being produced and looking for methods to minimize the cost of having these operations, it has become imperative to handle such data transformations in the Cloud as it is a lot easier to manage and is also cost-efficient.
In this article, you will gain information about Google BigQuery Subquery. You will also gain a holistic understanding of Google BigQuery, its key features, SQL, Subqueries, and the different types of Subqueries supported by Google BigQuery. Read along to find out in-depth information about undergoing GoogleBigQuery Subquery.
Table of Contents
What is Google BigQuery?
Google BigQuery is a Cloud-based Data Warehouse that provides a Big Data Analytic Web Service for processing petabytes of data. It is intended for analyzing data on a large scale.
It consists of two distinct components: Storage and Query Processing. It employs the Dremel Query Engine to process queries and is built on the Colossus File System for storage. These two components are decoupled and can be scaled independently and on-demand.
Google BigQuery is fully managed by Cloud service providers. We don’t need to deploy any resources, such as discs or virtual machines. It is designed to process read-only data.
A fully managed No-code Data Pipeline platform like Hevo Data helps you integrate and load data from 150+ different sources (including 60+ free sources) to a Data Warehouse such as Google BigQuery or Destination of your choice in real-time in an effortless manner.
Let’s see some unbeatable features of Hevo Data:
- Fully Managed: Hevo Data is a fully managed service and is straightforward to set up.
- Schema Management: Hevo Data automatically maps the source schema to perform analysis without worrying about the changing schema.
- Real-Time: Hevo Data works on the batch as well as real-time data transfer so that your data is analysis-ready always.
- Live Support: With 24/5 support, Hevo provides customer-centric solutions to the business use case.
For further information about Google Bigquery, follow the Official Documentation.
Key Features of Google BigQuery
Some of the key features of Google BigQuery are as follows:
1) Scalable Architecture
BigQuery has a scalable architecture and offers a petabyte scalable system that users can scale up and down as per load.
2) Faster Processing
Being a scalable architecture, BigQuery executes petabytes of data within the stipulated time and is more rapid than many conventional systems. BigQuery allows users to run analysis over millions of rows without worrying about scalability.
3) Fully-Managed
BigQuery is a product of Google Cloud Platform, and thus it offers fully managed and serverless systems.
What is SQL?

SQL stands for Structured Query Language and executes queries against the database for data analytics. According to ANSI (American National Standards Institute), it is the standard language for relational database management systems.
With the help of SQL, you can:
- Create and Delete Database
- Create, Delete and Update Table
- Load/UnLoad data into Tables
- Set and Manage permissions on tables, procedures, and views
- And many more.
What are Subqueries?
A Subquery is an inner or nested query that users can use inside a SQL query or in a WHERE clause. The subquery specified will return the data used in the main query as a filter condition to retrieve the data from the main query.
Subqueries can be used with the SELECT, INSERT, UPDATE, and DELETE statements and the operators like =, <, >, >=, <=, IN, BETWEEN, etc.
To write the subquery, the user must follow some rules which are as follows:
- The Subqueries must be enclosed within parenthesis.
- A Subquery can have only one column in select.
- A subquery cannot use the ORDER BY command. However, a GROUP BY function can be used instead of the ORDER BY function.
- Subqueries that return more than one row can only be used with IN operator.
What is the Need to Use Subqueries?
The instances where Subqueries are used are as follows:
- There is a need to filter a table based on data from another table
- There is a need to refer a column from another table into the current table.



Prerequisites
- An active Google account with a subscription to Google Cloud Platform (GCP).
- Basic understanding of Google BigQuery.
- Understanding of basic SQL queries.
- Consider the following tables given below for the example purposes:
Products
| product_id | product_name | product_owner |
| P01 | PS4 | Sony |
| P02 | XBox | Microsoft |
| P03 | Nintendo | Nintendo |
Orders
| order_id | order_date | prodcut_id | order_qty |
| O1 | 2022-01-02 01:12:23 | P01 | 1 |
| O1 | 2022-01-02 01:12:23 | P02 | 1 |
| O2 | 2022-01-04 02:12:23 | P01 | 2 |
| O3 | 2022-01-06 06:12:23 | P03 | 2 |
Transactions
| transaction_id | order_id | transaction_date | transaction_amt_usd |
| T01 | O1 | 2022-01-02 01:12:23 | 800 |
| T02 | O2 | 2022-01-04 02:12:23 | 500 |
| T03 | O3 | 2022-01-06 06:12:23 | 1000 |
How to use Google BigQuery Subquery?
Google BigQuery uses ANSI SQL to query the data against the database, and hence it supports Subqueries within the main query. Let’s discuss the different types of subqueries that can be used in BigQuery:
- Google BigQuery Subquery: Expression Subqueries
- Google BigQuery Subquery: Table Subqueries
- Google BigQuery Subquery: Correlated Subqueries
1) Expression Subqueries
Expression Subqueries are those queries that return a single value and are used against expression. Expression subqueries can be correlated queries.
There are different types of Expression subqueries to look around:
A) Scalar Subqueries
The subqueries resulting in a single column and single row are called scalar subqueries. Scalar subqueries are often used with SELECT or WHERE clauses.
Using multiple columns in Scalar queries results in analysis error, and also, if subquery results into multiple rows, that also results in a runtime error. To understand more about the scalar subqueries, consider the following example –
Consider the table Products and Orders, below query that represent a scalar subquery example:
SELECT order_id, (SELECT product_name
FROM products
WHERE orders.product_id = product.product_id)
AS product_name
FROM orders;Output:
+---------------------------+
| order_id | product_name |
+---------------------------+
| O1 | PS4 |
| O1 | XBox |
| O2 | PS4 |
| O3 | Nintendo |
+---------------------------+B) EXISTS-based Subqueries
EXISTS-based subqueries return TRUE if the subquery returns one or more rows and FALSE if it produces zero rows. In Exists-based subqueries, users can use any number of columns as required, which will not affect the query result.
SELECT EXISTS(SELECT product_id
FROM products
WHERE product_owner = 'PS4') AS result;Output:
+--------+
| result |
+--------+
| TRUE |
+--------+C) IN-based Subqueries
IN-based subqueries return TRUE if the subquery returns the row and FALSE if it doesn’t return any value.
The value returned by IN-based subqueries must have a single column, and the data type of the returned value must be the same as the comparable value. Otherwise, it will throw an error.
SELECT "Nintendo" IN (SELECT product_name
FROM products) as result;Output:
+--------+
| result |
+--------+
| TRUE |
+--------+D) ARRAY Subqueries
ARRAY subqueries are the special case of expression subquery, and it returns ARRAY of values combined from different rows. If no rows are returned from the query, it returns an empty array.
SELECT ARRAY(SELECT product_id
FROM orders
WHERE order_qty = '1') as product_names
FROM orders LIMIT 1; Output:
+-----------------+
| product_names |
+-----------------+
| [P01, P02] |
+-----------------+[Source_Destination_Blockj]
2) Table Subqueries
The Table subqueries are the types where the main query treats the result of the subquery as a temporary table and uses that to fetch the value. This query can only be used with FROM clause.
SELECT product_name FROM (SELECT product_name
FROM products
WHERE product_owner IN ('Sony'))Output:
+----------------+
| product_name |
+----------------+
| PS4 |
+----------------+3) Correlated Subqueries
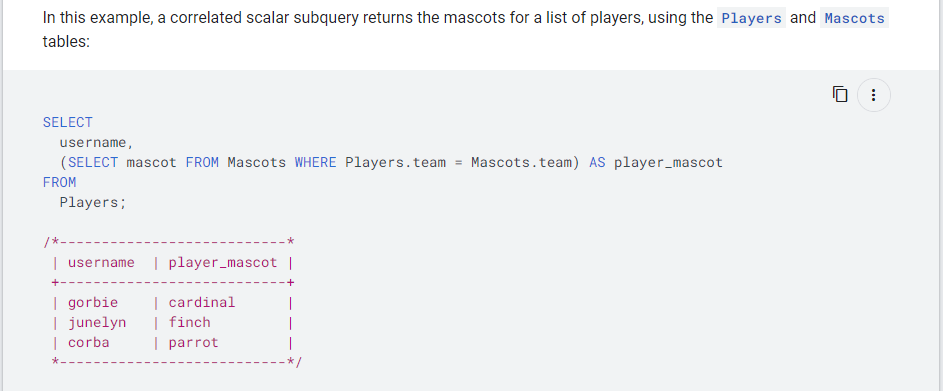
A Correlated subquery is another type of subquery that references a column from another table outside that subquery. Correlation prevents reusing of the subquery result.
SELECT product_name, (SELECT order_id
FROM orders
WHERE orders.product_id = 'P02') AS order_id
FROM products;Output:
+---------------------------+
| product_name | order_id |
+---------------------------+
| XBOX | O1 |
+---------------------------+Conclusion
In this article, you have learned about BigQuery SubQuery. This article also provided information on Google BigQuery, its key features, SQL, Subqueries, and the different types of subqueries used in Google BigQuery in detail. For further information on BigQuery JSON Extract, BigQuery Create View Command, BigQuery Partition Tables, you can visit the former links.
Hevo Data, a No-code Data Pipeline provides you with a consistent and reliable solution to manage data transfer between a variety of sources and a wide variety of Desired Destinations with a few clicks.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. Does BigQuery support Subqueries?
Yes, BigQuery supports subqueries, allowing you to nest queries within another query.
2. Is a subquery faster than a CTE?
It depends on the use case. Common Table Expressions (CTEs) can sometimes be more efficient, but subqueries might perform better in other cases. It varies based on query complexity.
3. What is the difference between a query and a subquery?
A query retrieves data, while a subquery is a query inside another query used to refine results or provide data for the outer query.

Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





