




Messengers and chatbots are an important part of a modern-day game plan for generating leads from your marketing efforts and converting them into revenue. There are several software-as-service offerings in this domain that help companies to quickly set up messengers without having to implement custom software on their own.
This post will deal with copying data from Intercom to Redshift, a very popular data warehouse service in the market. It starts with a brief introduction to Intercom and Redshift before diving into the two methods you can use to connect Intercom and Redshift.
Table of Contents
Introduction to Intercom

Intercom is a popular business messenger service that can be easily integrated into any website. Intercom helps in lead generation, lead conversion, and lead management. It supports automated workflows and conversations. It even allows visitors to execute various activities related to their customer journey like learn about order status, order confirmation, raise a support ticket, etc. right from the chatbox.
Even though Intercom provides its own dashboard and reporting facilities, it is quite natural for companies to import their generated lead data to their own data warehouse for analysis and decision-making. Having this data in their warehouse allows them to combine this with their already existing data and perform far deeper analysis.
Method 1: Using Hevo Data to Connect Intercom to Redshift
If you are looking to instantly move data from Intercom to Redshift, then this is a better and faster approach for free. Hevo can help you move Intercom data to Redshift on a point and click interface, without having to write any code for free.
Method 2: Using Intercom APIs to Connect Intercom to Redshift
Intercom provides a robust set of APIs that allow you to extract data programmatically. Next, you would need to clean this data and load it to Redshift. This would need you to invest in engineering bandwidth, who can build the setup from scratch.
Get Started wih Hevo for Free !Salient Features of Intercom
- Outbound Messages: You can also use mobile push, targeted email along with in-app messages to encourage customers to take action, or convert prospective leads to loyal customers. This feature helps you support and onboard your customers in your mobile app and on the web.
- Team Inbox: You can answer customer questions through a shared, collaborative, and highly customizable inbox. This Intercom feature lets you support your customers in a scalable and personal way.
- Product Tours: You can support and onboard customers while highlighting new features of Intercom with guided, adoption-driving tours.
- Help Center Articles: Intercom allows you to publish to a knowledge base to provide your customers with self-serve support. You can also automatically share articles in Messenger, or through conversations with teammates.
Introduction to Redshift

Amazon Redshift is one of the most widely used Cloud Data Warehouses in today’s marketplace. Amazon Redshift can integrate with your Data Lake with considerable ease and offer a 3x better price-performance compared to its competitors. Amazon Redshift allows you to combine and query exabytes of Semi-structured and Structured data across your operational database, Data Warehouse, and Data Lake using standard SQL.
Salient Features of Redshift
- Redshift ML: Redshift ML simplifies creating, training, and deploying Amazon SageMaker models using SQL for database developers and Data Analysts.
- Federated Query: The federated query allows you to reach into your operational, relational database. You can now query live data across one or more Aurora PostgreSQL and Amazon RDS databases to get instant visibility into the end-to-end business operations without the need for data movement.
- Materialized Views: This Redshift feature allows you to achieve faster query performance on datasets ranging in size from gigabytes to petabytes. Data Compression, Columnar Storage, and Zone Maps considerably reduce the amount of I/O needed to perform queries.
- Limitless Concurrency: Amazon Redshift provides fast performance consistently, even with thousands of concurrent queries, whether they query data directly in your Amazon S3 Data Lake, or in your Amazon Redshift Data Warehouse.
Method 1: Using Hevo Data to Connect Intercom to Redshift

Step 1.1: Configure Intercom as Your Source

Step 1.2: Configure Redshift as Your Destination

Hevo’s fault-tolerant algorithms automatically handle any errors in the data flow, thereby ensuring that your warehouse always has up-to-date data.
Quick Overview of Hevo
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication, so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: As your sources and the volume of data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.

Method 2: Using Intercom APIs to Connect Intercom to Redshift
Intercom APIs help its users to programmatically fetch and manage their data. Intercom uses the OAuth protocol for authenticating its app integrations. For account holders who want to access only their data, they also support developer access token-based authentication. The APIs are rate limited with headers in the responses to inform developers about the remaining number of requests.
Let us now learn about the basic building blocks of implementing a custom script to copy data from Intercom to Redshift. We will be using Linux command-line utilities to show the steps involved.
The broad steps to this approach are as follows:
- Step 2.1: Creating an Application in the Intercom Developer Hub
- Step 2.2: Extracting Data Using Intercom API
- Step 2.3: Parsing the JSON Output
- Step 2.4: Loading Data to Amazon S3
- Step 2.5: Copying Data to Amazon Redshift
Prerequisites
In addition to a running Intercom and Redshift account, you would need the following to be To successfully execute the following steps, you will need to have:
- Intercom account with access to Intercom Developer Hub
- Required credentials to access Amazon S3 bucket and AWS Redshift
Step 2.1: Creating an Application in the Intercom Developer Hub
The first step is to create an application in the Intercom developer hub and retrieve an access token. Since we will only be using our own data, let us skip OAuth for now. After creating the application in the developer hub, the access token can be retrieved from the Configure > Authentication section.
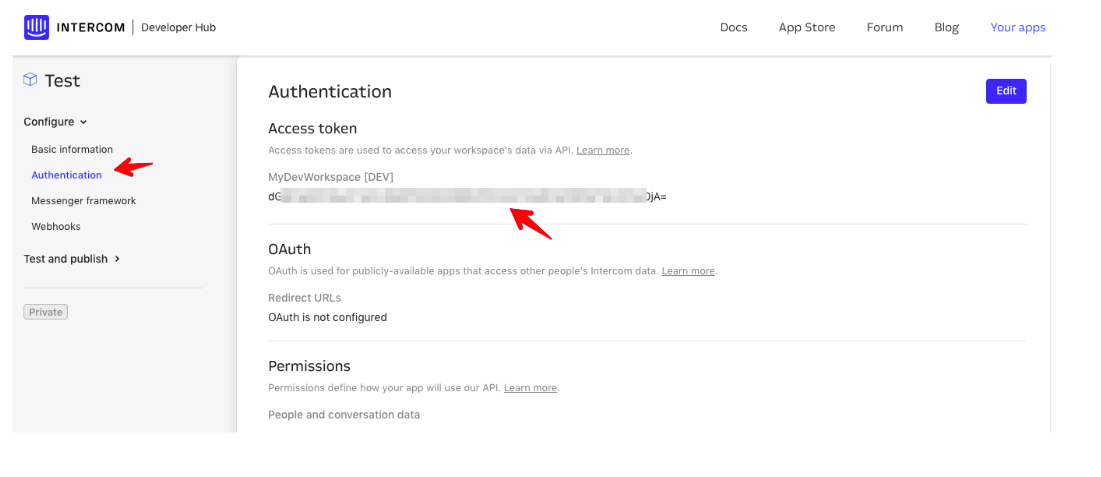
Step 2.2: Extracting Data Using Intercom API
Let us now use the Access token in retrieving some data. We will be using Contacts API to fetch the list of all the contacts. The API is paginated with a per_page parameter and starting_from parameter deciding the next items to fetch. Here we will be setting the per_page parameter as 2 which means we want to fetch 2 contacts per request. The default is 50 and the maximum is set at 150.
curl -o contacts.json https://api.intercom.io/contacts?per_page=2
-H 'Authorization:Bearer <access_token>'
-H 'Accept:application/json'The result of this command will be a JSON file with a list of contacts. Each contact entry has a name, email, companies with which the user is associated, location, and a whole lot of details.
Step 2.3: Parsing the JSON Output
We will now use the JSON file from the previous step to extract the relevant entries. For now, we will focus on the name, email, and location of the contacts. We will be using a command-line utility called jq to parse the JSON.
cat contact.json | jq -r ".data[] | [.id,.name,.email,.location.city] | @csv" >> contacts.csvThe output will be a file named contacts.csv with contents as below.
"5ba682d23d7cf92bef87bfd4","Hoban Washburn","Hoban@seren.io","Dublin"
"5ba682d23d7cf92bef87bfd5","Ashik Washburn","aw@abc.io","Dublin"Step 2.4: Loading Data to Amazon S3
Lets us now move this file to an S3 bucket to stage before loading to Redshift.
aws s3 cp /contacts/contacts.csv s3://contacts_bucket/
copy contacts
from 's3://contacts_bucket/contacts.csv'
iam_role 'arn:aws:iam::0123456789012:role/User_RedshiftRole'
csv;Step 2.5: Copying Data to Amazon Redshift
You will use the COPY command from Redshift to load this CSV file from S3 to Redshift.
That concludes the basic steps of executing a copying operation from Intercom to Redshift. The above steps can serve as a template for implementing an application to load data from Intercom to Redshift. While using this approach to execute a copying operation in production, several challenges will come out. Let us look at the typical problems that the developer will have to overcome in executing such an operation reliably.
Limitations of Using Intercom APIs to Connect Intercom to Redshift
- Intercom APIs are paginated. So if you have a large amount of data, the application has to include logic to keep track of the current page and form requests accordingly.
- The API is rate-limited. Spawning requests continuously without adhering to rate limits can lead to too many requests exception being returned as a response. The application logic should have a provision to process the response headers which include details of remaining requests possible at any point in time.
- Usually, such a load process needs to be executed continuously ensuring a near-real-time updated copy of the customer list in the data warehouse. To accomplish this additional logic to handle updates, deletes, and duplicates are required. This is, even more, tougher since Redshift does not enforce primary keys while loading data.
- Redshift’s automatic data type casting may cause problems if you don’t specify a data type mapping configuration file along with the COPY command.
- This approach needs a staging system where the file is held and the requests are executed. In the age of software-as-service offerings, such flexibility is rare.
- The above steps handle only one specific API – the contacts API. Intercom provides several other APIs with different JSON structures to fetch many other useful data elements. There will be a learning curve in making sense of all APIs, their capabilities, and the response structure before implementing a comprehensive data load process.
- In most cases, the fetched data will need to be transformed before loading it into the database. This would need you to take additional steps to load data.
Summary
- In this article, we have learned about two methods to load data from Intercom to Redshift.
- One method uses Intercom APIs to integrate Intercom with Redshift, which is a manual approach.
- Hevo eliminates the added complexity of writing and maintaining custom scripts to move data from Intercom to Redshift.
- Hevo natively integrates with Sales and Marketing Applications, Analytics Applications, Databases, and so on enabling your organization to efficiently assemble an enterprise BI data warehouse.
Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines. You can also check out the unbeatable pricing, which will help you choose the right plan for your business needs.
Frequently Asked Questions
1. How do I transfer data from RDS to Redshift?
You can transfer data from RDS to Redshift using Hevo, which automates the process, or you can export the data and use AWS DMS (Data Migration Service) to move it to Redshift.
2. How can I use Intercom?
Intercom can be used for customer support, messaging, and managing interactions with users through chat, email, and apps.
3. Is Intercom free to use?
Intercom offers a free trial, but it is primarily a paid service with different pricing tiers based on features and usage.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



