




Unlock the full potential of your JIRA data by integrating it seamlessly with BigQuery. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
Without the right architecture, storing and querying large amounts of data can be time-consuming and expensive. So, you need a data warehouse like BigQuery to solve this problem. BigQuery uses Google’s processing power, which enables super-fast SQL queries. In this blog, we are going to discuss two popular methods of transferring data from JIRA to BigQuery for deeper analysis. Before we get into that, let’s understand these two applications.
Table of Contents
Why You Should Integrate Jira with BigQuery?
Jira BigQuery integration has the following benefits:
- Scalability: BigQuery is designed to handle enormous amounts of data, allowing you to accommodate your growing data needs.
- Real-time data synchronization: Load your Jira data directly to bigQuery in real-time for faster analysis.
- Advanced analytics: BigQuery offers SQL-based querying and machine learning capabilities that help in advanced analysis of your data.
- Comprehensive reports and dashboards: After loading data to BigQuery, you can connect this to your visualization tools for creating comprehensive reports and dashboards.
Prerequisites
Here is a list of prerequisites to get you started with the data migration:
- JIRA account with admin access.
- GCP (Google Cloud Platform) account with billing enabled.
- Google Cloud SDK is installed on your CLI.
- BigQuery API enabled.
- BigQuery.admin permissions.
Seamlessly migrate your Issues and project data from Jira. Hevo elevates your data migration game with its no-code platform. Ensure seamless data migration using features like:
- Seamless integration with your desired data warehouse, such as BigQuery or Redshift.
- Transform and map data easily with drag-and-drop features.
- Real-time data migration to leverage AI/ML features of BigQuery and Synapse.
Still not sure? See how Postman, the world’s leading API platform, used Hevo to save 30-40 hours of developer efforts monthly and found a one-stop solution for all its data integration needs.
Get Started with Hevo for FreeMethods to connect JIRA to BigQuery
There are multiple methods that can be used to connect JIRA to BigQuery and load data easily:
- Method 1: Using Hevo Data, a No-code Data Pipeline
- Method 2: Using custom ETL scripts to load data from JIRA to BigQuery
Method 1: Using Hevo Data, a No-code Data Pipeline
Hevo Data focuses on two simple steps to get you started:
- Configure Source: Connect Hevo Data with JIRA by providing the API Key and User Email for your authorised Atlassian/Jira account, along with your Atlassian Site Name and a unique name for your pipeline.
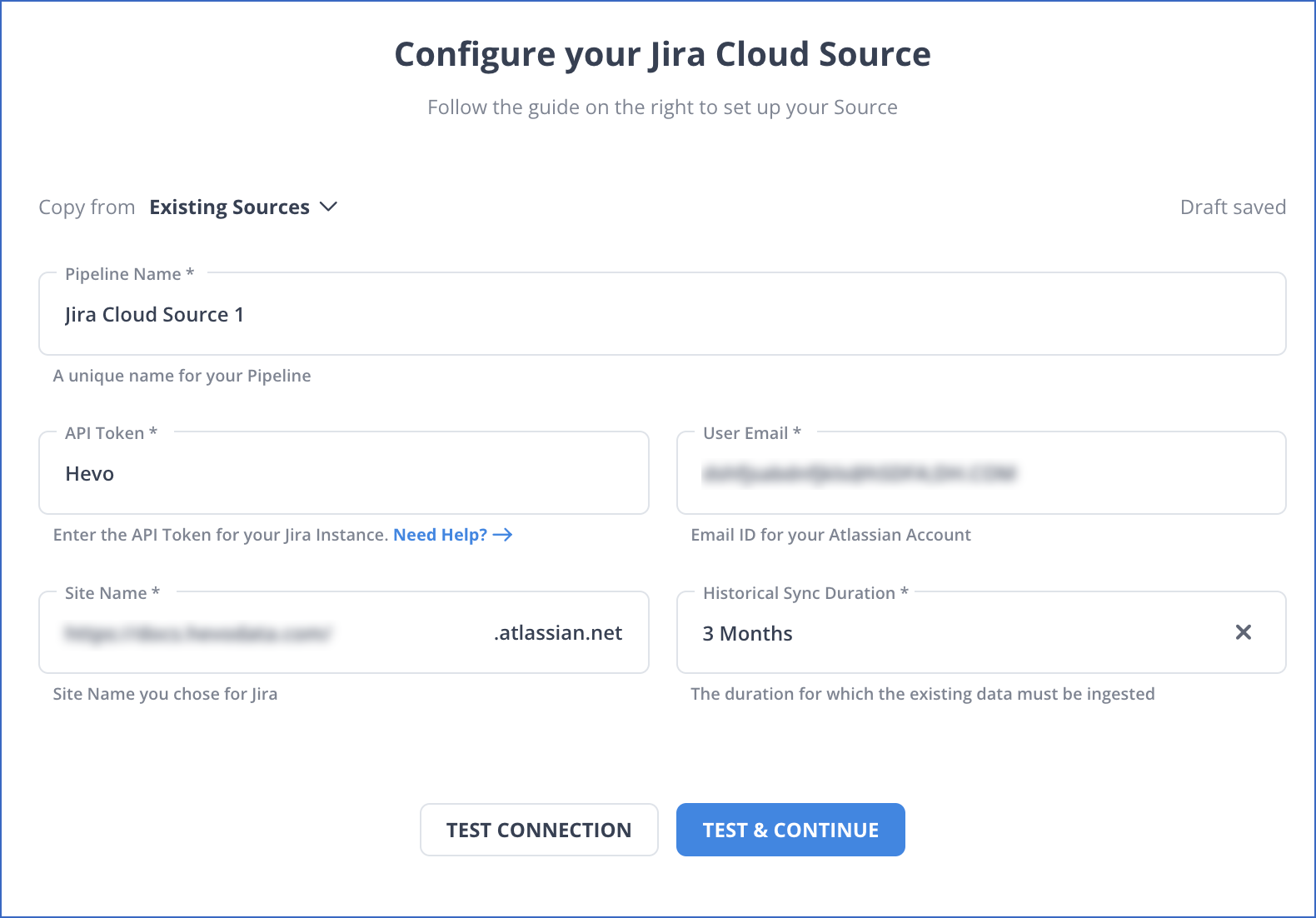
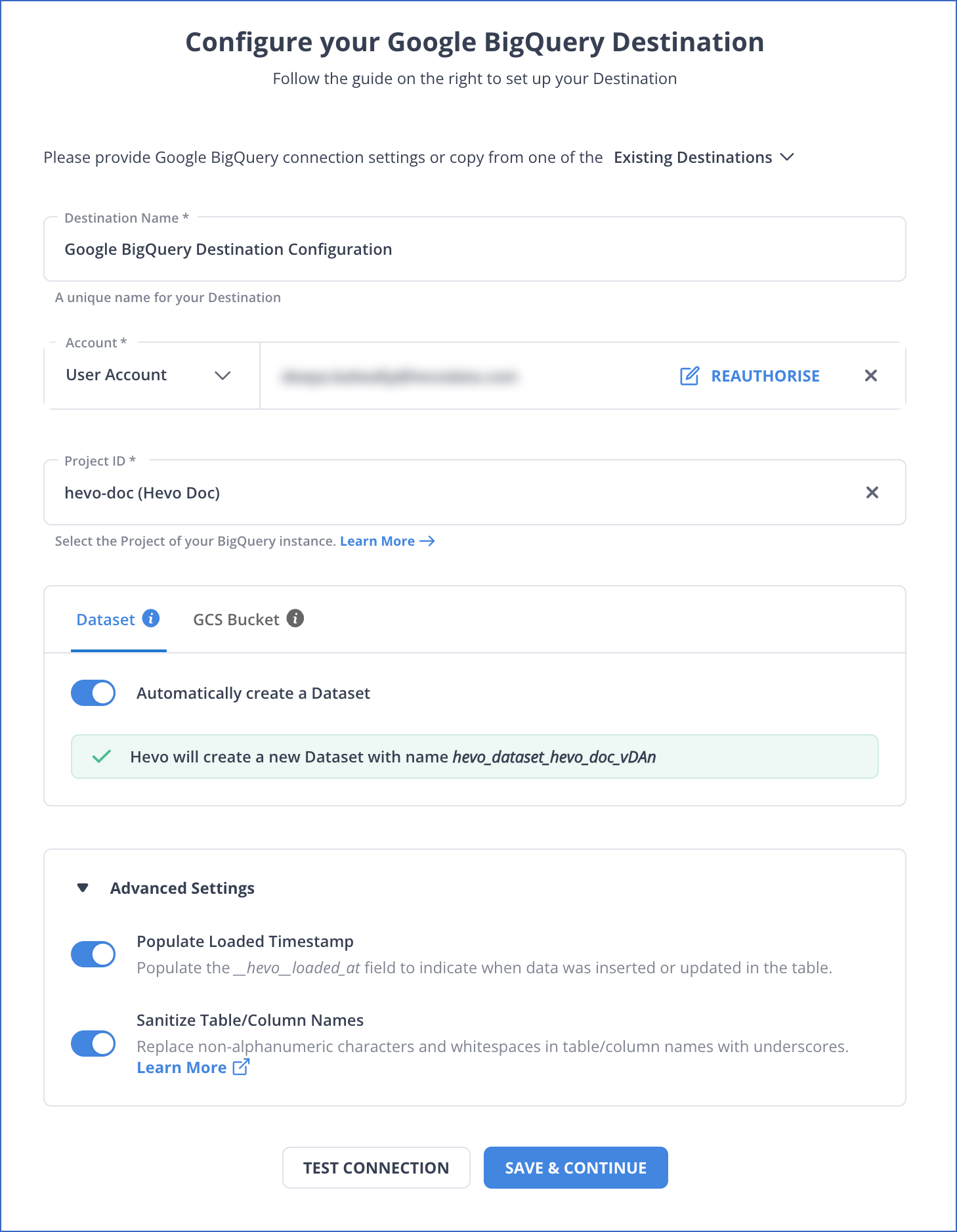
- Integrate Data: Load data from JIRA to BigQuery by providing your BigQuery database credentials. Enter the authorised account associated with your data and the ID of the project, whose data you want to transfer, along with a name for your dataset to connect in a matter of minutes.

Method 2: Using custom ETL scripts to load data from JIRA to BigQuery
The steps involved in moving data from JIRA to BigQuery manually are as follows:
Step 1: Extract
Extracting Data from JIRA using REST APIs with a Python Script
import requests
response = requests.get("https://your-domain.atlassian.net/rest/api/2/issue/ISSUE-123/comment", auth=('email', 'api_token'))
data = response.json()Step 2: Transform
Convert the JSON response to CSV or NDJSON for BigQuery.
import json
with open('jira_comments.ndjson', 'w') as f:
for comment in data['comments']:
f.write(json.dumps(comment) + '\n')Step 3: Load
Load: Use the bq CLI to load the file into BigQuery.
bq load --source_format=NEWLINE_DELIMITED_JSON your_dataset.jira_comments jira_comments.ndjson schema.json Limitations of using custom ETL scripts to connect JIRA to BigQuery
- Real-time data sync is resource-intensive and hard to manage efficiently.
- Requires ongoing maintenance as API changes can break the data pipeline.
- Demands strong programming skills and robust error handling.
- Doesn’t support automatic schema updates, making maintenance harder.
Conclusion
In this article, you learned how to effectively transfer data from JIRA to BigQuery using two different techniques. You can manually write custom scripts to extract the data from Jira using Rest APIs, prepare the data by creating a schema, and then finally load it into BigQuery. Regularly extracting and loading the data manually can be a time-consuming task. You would have to invest a section of your engineering bandwidth to integrate, Clean, Transform, and load your data to your desired destination so that you can perform business analysis in real-time. All of this can be easily solved by a Cloud-Based ETL Tool like Hevo Data.
Sign up for a free 14-day trial to give Hevo a try.
Frequently Asked Questions
1. How to connect Jira to BigQuery?
You can connect Jira to BigQuery by using custom ETL scripts or by using automated platforms like Hevo.
2. How do I extract data from Jira?
Methods to extract data from Jira:
– Using Jira REST API.
-Using Jira’s built-in export features.
-Using automated tools like Hevo.
3. Can you query the JIRA database?
Directly querying the JIRA database is not typically recommended due to the complexity of the schema and potential performance issues.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link




