




Easily move your data from Jira To Redshift to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
Data analysis involves many tools and techniques crucial in developing and maintaining data in any firm. The better you manage and analyze your data, the better you will understand the trends and patterns in the massive amount of data you collect.
Jira is a feature-packed project management software offering bug and issue tracking. Many software development companies use it as their go-to tool for project management. However, as your company’s data requirements significantly increase, you need a data warehousing solution. You can employ Amazon Redshift, a data warehouse solution that stores and processes massive amounts of data.
If you want a Jira to Redshift converter tutorial, this article has everything you need! It will examine two different ways to migrate data from Jira to Redshift, improving your data analytics and processing needs.
Table of Contents
An Introduction to Jira

Jira is a powerful project management software developed by Atlassian. It provides an all-in-one platform for tracking and managing bugs and issues, prioritizing, and organizing the team. Jira can be easily integrated with other tools, smoothening the workflow and making it adaptable to different organizations’ needs. Jira has features such as warehouse automation, team management, and a dashboard, allowing you to stay on top of your data processes.
An Introduction to Redshift

AWS Redshift is Amazon’s data warehousing solution. It can handle huge amounts of structured and unstructured data, making it ideal for your extensive data needs. Amazon Redshift distributes data and queries among several cluster nodes, which allows it to handle complicated analytical processes on massive datasets with excellent scalability and performance.
Hevo is an automated data integration platform that simplifies the process of transferring data from various sources like Jira to data warehouses like Redshift, enabling seamless analytics and reporting.
What Hevo Offers:
- No-Code Interface: Easily connect and configure data sources without writing any code, saving time and effort.
- Real-Time Data Sync: Ensure that your data in Redshift is always up to date with automated real-time ingestions.
- Data Transformation: Automatically enrich and transform your data into an analysis-ready format, enhancing insights.
Try Hevo and discover why 2000+ customers have chosen Hevo over tools like AWS DMS to upgrade to a modern data stack.
Get Started with Hevo for FreeWhy Migrate Data from Jira to Amazon Redshift?
Here are some reasons to consider migrating from Jira to Amazon Redshift:
- Cost-Effective Storage: Redshift offers a cost-effective solution for storing large amounts of data compared to traditional relational databases, which can help organizations save on storage costs while maintaining performance.
- Enhanced Data Analytics: Amazon Redshift provides powerful analytical capabilities, enabling complex queries and data analysis on large datasets. This is beneficial for organizations looking to derive deeper insights from their Jira data.
- Scalability: Redshift is designed to handle large volumes of data and can scale easily as your data storage and processing needs grow, accommodating future growth without significant reconfiguration.
- Integration with Other Data Sources: Redshift allows for seamless integration with various data sources, including AWS services and third-party tools. This facilitates a comprehensive data ecosystem for better reporting and analytics.
Different Ways to Load and Integrate Data from Jira to Redshift
Let’s see two simple methods with detailed steps for integrating data from Jira to Redshift.
Method 1: Using Hevo to Migrate Data from Jira to Redshift
One of the best ways to convert Jira to Redshift is through Hevo, a real-time ELT, no-code, and automated data pipeline platform that is cost-effective and fully flexible to your needs. It offers 150+ integrations from different data sources (out of which 40+ are free), which help you load and transform the data into the destination, making it analysis-ready.
Take a look at some of the benefits of Hevo:
- Data Transformation: With Hevo, you get drag-and-drop and Python-based transformation features to standardize and prepare your data before moving it to your chosen destination.
- Incremental Data Load: Hevo allows you to transfer modified data from the source to the destination in real-time.
- Auto Schema Mapping: Hevo automatically detects the format of incoming data and replicates the same schema in your destination.
Here’s a step-by-step guide for integrating data from Jira to Redshift using Hevo.
1. Setting up Jira as the Source
Prerequisites
If you want to replicate data from the Jira Cloud account to Redshift using Hevo Data, these are some of the prerequisites you must follow:
- You must have a Jira Cloud instance from which data is to be loaded.
- Provide READ permissions to the data loaded from the authenticated user.
- The API token should be available to authenticate Hevo on the Jira cloud account.
- If you are trying to load data from the Jira Cloud using Hevo, you must be assigned the role of Team Administrator, Team Collaborator, or Pipeline Administrator in Hevo.
Step 1: Create an API Token from Your Atlassian Account
- Log in to your account and find the API tokens page.

- Click on Create API token. In the pop-up menu, specify a label for your token. Enter an easy-to-remember label name and click on Create.

- Click on Copy to copy the token and keep it safe. You will need this while configuring your Hevo pipeline.
Step 2: Configure Jira Cloud as the Source
- Click on the PIPELINES tab in the Navigation Bar.
- Select the +CREATE button in the Pipelines List View.
- In the Select Source Type page, choose Jira Cloud.
- The Configure your Jira Cloud Source page will open up. Here, you need to specify the following details:
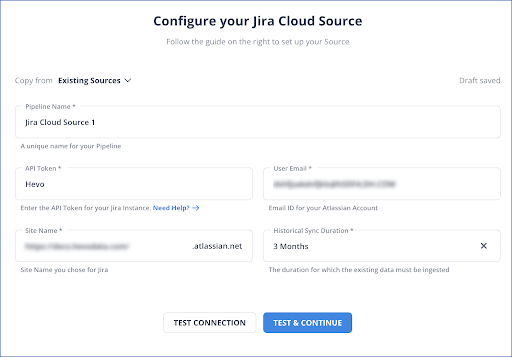
- Pipeline Name: Give a unique name to your pipeline.
- API Token: Enter the API token you created while setting up the Jira account, allowing Hevo to read your data.
- Email ID: Enter the email ID linked to your Jira account.
- Site Name: Extract this from your dashboard URL. For example, if your dashboard URL is: “https://mycompany.atlassian.net/Jira/dashboards/,” your site name is mycompany. Put that value here.
- Historical Sync Duration: Here, you should enter the duration for which you want to ingest the existing data from Jira.
- Now, click on Test and Continue. To know more about setting Jira Cloud as your source, refer to the Hevo documentation.
2. Setting up Redshift as Your Destination
Prerequisites
These are some of the prerequisites for setting up Amazon Redshift.
- The Amazon Redshift instance should be running.
- The Amazon Redshift database should be available.
- The port number and the database hostname of the Amazon Redshift instance should be available.
- Keep Hevo’s IP address whitelisted.
- Provide the database user SELECT privileges.
- You should be assigned the Team Collaborator or any administrator role except the Billing Administrator role in Hevo to create the Destination.
Step 1: Whitelist Hevo’s IP Address
To connect Hevo to your Amazon Redshift database, you must whitelist the Hevo IP address of your region.
- Log in to the Amazon Redshift dashboard and click the Clusters button in the left navigation pane.
- Click on the Cluster that you want to connect to Hevo.
- Navigate to the Configuration tab. Now click on the text link under Cluster Properties. Click on the VPC security groups to open the Security Groups panel.
- In the Inbound tab, select the Edit option and make the following edits in the Edit inbound rules dialog box.
- Click on the Add Rule button and select the type as Redshift.
- Enter the port of your Amazon Redshift cluster in the Port Range column.
- Select the CUSTOM option from the Source column and add Hevo’s IP address for your region. Repeat this process to whitelist all IP addresses, and click Save.
Step 2: Create a User and Grant the Necessary Permissions
To create a user, you must log in to Amazon Redshift as a superuser or a user with CREATE privilege. Enter the following command:
CREATE USER hevo WITH PASSWORD ‘<password>’;
Now, you must grant CREATE privilege to the existing database user and SELECT privilege to specific or all tables.
- For granting CREATE privilege
GRANT CREATE ON DATABASE <database_name> TO hevo;
GRANT CREATE ON SCHEMA <SCHEMA_NAME> TO <USER>;
GRANT USAGE ON SCHEMA <SCHEMA_NAME> TO <USER>;
- For granting SELECT privileges:
GRANT SELECT ON ALL TABLES IN SCHEMA <schema_name> TO hevo; #all tables
GRANT SELECT ON TABLE <schema_name>.<table_name> TO hevo; #specific table
Step 3: Configure Redshift as the Destination
- Click on the DESTINATIONS tab in the Navigation Bar and then click on +CREATE in Destinations List View.
- Select Amazon Redshift on the destination page.
- Now, in the Configure your Amazon Redshift Destination page, specify the following:

Start by adding the destination name, which should be unique and not exceed 255 characters. After this, you must configure the General Connection Setting. Under this, put a unique identifier under the Connection String to connect to the Amazon Redshift database. It will automatically fetch other required details. Remember, this connection string is obtained from the AWS console and is the same as the hostname URL.
Fill in the database user details and password (a non-administrative user in the Redshift database). Also, fill in the name of the Schema, which is the destination database schema.
You need to fill in all the Connection Fields manually. In the Database Cluster Identifier, fill in the host IP address of Amazon Redshift or its DNS name.
Also, remember that for URL-based hostnames, you need to always exclude the initial jdbc:redshift:// part. If the hostname URL is jdbc:redshift://examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com:5439/dev, you need to ignore the initial part and just put in examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com.
Fill in the Database Port details on which the Amazon Redshift server is available for connections. The Database Name will hold the name of the existing database where data is to be loaded. You can also put the name of the database schema in Amazon Redshift.
Additionally, you can enable the option to connect using an SSH tunnel. It provides an added layer of security by making the Redshift setup inaccessible to the public.
Finally, click on TEST CONNECTION, followed by SAVE & CONTINUE. For more details on how to set up Redshift as your data pipeline’s destination, please refer to the Hevo documentation.
Learn more about Jira to Databricks Integration.

Method 2: Using the REST API Data Loading Method to Insert Jira to Redshift
You must complete the following prerequisites to load data from Jira to Redshift using REST API.
- You will need a Jira account with API access.
- You must have an AWS account to set up an Amazon Redshift and Amazon S3 bucket.
Step 1: Load Data by Extracting It from Jira
When using the REST API to extract data, you can extract different kinds of data, such as attachments, comments, etc. To do so, you must interact with the API, which is possible using programming languages and tools like Python, Java, or Postman.
Step 2: Configure the Redshift Cluster
After going to Redshift Services in the AWS management console:
- Click on the Create Cluster button to start the cluster creation process.
- Depending on the requirements, select the correct region and configuration.
- Check the configuration for the desired security settings.
- Click on the created cluster and select the CONNECT button to configure the connection.
- You need to decide on the schema for the data from Jira, along with the column names, data types, and relationships between keys.
To connect to the Redshift Cluster, you can use tools like pgAdmin or SQL Workbench, using the connection configuration we got earlier. You will need to run some SQL commands to create tables. You may need to transform extracted data under the schema. Also, remember to check data quality before loading it into Redshift tables.
Step 3: Load Data into Amazon Redshift
Use the COPY command to load your data as objects. These objects can be various multimedia files or any other data type. Each object is identified as a unique key in the bucket.
After creating the Amazon S3 bucket:
- Click on CREATE BUCKET.
- Provide a unique, easy-to-remember name for your bucket and enter the region where you want to store data.
- Store the extracted data in the S3 buckets.
Use these commands to upload data to Amazon S3. Remember to use the correct code for whether you want to upload a single file or a directory.
- Command to upload a single file:
aws s3 cp /path/to/local/file s3://bucket-name/destination/folder/
- Command to upload a whole directory and sync it:
aws s3 sync /path/to/local/directory s3://bucket-name/destination/folder/
After uploading the data to Amazon S3, load it into Redshift using the COPY FROM command.
COPY table_name
FROM ‘s3://bucket-name/destination/folder/file’
IAM_ROLE ‘iam-role-arn’
CSV DELIMITER ‘,’;
Limitations of Using Rest API to Migrate Data from Jira to Redshift
Although you can use the REST API method to load data from Jira to Redshift, it has the following limitations:
- If your company needs to change the data scheme in Jira frequently as per data security compliances, it may lead to data consistency and mapping issues. You must thoroughly test and validate the entire data after every schema change to ensure data integrity and consistency.
- This method necessitates writing the data extraction and transformation logic before loading it. You will have to update the data manually and continuously, which will take up much of your time.
Wrapping Up
In this article, you saw two data migration methods that will help you load Jira to Redshift. The manual method can be difficult and time-consuming, requiring an in-depth understanding of programming languages and REST API. On the other hand, Hevo has made the process easy with its smooth and automated data pipeline. This makes Hevo a great alternative to any manual method for migrating large datasets.
Hevo can help you integrate your data from numerous sources and load them into a destination to analyze real-time data with a BI tool such as Tableau. It helps transfer data from source to a destination of your choice for free. It will make your life easier and data migration hassle-free. It is user-friendly, reliable, and secure. Check out the Hevo Pricing details here.
Frequently Asked Questions (FAQs)
Q1. Is there a maximum Jira record limit when querying from the REST API method?
Using the REST API method, you can fetch a maximum of 1000 records from Jira. If you have data records that exceed the limit, you must conduct the process in different batches. Alternatively, you can use Hevo, which allows you to transfer large datasets through its easy-to-use, automated data pipeline.
Q2. How do I change the date format in Jira Cloud before migrating my datasets to Redshift?
You can go to the Cog icon > System > General configuration > Advanced settings in Jira Cloud and change the date format before migrating datasets. If you are using Hevo’s data pipelines, you can refer to the Hevo documentation to learn about this transformation feature.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



