




According to a report, humans create 2.5 Quintillion Bytes of Data per day. Proper Analysis of this data can provide insights into Consumer Behaviour that can help brands improve their Sales, Operations, and Marketing Strategies. Streaming Data is a continuous flow of information between disparate sources to a destination for Analytics and Real-time Processing. With Real-time Data Processing, businesses can gain insights into Consumer Behaviour and their choices. A Streaming Data Pipeline helps a smooth and automatic flow of information from one point to another. Streaming Data Integration has multiple use cases such as contextual Marketing Triggers, Dynamic Pricing, Fraud Detection, etc.
Apache Kafka is a Distributed, Open-source, Event Streaming Platform businesses use for Data Integration, Streaming Analytics, and Data Pipelines. Apache Kafka Connect is a framework that helps move data between Kafka and other systems. To pull repositories from GitHub, you have to use GitHub Source Connector, and Kafka Connect.
In this blog, you will learn about Apache Kafka, GitHub, Kafka Connector, how to pull data from GitHub, and finally on integrating Kafka GitHub together.
Table of Contents
What is Apache Kafka?
Apache Kafka is an Open-source Software that runs in a Distributed Environment that provides a framework for storing, reading, and analyzing Streaming Data. You can create Real-time and Event-driven Applications using such instantaneous data. It runs across multiple servers to leverage the additional Processing Power and Storage Capacity.
Apache Kafka was created at LinkedIn, where it analyzed connections between the professional users to build networks between people and was given open-source status while being passed to Apache foundation. Today, Apache Kafka is a reliable system that is fault-tolerant and can be replicated. It also maintains a stable performance and has high throughput for Publishing and Subscribing to messages. Kafka can scale in all four dimensions: Event Processes, Event Producers, Event Consumers, and Event Connectors without any downtime.
Apache Kafka is used by the world’s most prominent companies, including 80 per cent of Fortune 500 companies such as Netflix, Spotify, and Uber, due to its Distributive Nature and Efficient Throughput.
What is GitHub?
Git is a Version Control System created by Linus Torvalds in 2005 that can manage and store revisions of products. A version control system like Git allows multiple developers to work in parallel and avoid conflicts. GitHub is a Cloud-based, Git repository hosting service that helps developers manage, track, and control their code. GitHub was founded in 2008 to make tools that can integrate with Git Repositories. It is similar to a Software Developer Social Networking site. Users can access Git Repositories without GitHub, but they’ll have to use the Command-line tool.
Unlike other repository hosting services, Git is a distributed version control system where developers can copy a repository to make changes and then submit a pull request without connecting to the server every time they make a change. GitHub provides a web-based graphical interface for Git, a command-line tool. Fork, pull request, and merge are the three features that make GitHub powerful. In addition to its well-known SaaS option, GitHub provides an On-premises version of its software. With GitHub, contributing to open-source projects has become seamless for Project Managers and Contributors.
What is Kafka Connect?
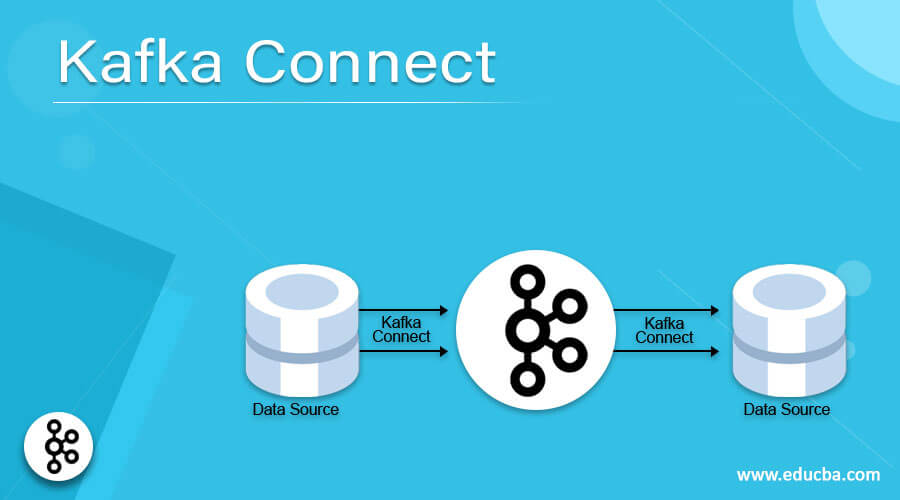
Kafka Connect is a pluggable, declarative Data Integration Framework for Streaming Data between Apache Kafka® and other data systems. The tool makes it simple to quickly define connectors to move large datasets in and out of Apache Kafka. It replaces the need to write and deploy code for connecting Data Sinks with Kafka. Kafka Connect provides the framework with which developers can write connectors for specific tasks of collecting or sending data from sink to source or vice versa. There can be two types of connectors:
- Source Connector produces events to Kafka and sends data from one source system to Kafka.
- Sync Connector consumes events to Kafka and fetches data from Kafka to be sent to a Target System (sink).
What is the GitHub Source Connector?
The GitHub Connector allows users to pull resource files from the GitHub Repository and translate them. The Kafka GitHub Source Connector pulls status from GitHub through GitHub API, converts them into Kafka Records, and then pushes the records into Kafka Topic. Every GitHub Record gets converted into exactly one Kafka Record.
Kafka GitHub Source Connector is used to detect changes in real-time from GitHub to Apache Kafka Topics. It will pull data through GitHub API and convert them into Kafka Records.
Ways to Configure the GitHub Connector
1) Pull Requests Mode
With the Pull Request Mode, developers can select a branch in the repository for all requests containing translatable files. Once the Connector finds all the Translatable files, it will Flag or Lock that request and automatically send the files to Kafka for translation.
The Flag on Locked Pull Requests will remain open until all the translations are done. GitHub Connector will create a new translation branch and pull requests once the previous job is complete. The admin user can merge these Kafka Github Pull Requests, removing the Flag from the initial pull request. Use this mode if you want to translate the entire content of a repository.
2) Single Branch Mode
The Single Branch Mode will upload all translatable files and add them to a job. Whenever the connector detects a commit to the files, it will automatically upload the translatable files to Kafka for translation. Unlike the Pull Request mode, files are not flagged or locked in this process, and you can continue the development work without translations.
Once the Translation Jobs are complete, a request is created in your repository, which contains all translations in one file per language. This is the right method for teams that want to continue the development of Kafka GitHub when the translation is in process.
Key Features of GitHub Source Connector
1) At least Once Delivery
Kafka GitHub Connector ensures that all the records pulled from GitHub are delivered at least once to Apache Kafka Topic. However, there can be duplicate records in Kafka’s topic if the connector restarts.
2) API Rate Limits Awareness
If your API Rate Limit exceeds, the connector will stop fetching records from GitHub. You will have to reset the API Rate Limit for the connector to resume fetching records.
3) Supports HTTPS Proxy
GitHub connector uses an HTTPS Proxy Server for connecting to GitHub. To configure the proxy, you can set HTTP. proxy.host, HTTP. proxy.port, HTTP.proxy.user and HTTP.proxy.password in the configuration file.
How to Install GitHub Source Connector for Kafka?
Before setting up the Kafka GitHub Source Connector, you will need Kafka, Zookeeper, and Kafka Connect installed on your system.
You can start Kafka using the Confluent platform repository, but you will also need docker, docker-compose, and Git installed.
Kafka Github Step 1: Installing the GitHub Connector
You can install the GitHub source connector in one of the two ways: Manually Downloading or using the Confluent Hub Client.
- Go to the GitHub Connector supported by confluent and download the files. After downloading the files, copy the folder into the Kafka Connect Container and restart it. You can go and visit http://localhost:8083/connector-plugins to ensure that connector has been successfully installed on your system.
- You will have to install the GitHub Connector on every machine Kafka Connect will run. The Confluent License is free for a 30 days trial period, after which the company issues Enterprise License keys to subscribers along with Enterprise-level Support for platforms and connectors.
Kafka GitHub Step 2: Configuring the Connector
Before the connector can start Pulling Requests from GitHub, you must configure it by making a post request to the configuration endpoint. You can create as many configurations you want for the connector, where each configuration will represent a worker of its own. However, you will need to use a different name for each configuration.
Go to localhost:8083/connectors/ to check configured connectors. You can choose between a JSON Converter or an Avro Converter.
Github Source Connector Configuration Properties
GitHub Source Connector Configuration Properties are listed below:
1) GitHub.repositories
You can read the GitHub repositories in the form of owner/repo-name from Kafka. For example, “confluentinc/kafka-connect-GitHub.’’ It is a Non-empty list type (List of repositories, separated by commas).
2) GitHub.service.url
It is a type of string used to pull the GitHub Service URL. Valid values are URLs with HTTP or HTTPS.
3) GitHub.tables
They are used for tables to extract and write to Apache Kafka. It is of list type with valid values like pull_requests, comments, collaborators, issues, commits, review_comments, releases.
4) GitHub.since
The connector will process records created or updated after this. You can leave it blank if you want the default time when the connector is launched. It’s a string that only takes time as input by default.
You can also override the default configuration properties. However, you cannot override the Kafka GitHub Topic Cleanup Policy because the Topic always has a single partition.
- Replication Factor: To override the Replication Factor, use the confluent.topic.replication.factor command. For example, if you have less than three factors when using a Kafka Cluster, set the confluent.topic.replication.factor property to 1.
- Producer-specific Properties: Using the confluent.topic.producer. prefix, you can change the consumer-specific property.
You can also read more about:
Conclusion
In this article, you learned about Apache Kafka, GitHub, Kafka Connector, GitHub Connector, and how to connect Kafka GitHub. You can use the GitHub Source Connector and Kafka Connect to pull requests from Git repositories and convert them into Kafka Records.
Extracting complicated data from Apache Kafka & GitHub, on the other hand, can be Difficult and Time-Consuming. If you’re having trouble with these and want to find a solution, Hevo Data is a good place to start!
Hevo Data is a No-Code Data Pipeline that offers a faster way to move data from 150+ Data Sources including GitHub, Apache Kafka, Kafka Confluent Cloud, and other 40+ Free Sources, into your Data Warehouse to be visualized in a BI tool. You can use Hevo’s Data Pipelines to replicate the data from your Apache Kafka Source, Kafka Confluent Cloud and even GitHub to the Destination system. Hevo is fully automated and hence does not require you to code.
Want to take Hevo for a spin? SIGN UP for a 14-day Free Trial and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Share your experience of learning about the Kafka Github Source Connector in the comments section below!

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



