




Organizations today have access to a wide stream of data. Apache Kafka, a popular Data Processing Service is used by over 30% of Fortune 500 companies to develop real-time data feeds. Kafka is a fault-tolerant Distributed Streaming platform that exhibits high resiliency and throughput.
But there are times when its performance doesn’t always meet everyone’s expectations. Hence, to make the system more flexible and resilient, it becomes important to implement Kafka Producer Configurations.
Kafka Producer is the source of the data stream and it writes tokens or messages to one or more topics in a Kafka Cluster. ProducerConfig is the configuration of a Kafka Producer. There are literally piles of Kafka Producer Configurations in the ecosystem that can help you bring your Kafka Producer to the next level. But before getting started with Kafka Producer Configurations, let’s briefly discuss this robust data streaming platform.
Table of Contents
What is Kafka?

- Apache Kafka is a popular Distributed Data Streaming software that allows for the development of real-time event-driven applications. Being an open-source application, Kafka allows you to store, read, and analyze streams of data free of cost.
- Kafka is distributed, which means that it can run as a Cluster that spans multiple servers. Leveraging its distributed nature, users can achieve high throughput, minimal latency, high computation power, etc., and can handle large volumes of data without any perceptible lag in performance.
- Kafka employs two functions, “Producers” and “Consumers” to read, write, and process events.
- Kafka Producers act as an interface between Data Sources and Topics, and Kafka Consumers allow users to read and transfer the data stored in Kafka.
- The fault-tolerant architecture of Kafka is highly scalable and can handle billions of events with ease. In addition to that, Kafka is super fast and is highly accurate with data records.
HevoData is a No-code Data Pipeline that offers a fully managed solution to set up data integration from Apache Kafka and 150+ Data Sources (including 60+ Free Data Sources)and will let you directly load data to a Data Warehouse or the destination of your choice.
Let’s look at some of the salient features of Hevo:
- Fully Managed: Hevo Data is a fully managed service and is straightforward to set up.
- Schema Management: Hevo Data automatically maps the source schema to perform analysis without worrying about the changing schema.
- Real-Time: Hevo Data works on the batch as well as real-time data transfer so that your data is analysis-ready always.
- Live Support: With 24/5 support, Hevo provides customer-centric solutions to the business use case.
Key Features of Kafka
- Fault-Tolerant: Kafka’s fault-tolerant clusters keep the organization data safe and secure in distributed and durable clusters. Kafka is exceptionally reliable and it also allows you to create new custom connections as per your needs.
- Scalability: Kafka can readily handle large volumes of data streams and trillions of messages per day. Kafka’s high scalability allows organizations to easily scale production clusters up to a thousand brokers.
- High Availability: Kafka is extremely fast and ensures zero downtime making sure your data is available anytime. Kafka replicates your data across multiple clusters efficiently without any data loss.
- Integrations: Kafka comes with a set of connectors that simplify moving data in and out of Kafka. Kafka Connect allows Developers to easily connect to 100s of event sources and event sinks such as AWS S3, PostgreSQL, MySQL, Elasticsearch, etc.
- Ease of Use: Kafka is a user-friendly platform and doesn’t require extensive programming knowledge to get started. Kafka has extensive resources in terms of documentation, tutorials, videos, projects, etc, to help Developers learn and develop applications using Kafka CLI.
What is the ProducerConfig Class in Kafka?
- Java is the native language of Apache Kafka, and there’s a class in Java called
KafkaProducerthat is used to connect to the cluster.KafkaProduceris the default Producer client in Kafka. - It is provided with a map of configuration parameters such as the address of some brokers in the cluster, any appropriate security configuration, and any other settings that determine the network behavior of the producer.
- The producer makes the decision about which partition to send the messages to.
- In Kafka, almost everything is controlled using configurations. In Kafka, key-value pairs in the property file format are used for configuration.
- These key values are provided either programmatically or from a file. Kafka
ProducerConfigis the configuration of a Kafka Producer. With a myriad of Kafka Producer Configurations in the ecosystem, it becomes nearly impossible to understand each one of them. - However, most of the Kafka Producer Configurations are predefined in a way that they can be implemented for most of the use cases.
Examples of Kafka Producer Configurations
Now that you have a basic understanding of what Kafka and the Kafka Producer Configurations are, let’s discuss the various Kafka Producer Configurations in the Kafka ecosystem. Although there are tons of configurations, the mandatory Kafka Producer Configurations that one needs to know in order to get started are very limited.
<a href="#c1" class="rank-math-link">acks</a><a href="#c2" class="rank-math-link">bootstrap.servers</a><a href="#c3" class="rank-math-link">retries</a><a href="#c4" class="rank-math-link">enable.idempotence</a><a href="#c5" class="rank-math-link">max.in.flight.requests.per.connection</a><a href="#c6" class="rank-math-link">buffer.memory</a><a href="#c7" class="rank-math-link">max.block.ms</a><a href="#c8" class="rank-math-link">linger.ms</a><a href="#c9" class="rank-math-link">batch.size</a><a href="#c10" class="rank-math-link">compression.type</a>



acks
Acks represent the number of acknowledgments that the producer needs the leader broker to have received before considering a successful commit. This helps to control the durability of messages that are sent. The following are the common settings for the acks Kafka Producer Config:
acks=0: Setting acks to 0 means the producer will not get any acknowledgment from the server at all. This means that the record will be immediately added to the socket buffer and considered sent.

acks=1: This means that as long as the producer receives an acknowledgment from the leader broker, it would consider it as a successful commit.

acks=all: This means the producer will have to wait for acknowledgments from all the in-sync replicas of that topic before considering a successful commit. It gives the strongest available message durability.
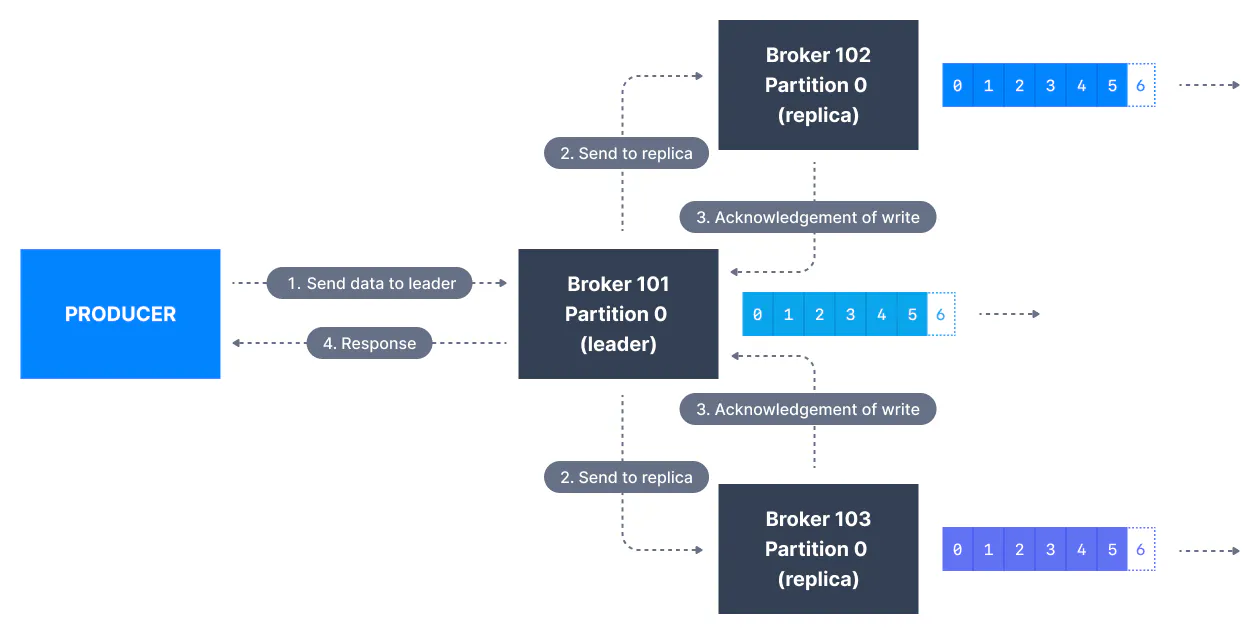
bootstrap.servers
bootstrap.server represents a list of host/port pairs that are used for establishing the initial connection to the Kafka Cluster. The list need not contain the full set of servers as they are used just to establish the initial connection to identify full cluster membership. The list should be in the format given below:
host1:port1,host2:port2,....retries
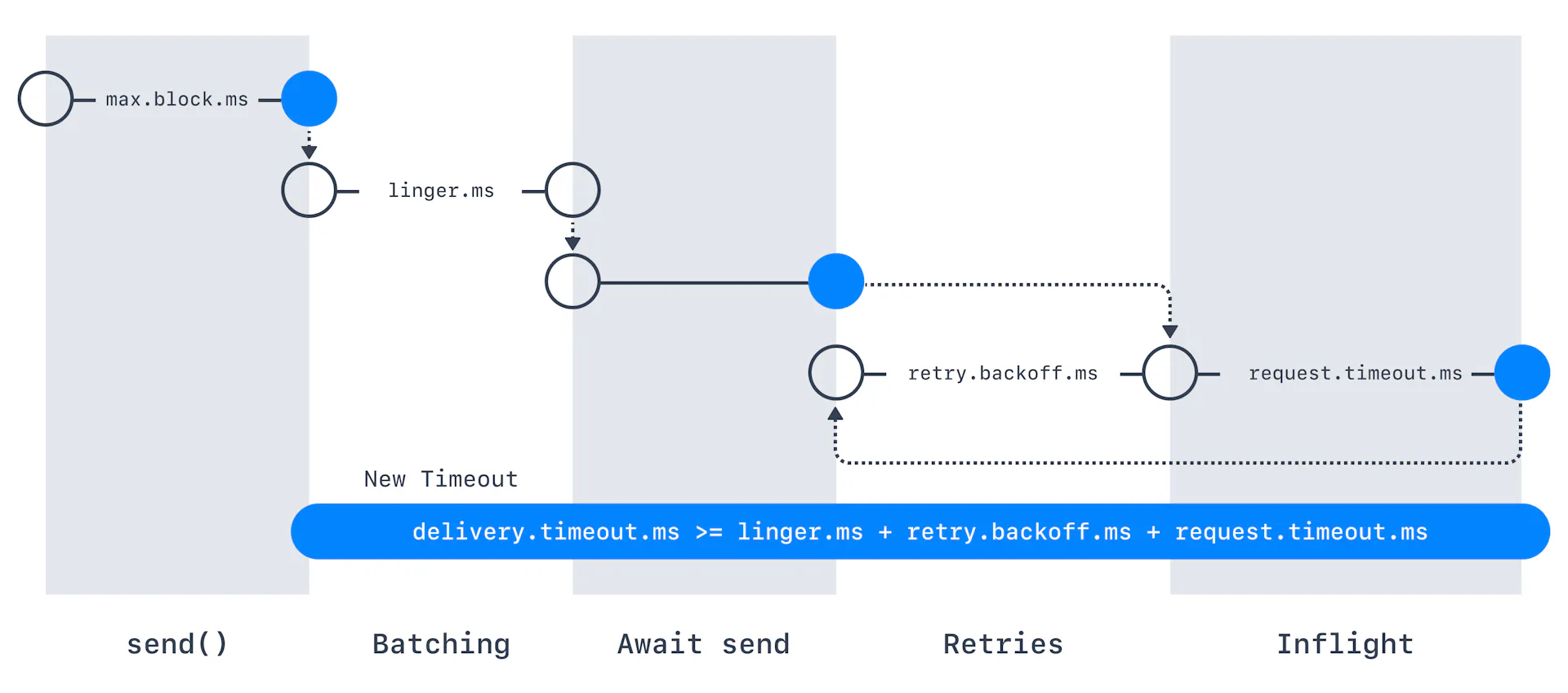
By default, the producer doesn’t resend records if a commit fails. However, the producer can be configured to resend messages “n” a number of times with retries=n. retries basically represent the maximum number of times the producer would retry if the commit fails. The default value is 0.
enable.idempotence
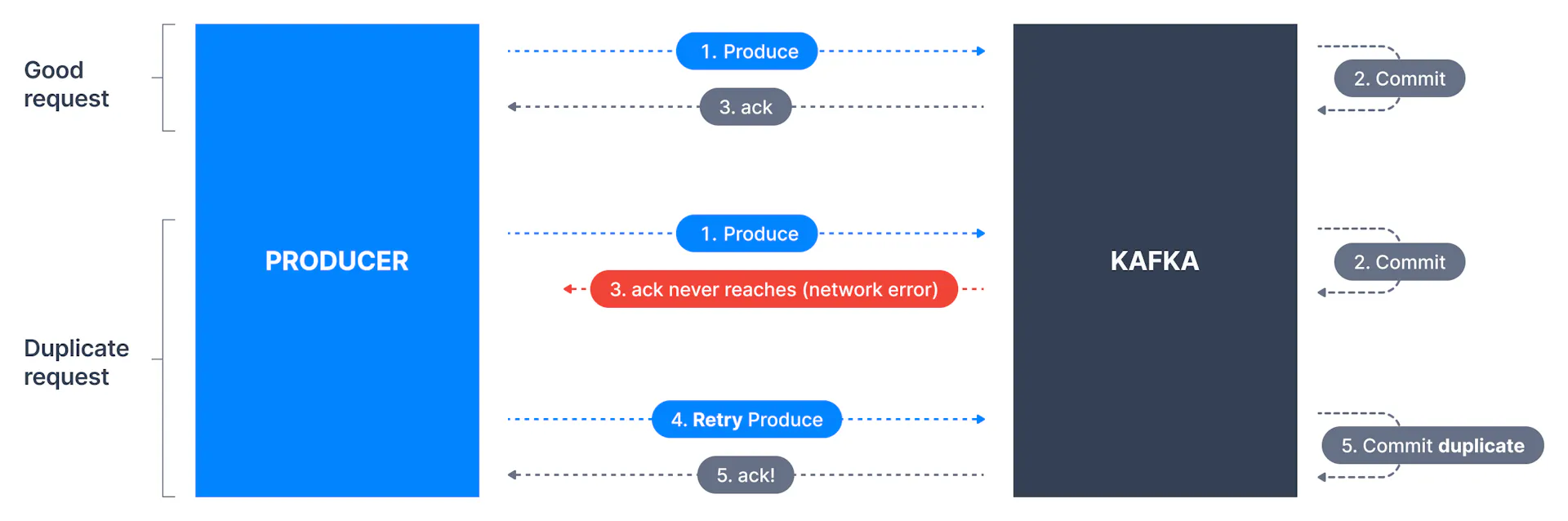
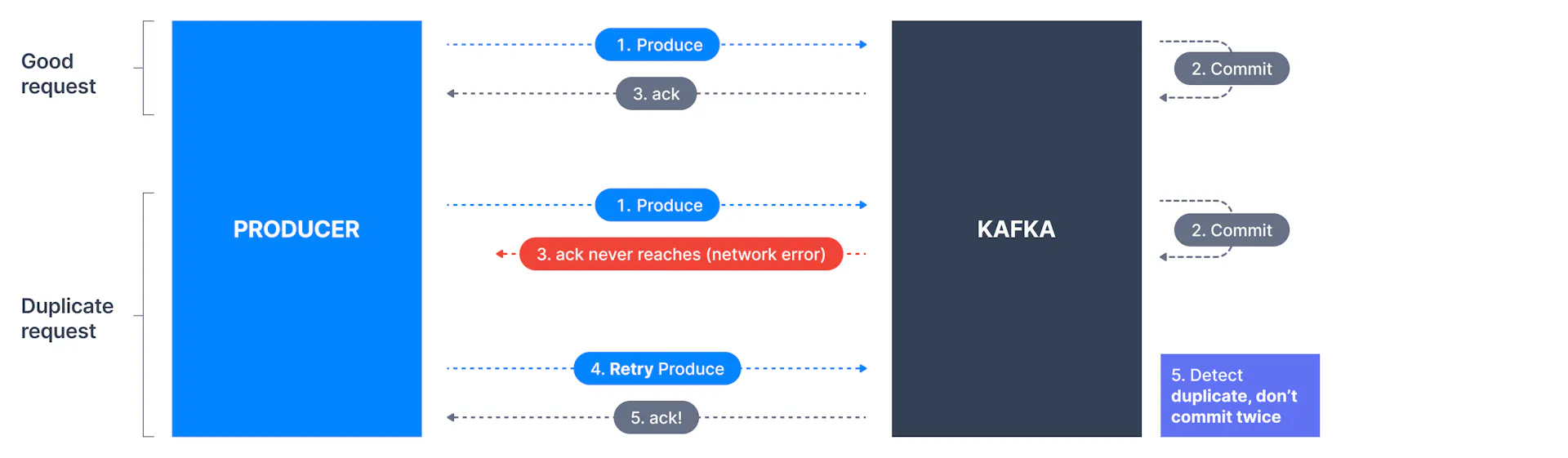
In simple terms, idempotence is the property of certain operations to be applied multiple times without changing the result. When turned on, a producer will make sure that just one copy of a record is being published to the stream. The default value isfalse, meaning a producer may write duplicate copies of a message to the stream. To turn idempotence on, use the below command.
enable.idempotent=truemax.in.flight.requests.per.connection
max.in.flight.requests.per.connection Kafka Producer Config represents the maximum number of unacknowledged requests that the client will send on a single connection before blocking. The default value is 5.
If retries are enabled, and max.in.flight.requests.per.connection is set greater than 1, there lies a risk of message re-ordering.
buffer.memory
buffer.memory represents the total bytes of memory that the producer can use to buffer records waiting to be sent to the server. The default buffer.memory is 32MB. If the producer sends the records faster than they can be delivered to the server, the buffer.memory will be exceeded and the producer will block them for max.block.ms (discussed next), henceforth it will throw an exception. The buffer.memory setting should roughly correspond to the total memory used by the producer.
max.block.ms
max.block.ms basically defines the maximum duration for which the producer will block KafkaProducer.send() and KafkaProducer.partitionsFor(). These methods can be blocked whenever the buffer.memory is exceeded or when the metadata is unavailable.
linger.ms
linger.ms represents the artificial delay time before the batched request of records is ready to be sent. Any records that come in between request transmissions are batched together into a single request by the producer. linger.ms signifies the upper bound on the delay for batching. The default value is 0 which means there will be no delay and the batches will be immediately sent (even if there is only 1 message in the batch).
In some circumstances, the client may increase linger.ms to reduce the number of requests even under moderate load to improve throughput. But this way, more records will be stored in the memory.
batch.size
Whenever multiple records are sent to the same partition, the producer attempts to batch the records together. This way, the performance of both the client and the server can be improved. batch.size represents the maximum size (in bytes) of a single batch.
Small batch size will make batching irrelevant and will reduce throughput, and a very large batch size will lead to memory wastage as a buffer is usually allocated in anticipation of extra records.
compression.type
compression.type signifies the compression type for all data generated by the producer. The default value is none which means there is no compression. You can further set the compression.type to gzip, snappy, or lz4.
Conclusion
- This article introduced you to Kafka and Kafka ProducerConfig.
- You also worked with 10 Kafka Producer Configurations that can make your Kafka producer more durable and resilient.
- However, in businesses, extracting complex data from a diverse set of Data Sources can be a challenging task and this is where Hevo saves the day!
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. How do you configure a Kafka producer?
Configure a Kafka producer by setting properties like bootstrap.servers (Kafka broker address) and serializers (key.serializer, value.serializer). Optionally, set acks and retries.
2. What type of compression is Kafka producer config?
Kafka producers support compression types like gzip, snappy, and lz4, set via the
compression.type property.
3. What is the use of a producer in Kafka?
A Kafka producer sends messages to Kafka topics, enabling real-time data streaming and processing from your application.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



