




Apache Kafka is a distributed publish-subscribe messaging platform explicitly designed to handle real-time streaming data. It helps in distributed streaming, pipelining, and replay of data feeds for quick, scalable workflows. In today’s disruptive tech era, raw data needs to be processed, reprocessed, evaluated, and managed in real-time.
Apache Kafka has proved itself as a great asset when it comes to performing message streaming operations. The main architectural ideas of Kafka were created in response to the rising demand for scalable high-throughput infrastructures that can store, analyze, and reprocess streaming data.
Apart from the publish-subscribe messaging model, Apache Kafka also employs a queueing system to help its customers with enhanced real-time streaming data pipelines and real-time streaming applications.
In this article, we shall learn more about Apache Kafka Queue.
Table of Contents
What is Apache Kafka?

Apache Kafka was created by a team led by Jay Kreps, Jun Rao, and Neha Narkhede at LinkedIn in 2010. The initial goal was to tackle the challenge of low-latency ingestion of massive volumes of event data from the LinkedIn website and infrastructure into a lambda architecture that used Hadoop and real-time event processing technologies. While the transition to “real-time” data processing created a new urgency, there were no solutions available for the same.
There were robust solutions for feeding data into offline batch systems, but they disclosed implementation details to downstream users and employed a push paradigm that might rapidly overload a user. They were also not created with the real-time use case in mind. Kalka’s fault-tolerant architecture is highly scalable and can easily handle billions of events. As a result, Apache Kafka was built to resolve these pain points. At present, it is maintained by Confluent under Apache Software Foundation.
Hevo Data, a No-code Data Pipeline, helps load data from any data source such as databases, SaaS applications, cloud storage, SDK, and streaming services and simplifies the ETL process. It supports 150+ data sources and loads the data onto the desired Data Warehouse like Apache Kafka, enriches the data, and transforms it into an analysis-ready form without writing a single line of code.
Check out why Hevo is the Best:
- Secure: Hevo has a fault-tolerant architecture that ensures that the data is handled in a secure, consistent manner with zero data loss.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Explore Hevo’s features and discover why it is rated 4.3 on G2 and 4.7 on Software Advice for its seamless data integration. Try out the 14-day free trial today to experience hassle-free data integration.
Get Started with Hevo for FreeKey Features of Kafka
Here are Key features of Apache Kafka:
1. Scalability
Apache Kafka supports high-throughput sequential writes and separates topics for highly scalable readings and writes. As a result, Kafka makes it possible for several producers and consumers to read and write at the same time. Additionally, subjects partitioned into many partitions can take advantage of storage across different servers, allowing users to reap the benefits of the combined capability of numerous disks.
2. Reliability
With the Fundamental usage of replication, the Kafka architecture inherently achieves failover. With topics using a defined replication factor, topic partitions are replicated on various Kafka brokers or nodes. When a Kafka broker fails, an ISR takes over the leadership role for its data and continues to provide it effortlessly and without interruption.
3. Log Compaction
Apache Kafka always keeps the latest known value for each record key, thanks to log compaction. It just preserves the most recent version of a record while deleting previous copies with the same key. This aids in data replication across nodes and serves as a re-syncing tool for failing nodes.
4. Fault Tolerance
Apache Kafka is built for resilience, ensuring reliable data processing even in the event of hardware failures or network disruptions. This makes it a dependable choice for critical applications.
5. Scalable Distributed System
Kafka operates as a distributed system, allowing it to run across multiple servers. Its scalability ensures it can handle increasing workloads and support multiple applications seamlessly.
6. Widely Adopted
Trusted by leading organizations like Amazon, LinkedIn, Netflix, Apple, and Microsoft, Kafka has proven its versatility and reliability in handling large-scale data streams.
Understanding the Apache Kafka Architecture
Before you get familiar with the working of a streaming application, you need to understand what qualifies as an event. The event is a unique piece of data that can also be considered a message. For example, when a user registers with the system, the activity triggers an event. This event could include details about the registration, such as the user’s name, email, password, and location.

Apache Kafka acts like a broker to provide communication among producers and consumers in a distributed system. When the producers include web servers and applications and IoT devices send messages to optimize them, they can do this by sending large record batches to Kafka to ensure efficient transmission. A topic consists of partitions that will be distributed across multiple brokers for fault tolerance. These brokers enable consumers to read messages and therefore manage their flow of data, catching up as needed, even when failures occur.
Zookeeper, in a Kafka cluster, will monitor the status of brokers and ensure that there is coordination between the production and consumption. So it’s indeed keeping track of the health of the brokers and manages the metadata of the cluster, meaning that whether the producers or consumers fail they can very easily be switched over to active brokers. For maintaining the communication, each broker will periodically send its heartbeat messages to Zookeeper. In this architecture, Kafka is capable of offering high-throughput messaging with reliability and scalability.
What are Apache Kafka Queues?
In the Apache Kafka Queueing system, messages are saved in a queue fashion. This allows messages in the queue to be ingested by one or more consumers, but one consumer can only consume each message at a time. As soon as a consumer reads a message, it gets removed from the Apache Kafka Queue.
This is in stark contrast to the publish-subscribe system, where messages are persisted in a topic. Here, consumers can subscribe to one or more topics and consume all the messages present in that topic. Although, you can use the publish-subscribe model to convert a topic into a message queue using application logic. Once consumer groups have read an application logic it deletes the messages from the topic.
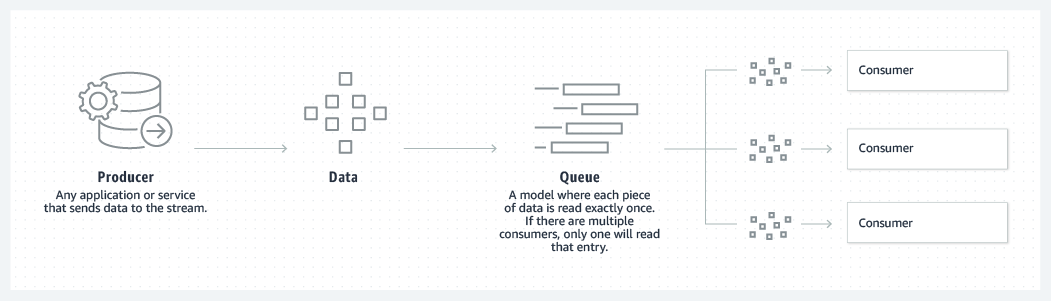
One key advantage is that the Apache Kafka Queue helps in segregating the work so that each consumer receives a unique set of data to process. As a result, there is no overlap, allowing the burden to be divided and horizontally scalable. When a new consumer is added to a queue, Kafka switches to share mode and splits the data between the two. This sharing will continue until the number of customers reaches the number of partitions specified for that topic.
Creating Apache Kafka Queue
To create an Apache Kafka queue, you need these two topics, viz.,
- The Queue topic in the Apache Kafka Queue will contain the messages to be processed.
- The Markers topic in the Apache Kafka Queue contains start and finishes markers for each message. These markers help in tracking messages that need to be redelivered.
Now, to start Apache Kafka Queues, you have to create a standard consumer, and then begin reading messages from the most recently committed offset:
- Read a message from the queue topic to process.
- Send a start marker with the message offset to the marker’s topic and wait for Apache Kafka to acknowledge the transmission.
- Commit the offset of the message read from the queue to Apache Kafka.
- The message may be processed once the marker has been sent and the offset has been committed.
- When (and only if) the processing is complete, you can send an end marker to the ‘markers topic,’ which contains the message offset once more. There is no need to wait for a sent acknowledgment.
You can also start several Redelivery Tracker components, which will consume the markers topic and redeliver messages when appropriate. Redelivery Tracker in this context is an Apache Kafka application that reads data from the markers queue. And it keeps a list of messages that haven’t been processed yet.
Kafka as a Queue
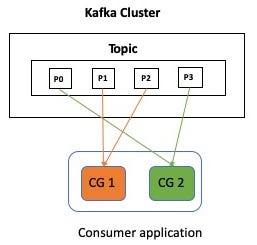
To create an application that consumes data from Kafka, you can write a consumer (client), point it at a topic (or more than one, but for simplicity, let’s just assume a single one), and consume data from it.
If one consumer is unable to keep up with the rate of production, simply start more instances of your consumer (i.e. scale out horizontally) and the workload will be distributed among them.
For fault-tolerance and scalability, a Kafka topic is divided into partitions. In the diagram above, CG1 and CG2 represent Consumer Groups 1 and 2, which consume from a single Kafka topic with four partitions (P0 to P4).
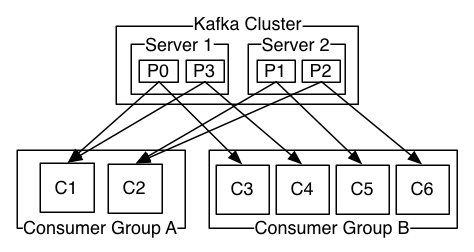
Kafka as a Topic
The key point here is that all applications require access to the same data (i.e. from the same Kafka topic). In the diagram below, Consumer Group A and Consumer Group B are two separate applications that will both receive all of the data from a topic.



Conclusion
In this article, we learned about the Apache Kafka architecture and how it uses an Apache Kafka queueing messaging system. The Apache Kafka Queueing system proves useful when you need messages to be deleted after being viewed by consumer groups. It also enables you to distribute messages across several consumer instances, allowing it to be highly scalable.
Extracting complex data from a diverse set of data sources to perform insightful analysis can be difficult, which is where Hevo comes in! Hevo Data provides a faster way to move data from databases or SaaS applications such as Apache Kafka into your Data Warehouse or a destination of your choice so that it can be visualized in a BI tool. Try a 14-day free trial to explore all features, and check out our unbeatable pricing for the best plan for your needs.
Frequently Asked Questions
1. Can Kafka be used for real-time data processing?
Kafka is a real-time streaming and processing engine; thus, it is a good fit for those use cases in which requirements are for handling log aggregation, event sourcing, and stream processing using tools like Kafka Streams or Apache Flink.
2. Is Apache Kafka scalable?
Yes, Kafka is highly scalable. It can handle large volumes of data by just adding more brokers to a cluster and spreading data across multiple partitions to ensure performance and also fault tolerance.
3. How does Kafka handle message storage?
Kafka stores the message in a distributed log, where it assigns an offset to each message. In this kind of logging it is possible to retrieve messages with high performance; if one desires to achieve this can be made very durable by holding onto them for some configurable period.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link

![Apache Pulsar vs Kafka: Which is Better? [5 Critical Differences]](https://res.cloudinary.com/hevo/images/w_768,h_432,c_scale/f_webp,q_auto:best/v1768127133/hevo-learn-1/Blog-323/Blog-323.png?_i=AA)

